我们说,要评判一个东西的好坏,一定要说明具体在什么业务场景。脱离业务谈好坏是没有意义的。
Redis 非常强大,我出版过一本书专门介绍 Redis 的各种用法。但这并不是说 Redis 在各种方面都没有对手。至少在分布式系统的配置更新这个场景上面,我认为 etcd 做得更好。
要解释这个问题,我们来看一个具体的业务场景:
在 Redis 中有一个列表 sentence,里面会源源不断地写入字符串。现在我有一个过滤程序:trash_filter.py,它一条一条从 Redis 读取数据,判断字符串中是否有特定的关键词,如果有,那么直接丢弃。如果没有,那么把数据存入 MongoDB。
这个场景非常简单,于是你很快就写出了一个 Python 程序:
import redis
class TrashFilter:
def __init__(self):
self.client = redis.Redis()
self.trash_words = ['垃圾']
def read_data(self):
while True:
data = self.client.lpop('sentence')
if not data:
return
yield data.decode()
def do_filter(self):
for sentence in self.read_data():
for word in self.trash_words:
if word in sentence:
break
else:
self.save_sentence(sentence)
def save_sentence(self, sentence):
print('进行后续保存 sentence 的操作:', sentence)
if __name__ == '__main__':
trash_filter = TrashFilter()
trash_filter.do_filter()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
在上面的代码中,需要过滤的词是以列表的形式直接写到代码里面的。那么问题来了,如果这些过滤词是动态改变的怎么办?每次为了修改这些词,你都需要重启一下这个程序吗?
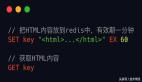
可能有同学提到,可以把这些词存放到数据库里面,每次从数据库里面读取就可以了。Redis 本身就是一个 Key-Value 数据库,可以直接使用 Redis 的字符串来存放:
def do_filter(self):
for sentence in self.read_data():
for word in self.client.get('trash_words').decode().split(','):
if word in sentence:
break
else:
self.save_sentence(sentence)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
把所有的过滤词以英文逗号分割组成长字符串,储存到Redis 中名为trash_words的字符串里。每读取到一个句子,都从 Redis 里面再次读取这个过滤词列表,然后进行检查。
这样做,实时性确实得到了保障,每次只要trash_word字符串一发生修改,程序立刻就能获取到最新的过滤词。
但这样做有一个问题——每次读取trash_words是需要请求网络的,而网络 IO 是非常费时间的。
那么我们是不是可以每5分钟获取一次最新的trash_words呢?当然也可以,我在文章:一日一技:实现有过期时间的LRU缓存中介绍过如何实现一个带有过期时间的 LRU 缓存。
这样做,速度确实提高了,但是实时性又降低了。
如果读者对 Redis 比较熟悉,当然也可以使用 Lua 脚本或者 Redis 的Pipeline 实现在一次请求里面同时获取一条句子并拿到过滤词列表,或者使用 Monitor 命令监控 Key 的变化。但代码写起来会比较复杂。
有没有又快又简单还稳定的解决方案呢?答案是有,那就是使用 etcd.
etcd 的官网写着这样一句话:
A distributed, reliable key-value store for the most critical data of a distributed system.
用于分布式系统最关键数据的分布式、可靠的键值储存。
etcd 本来就是为了分布式系统而生的,它专注于键值储存。初看起来,相当于只是 Redis 的字符串功能,但却比 Redis 的字符串更为强大。
我们可以监控 etcd 中的一个键,当它发生变化的时候,就调用我们提前定义好的函数。
在 Ubuntu 中,可以使用 apt-get 安装 etcd,在 macOS 中,可以使用 homebrew 安装 etcd。当然 etcd 也有已经编译好的可执行文件,可以从Releases · etcd-io/etcd · GitHub[1]下载下来直接运行就能启动一个单节点的 etcd 服务。
启动服务以后,我们再来安装一个Python 库,用来操作 etcd:
pip install etcd3
- 1.
Python 读写 etcd 非常简单:
import etcd3
client = etcd3.client()
client.put('key', value) # 添加数据
value, kv_meta = client.get('key') # 读取数据,返回的数据value 是 bytes 型数据
- 1.
- 2.
- 3.
- 4.
- 5.
