最近由于一些原因,做服务器资源调整,其中一台服务器是做NFS服务,通过NFS挂载到其他几台服务器做共享,服务器内存从8G调整到了4G,其他不变
降配完成后,重启服务器,看着一切正常,就没管了
第二天DBA和我说数据备份没写入,登录服务器查看,df -H命令卡住,凭经验,NFS挂了
登录NFS服务器,查看NFS服务正常,查看message日志,发现大量关于RPC的日志
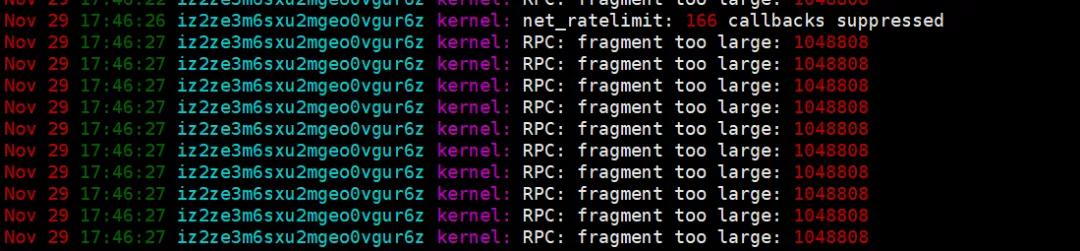
日志报错,分片太大
为什么之前是好的,降内存后,就出现分片太大,无法处理的情况?
通过查找NFS源码,发现如下一段:
- /*
- * To change the maximum rsize and wsize supported by the NFS client, adjust
- * NFS_MAX_FILE_IO_SIZE. 64KB is a typical maximum, but some servers can
- * support a megabyte or more. The default is left at 4096 bytes, which is
- * reasonable for NFS over UDP.
- */
- #define NFS_MAX_FILE_IO_SIZE (1048576U)
- #define NFS_DEF_FILE_IO_SIZE (4096U)
- #define NFS_MIN_FILE_IO_SIZE (1024U)
原来,NFS服务器在决定默认的最大读写块大小时会考虑内存的占用情况,每个NFS内核线程最多只使用1/4096的物理内存大小,对于UDP来说,由于一个UDP包最大才64KB,因此使用UDP协议的NFS读写块大小最大不超过48KB,而kernel中则直接限制为32KB了,而使用TCP协议的NFS由于没有这个限制,允许更大的读写块大小,单Linux kernel还是将其限制为1MB了,对于物理内存超过4GB的机器才使用最大的1MB读写块大小,而记录这个大小的文件为/proc/fs/nfsd/max_block_size
查看服务端该值大小为512KB

因为读写对应的是rsize和wsize,是客户端和服务端协商决定的,所以通过命令
- cat /proc/mounts |grep rsize
查看此时客户端的rsize和wsize

客户端rsize和wsize都是1048567,正好是1M
而上面我们看到服务端是512K,所以两边目前是不协商的
猜测原因如下:NFS服务器内存降配前,原先8G内存,大于4G,所以max_block_size应该是最大值1M,也就是1048567,和客户端协商后,两边都定位默认的1048567
当NFS服务器降配到4G后,由于内存保护及计算,NFS服务端max_block_size降为512KB,也就是524288,此时服务端和客户端不匹配
而客户端没有重新连接服务端,导致未协商,所以客户端分片的数据包,远大于服务端能处理的数据包,也就出现了message中的报错,RPC数据分片太大
知道问题原因,就开始解决,解决方法分两种
- 客户端重新挂载
- 服务端修改max_block_size
我这里选择了第二种方案,直接修改服务端max_block_size,因为是/proc数据,nfs在启动占用,所以需要停掉nfs修改
- systemctl stop nfs
- # 修改max_block_size
- echo 1048567 > /proc/fs/nfsd/max_block_size

