动态视觉推理(Dynamic Visual Reasoning),尤其是涉及到物体间物理关系的推理,是计算机视觉中一个重要且困难的问题。给定一个观测视频,它不仅要求模型根据视频推理出视频中物体的交互过程,还要求对视频的长期未来(Long-term)以及反事实(Counterfactual)情形进行预测,而这两项预测恰好是现有神经网络模型的弱点。
现有方法可以大致被分为两类:使用端到端神经网络(如 Vision Transformer)来对物体间关系进行建模的方法 [3],和基于神经符号(Neuro-Symbolic)的推理模型 [2, 4];前者受益于 Transformer 等的强大表征有着不错的性能,但是其依赖大量数据,且推理过程不透明且难以解释;而后者基于神经符号逐步进行推理,模型具有良好的解释性,但是精度受限;此外,现有方案都难以解决长期和反事实预测的难题。
本文提出的基于可微物理模型的神经符号推理框架很好的解决了这个问题,它通过从视频和问题对中学习物理模型,并利用显式的物理模型对物体动力学进行建模,基于准确的动力学预测来回答长期和反事实预测问题。本文的框架透明可解释,并在精度上超过了基于 Transformer 的模型。此外,它显示了良好的数据效率,在只使用 20% 甚至更少的数据即可取得不错的效果。本文作者来自香港大学 (HKU),麻省理工大学 (MIT) 和 MIT-IBM 沃森人工智能实验室,论文已被 NeurIPS 2021 接收。

图 1. [NeurIPS 2021] VRDP 作者介绍
- 项目主页:http://vrdp.csail.mit.edu/
- 论文链接:http://vrdp.csail.mit.edu/assets/NeurIPS21_VRDP/vrdp.pdf