而我们要用的,是 etcd 的watch功能。我们先写一段简单的代码来说明 watch的功能:
import etcd3
import time
def callback(response):
for event in response.events:
print(f'Key: {event.key}发生改变!新的值是:{event.value}')
client = etcd3.client()
client.add_watch_callback('test', callback)
for i in range(100):
print(i)
time.sleep(1)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
正常情况下,这个程序会打印从0到99,每秒打印一个数字。但是当我们中途修改了 etcd 中,名为test这个 key 的值以后,我们发现回调函数被运行了,如下图所示:
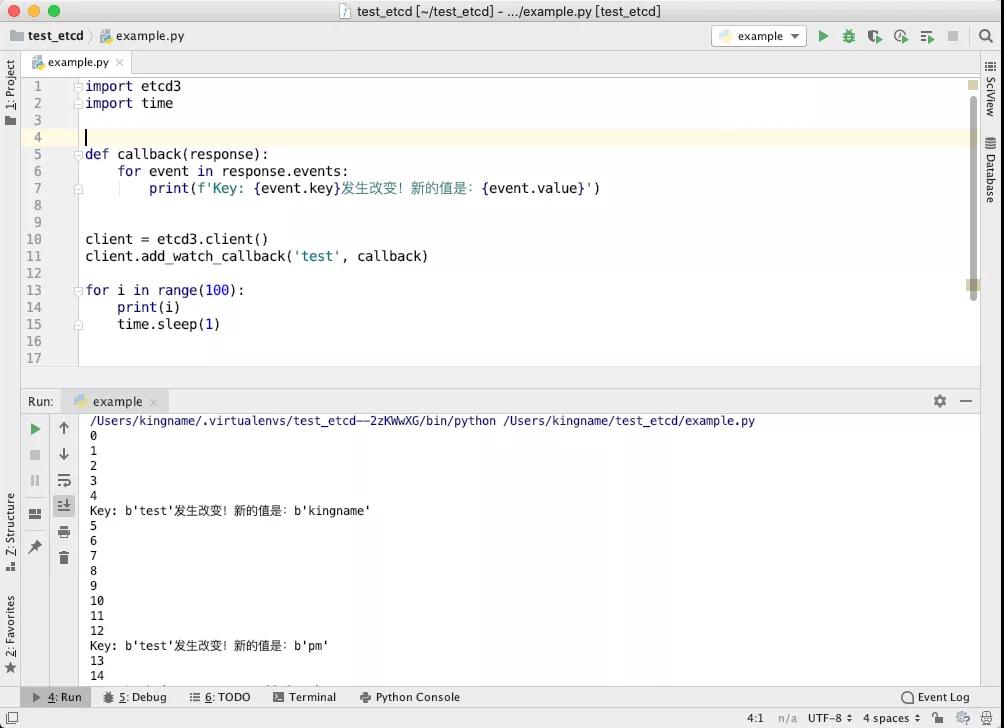
可以看到,etcd 监控一个 key 是否变化,它不像 Redis 的blpop这样阻塞式地监控,而是在后台监控,当key 的值发生了改变时,触发一个事件,调用回调函数。所以整个监控的过程不会干预我们自己程序的正常运行。