修改完成后,重新启动NFS
- systemctl start nfs
查看message,日志正常,查看客户端,df -H可以正常看到挂载目录,进入挂载目录正常
这里我为什么不用第一种方案?
因为此时NFS服务端是挂掉的,客户端无法卸载,卸载会提示占用无法卸载,能卸载的方式是两边都重启,重新后重新进行协商,我不愿意重启客户端服务器,所以选择第二种方式
完成后查看nfs传输
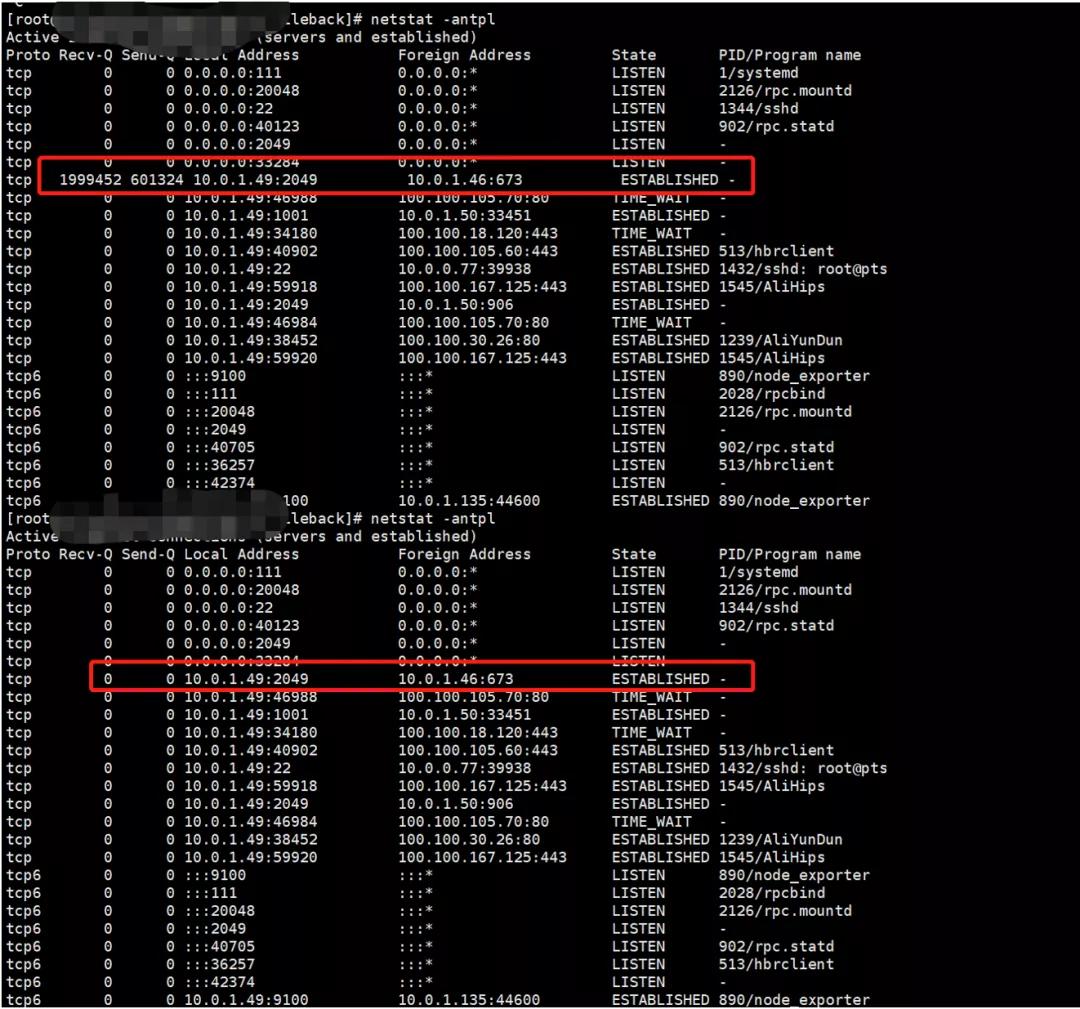
可以看到,传输正常,另外可以看到NFS此时是TCP协议的,也就验证了TCP协议传输时,Linux内核最大限制1M块大小了
本文转载自微信公众号「运维研习社」,可以通过以下二维码关注。转载本文请联系运维研习社公众号。