本文转载自微信公众号「匠心独运维妙维效」,作者侯强。转载本文请联系匠心独运维妙维效公众号。
数据业务现状
随着业务数据量越来越大、数据任务越来越多以及数据计算类型越来越丰富,G行的原有以Hadoop、MPP为核心的数据平台现有组件表现出了一定的局限性。例如:大数据平台和数据仓库上任务总量已经达到了3万以上,而且还在急剧增长。由于数据存放在了不同数据源中,对于需要对多种数据源的查询任务,首先要进行数据迁移操作,汇总到MPP或Hadoop后进行查询操作,这一过程耗时费力,已经很难满足用户快捷数据查询的需求。
而数据平台建设的一个重要目标就是满足用户方便快捷的使用数据,用户不需要关心数据的存放方式,能够使用标准的数据调用接口,随时使用自己关心的数据。为满足对上述的多数据源无差别的查询,使用远端数据完成交互式查询,G行选择的方式是Presto。
Presto提供丰富的Connector,通过Connector机制可以将所连接的数据SQL化。Presto的Connector可以连接传统的RDBMS数据库,也可以连接HBase、Hive等大数据的开源软件,还可以使用FileConnector连接本地文件。有了Connector,可以直接在Presto的客户端发起查询请求,通过Presto解析查询语句对不同的数据源发起数据查询。通过Connector的方式,避免了数据搬移,节省了大量的数据存储空间,也避免了时间消耗。这个场景非常适合数据科学家对多种数据分析的需求。
Presto架构特点
执行效率方面,Presto是一个开源的基于内存的分布式SQL查询的执行引擎,可以支持TB到PB级数据量的秒级到分钟级的快速响应。在查询效率方面,比MapReduce的查询引擎有很大的提升。
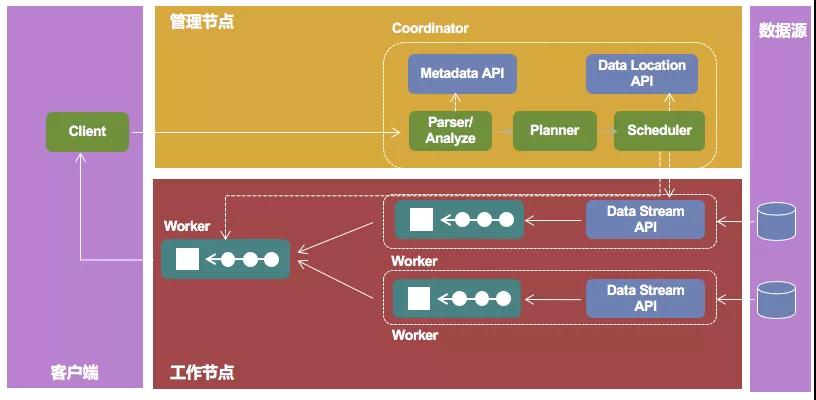
Presto查询引擎是一个Master-Slave的架构,由一个Coordinator节点,多个Worker节点组成。Coordinator负责解析SQL语句,生成执行计划,Coordinator将一个完整的Query,拆分成了多个Stage,每个Stage拆分出多个可以并行的Task,分发执行任务给Worker节点执行。
Worker节点负责实际执行查询Task。通过配置外部数据源的Connector,部分Task负责到外部存储系统拉取数据,这部分Task会先执行,之后再执行那些负责计算的Task。Worker节点的数量影响到Presto执行效率,可以通过增加worker节点的数量,提升数据查询的的效率。而Coordinator在Presto只有一个,需要使用高可用的部署方法,进行灾备保护。
Presto是一个原生的计算和存储分离的分布式的SQL框架。Presto负责SQL的解析和执行,数据本身都由外部数据源进行存储和维护。这种存储和计算分离的架构,在进行资源扩容时可以分别对存储资源和计算资源进行单独扩容,非常符合当今云计算的架构和发展方向。在设备选型时,可以针对IO密集型和CPU密集型采购不同的设备来满足需求。
Presto提供了丰富的Connector,可以连接多种流行的数据源,比如MySql、Hive、Elasticsearch等。同时Presto还提供了API接口,开发人员可以根据自己的实际情况开发自己的应用接口。例如openlookeng,这个软件提供了高斯数据库的访问接口,可以完成Hive和高斯数据库之间的跨数据源的联合查询。
Presto存在的问题
Presto是一个完全基于内存的SQL计算框架,在运行过程中采用高并发的查询方式。当处理数据过于庞大、SQL需要的内存超出了物理服务器承受能力时,会出现内存溢出。如果需要稳定运行长时间的任务,可以使用Hive的SQL引擎。此外,由于Presto在设计初始,就是为了OLAP业务而进行开发,Presto虽然支持delete和insert,但内部结构不适合频繁的数据修改操作。
Presto未来发展
许多企业在大数据建设道路上都产生了相类似的多数据源汇总查询的问题,数据分布在多种数据产品中,各种数据产品之间没有直接交互的方法,需要通过数据迁移完成数据分析工作。而Presto的出现,解决了多数企业面临的问题。G行的即席查询系统正是以Presto技术为核心构建的。随着Presto应用范围的扩大,稳定性将随之不断的改善,相信会给各个企业在数据业务方面带来更多的便利性。