在一般情况下,传入回调函数的response 对象,它的.events属性是只有一个元素的列表。但如果这个 key 在极短时间内变化了很多次,那么这个列表里面可能有多个值。
回到最开始需要解决的问题,我们引入 etcd 以后,困难轻轻松松就被解决了:
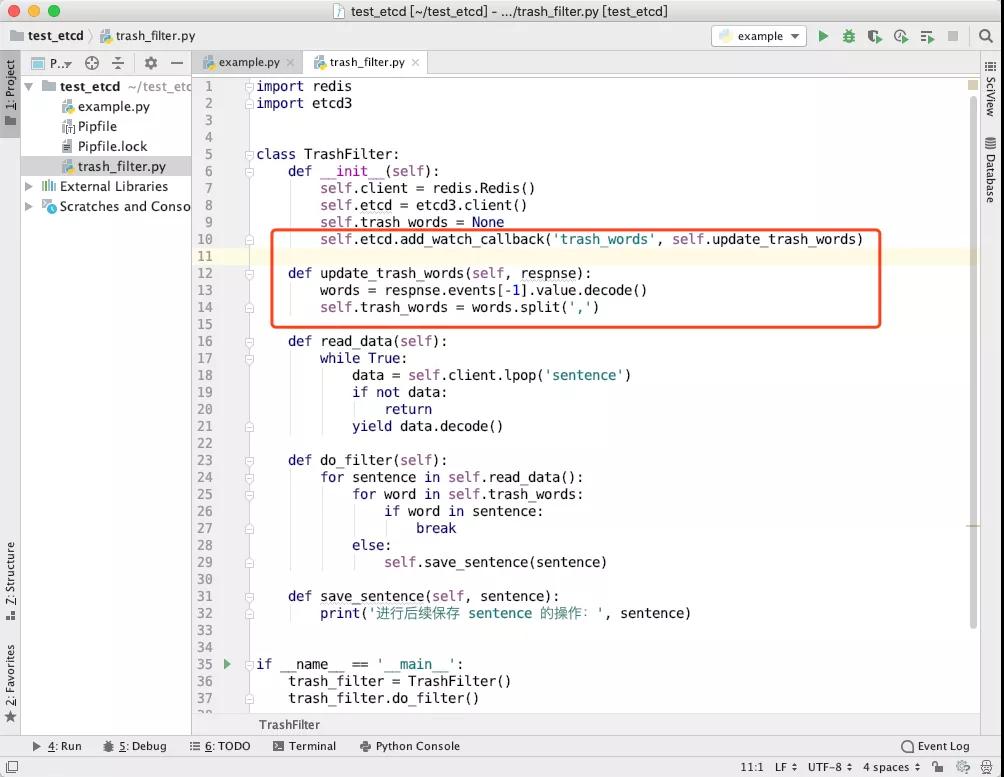
通过增加方框框住的update_trash_words方法,并把它作为监控trash_words这个Key 变化事件的回调函数,一旦这个 Key 发生了变化,就会调用回调函数,从而更新self.trash_words这个属性。
运行效果如下图所示:
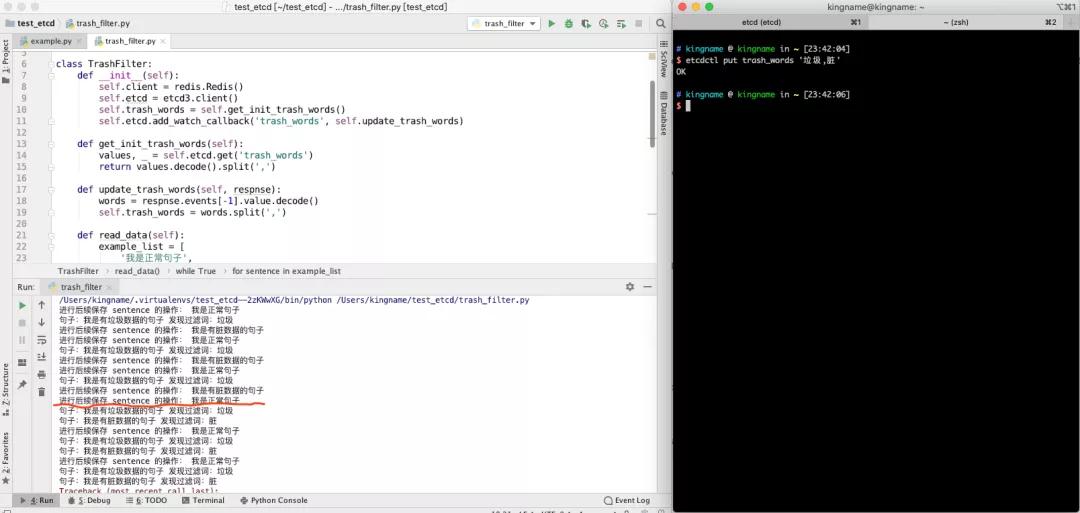
可以看到,在红线上面,我是有脏数据的句子是不被过滤的,此时脏字也不是过滤词。但是当我们在命令行里面更新了 etcd,把新的过滤词改成垃圾,脏以后,就到了红线下面,我是有脏数据的句子就会被过滤了。
这样就做到了同时兼顾时效性和速度,避免了无效的网络请求。
参考文献
[1] Releases · etcd-io/etcd · GitHub: https://github.com/etcd-io/etcd/releases
本文转载自微信公众号「未闻Code」,可以通过以下二维码关注。转载本文请联系未闻Code公众号。