- 代码链接:https://github.com/dingmyu/NCP
背景和数据介绍
本文使用最多的数据集是 CLEVRER 数据集 [2]。如下图所示,它使用简化的物体(圆球,圆柱,正方体等)来学习动力学相关的推理问题:1. 发生了什么 ?(Descriptive question); 2. 为什么发生?(Explanatory question); 3. 将会发生什么?(Predictive question); 4. 如果… 会发生什么 (Counterfactual question)。人类可以比较轻松地利用物理直觉和常识来推断这些问题,然而这对于机器来说就有些困难了,尤其是 Counterfactual 的问题,例如,假设没有黄色的金属圆柱,会是怎样的情形?这很考验物理建模和空间想象的能力。即使基于 Transformer 的模型可以很好的解决 Descriptive 和 Explanatory 问题,它们也总是会在 Counterfactual 的情形中失败。

图 2. CLEVRER 推理数据集示例
方法介绍
本文作者发现,现有方案的弊端是没有显式的使用物理模型,而是过于依赖神经网络或 GNN 的隐式推理,这导致他们在长期预测和反事实推理中无法很好的捕捉视频中的逻辑。基于此,作者引入了一个可微的物理引擎,并通过从视频中捕捉到的物体轨迹和属性来还原视频中物体和场景的物理参数(速度,加速度,质量,弹性系数,摩擦力等)。一旦所有的相对物理参数被推理出来,即得到了显式的物理模型后,作者使用物理模型进行基于预测的和反事实的物理模拟,并根据模拟后的轨迹和特征来回答相关问题。具体流程如下图所示。
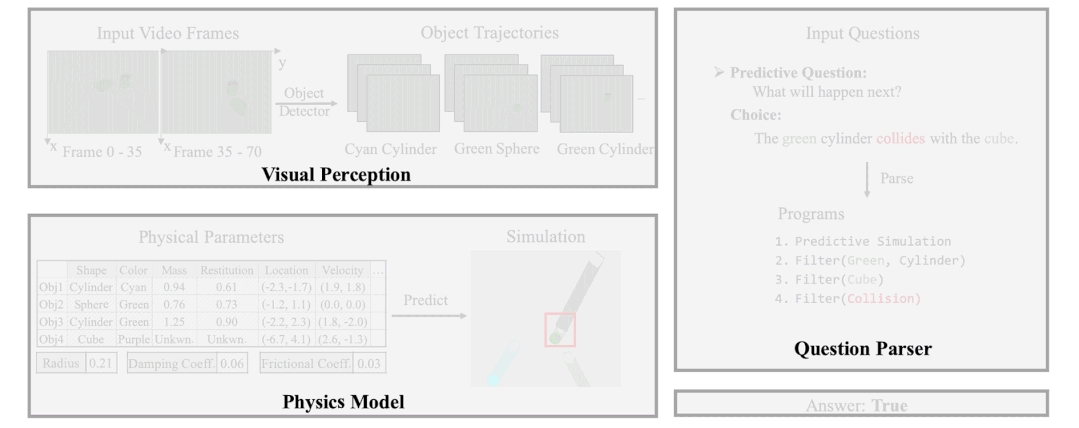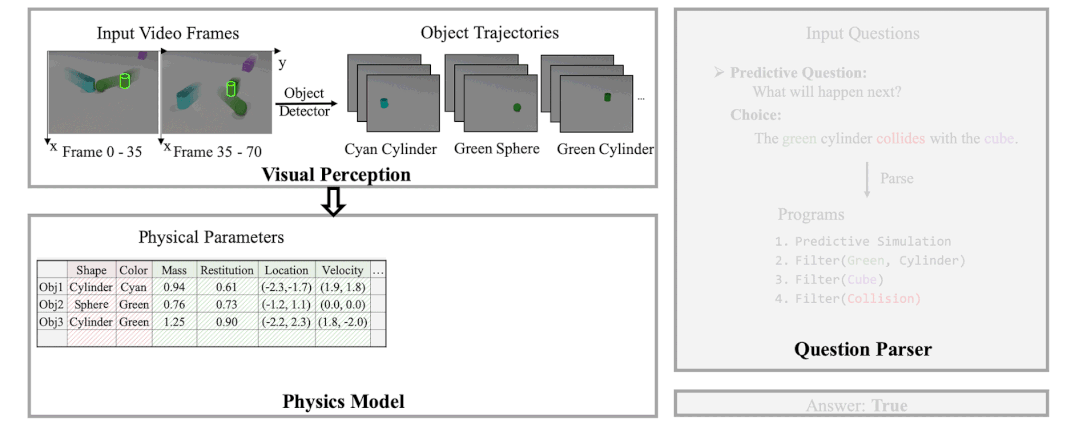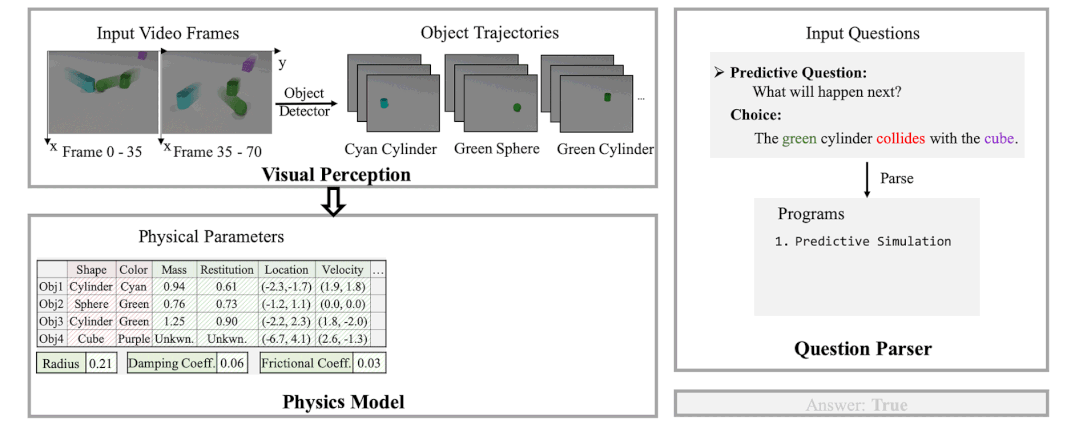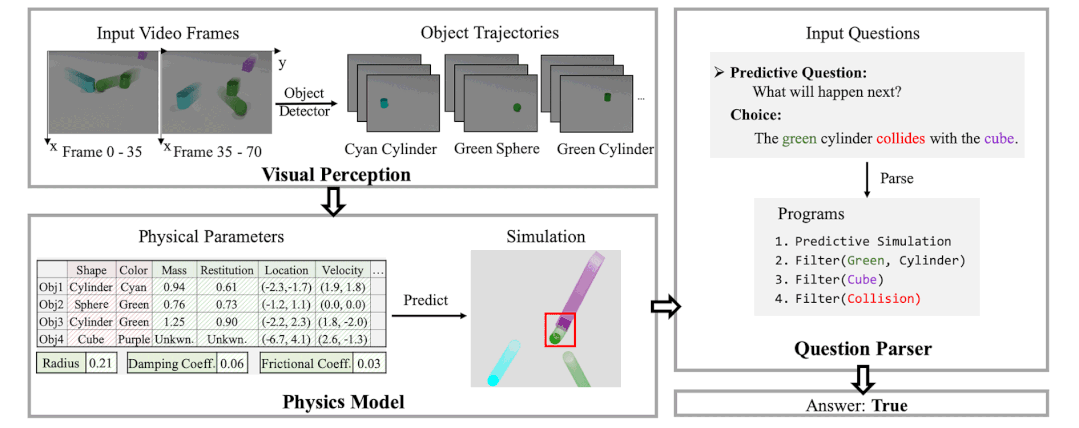
图 3. 基于物理模型的推理示例。(1)使用一个感知模块从视频中获取每个物体及其对应的轨迹和属性;(2)利用上述视频观测通过可微物理模拟来学习相关物理参数;(3)通过物理模拟进行预测并回答相关问题。
然而上述框架仍然存在一个难点,现实世界中往往没有对物体的属性标注,在这种情况下,难以通过一个感知模块得到物体的相关属性(如颜色,形状),而没有这些先验信息就无法进行可微物理模拟,更无法学到一个准确的物理模型。因此,作者提出 VRDP 框架,将视觉感知模块、概念学习器和物理模型结合,使用三个无缝衔接的模块来解决上述问题。其中,视觉感知模块用于对每帧图片进行分割,得到每个物体和对应的轨迹;概念学习器负责从物体的轨迹信息和问题对中学习物体的属性;在物体的轨迹和属性都得到后,通过可微物理模拟学到较为准确的物理模型;基于物理模型完成长时和反直觉的推理。整体框架如下:
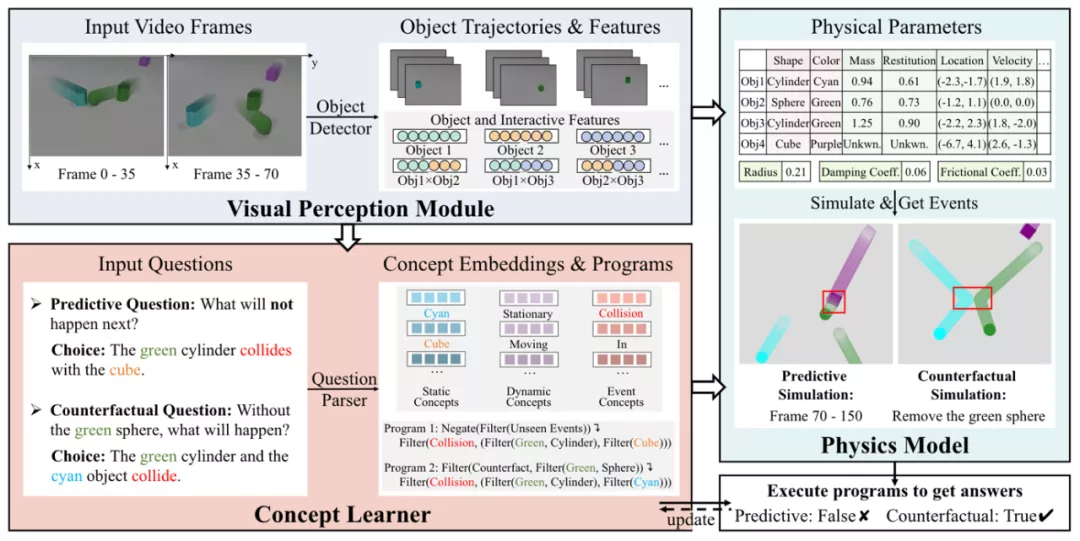
图 4. VRDP 框架。由三部分组成:视觉感知模块、概念学习器和可微物理模型
具体来说,框架中的物理引擎为一个基于动量和动能守恒的碰撞模型,它从单个视频轨迹中估计物体的实时速度和加速度,并以此估计场景的摩擦力等参数。此外,它通过碰撞事件来估计碰撞物体的相对质量和弹性系数,一旦这些参数学习完成,它便可以自由地进行各种模拟和推理。本文的概念学习器为问题中的每个概念词分配一个编码(embedding),并从视频轨迹中学习物体感知的特征,通过讲视觉特征和语义编码投影到同一空间下并检索来得到每个物体对应的属性,参考 NS-CL [1]。如下图所示。
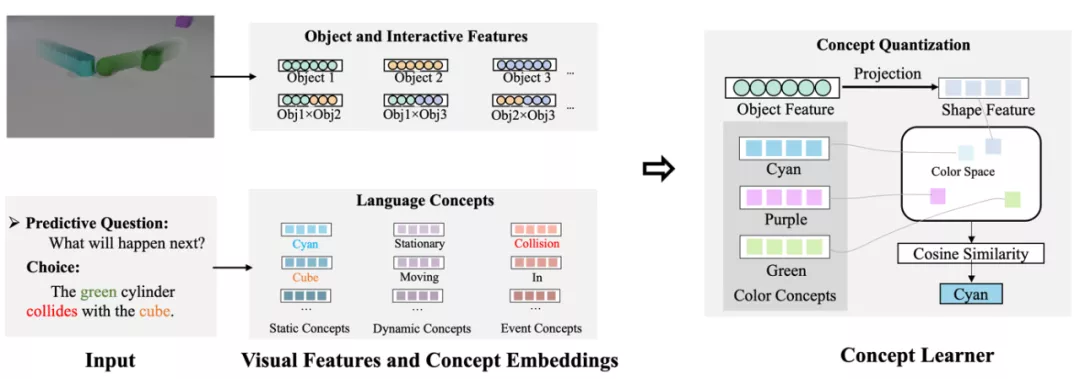
图 5. 概念学习器
本文的神经符号执行器利用了 NS-DR [2] 和 DCL [4] 中的方案,通过预测出的物体轨迹和碰撞事件进行显式的符号推理,如 filter(Green) 代表得到所有的绿色物体,filter(Collision, filter(Green), filter(Cube)) 则代表找出绿色物体和方块的碰撞事件。通过显式的物理模型以及神经符号执行器,本文框架的每一步都是可解释且完全透明的,整个推理过程和人类的逐步推理类似。
Demo 展示

图 6. 物理模拟示例,左侧为原视频,右侧为模拟结果

图 7. 预测问题推理示例

图 8. 反事实问题推理示例
实验部分
本文提出的 VRDP 框架具有优越的性能,在全部 CLEVRER 数据集上测试,它在更加困难的 Predictive 和 Counterfactual 两类问题上都取得了最高的性能,在 Descriptive 和 Explanatory 问题上也得到了有竞争力的结果,如下表所示。
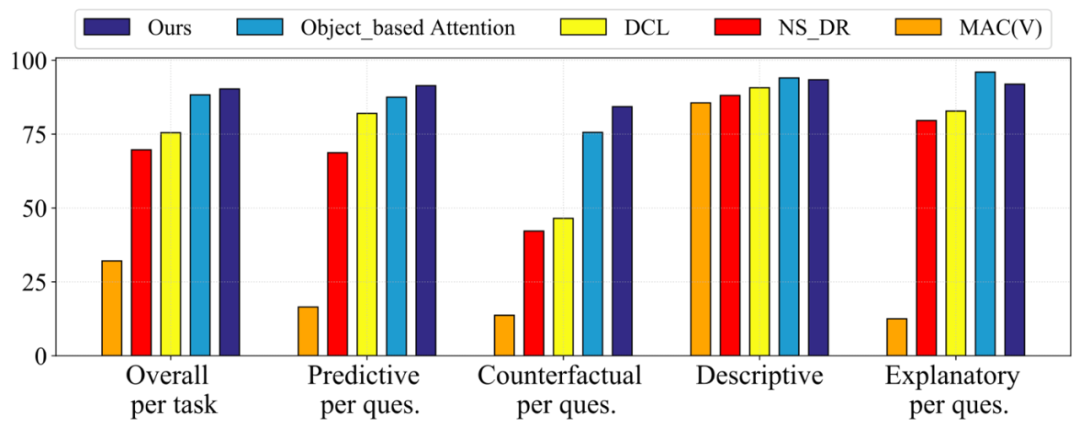
图 9. 实验结果(全部数据)
此外,它具有极高的数据利用效率,仅使用 20% 的数据就可以得到相当不错的结果,远超现有的其他方案,如下图所示。
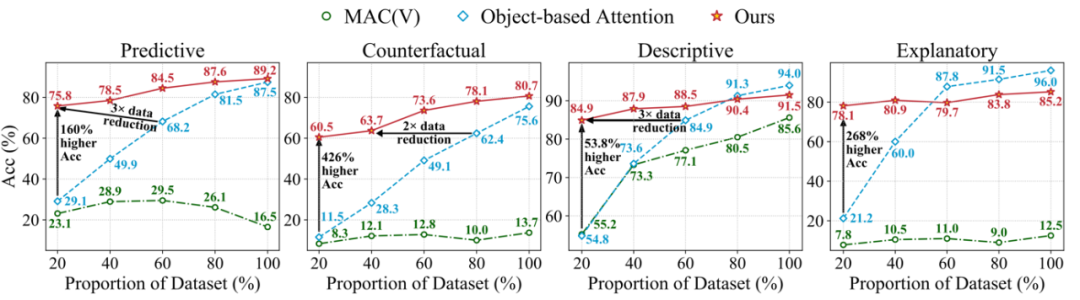
图 10. 数据效率评估(部分数据)
作者还证明了,通过使用可微物理模型,VRDP 可以轻易扩展到数据集中不存在的新的概念中,如概念 “更重”,VRDP 成功进行物理模拟并准确预测了当蓝色圆柱更重时的情况,这是更加复杂的反事实情形。

图 11. 扩展到新的反事实概念 “更重”