













【51CTO.com快译】从Go到星际争霸再到Dota,很多人工智能研究人员正在致力创建强化学习(RL)系统,希望人工智能能够在复杂的游戏中击败人类。但人工智能面临的更大挑战是创建可以与人类合作而不是竞争的系统。
DeepMind公司的人工智能研究人员开发了一种新技术,以提高DL代理与不同技能水平的人类合作的能力。该技术在2020年度NeurIPS会议上推出,其名称为Fictitious Co-Play(FCP),它不需要人工生成的数据来训练强化DL代理。
在使用解谜游戏Overcooked进行测试时,FCP创建了DL代理,在与人类玩家合作时可以提供更好的结果并减少混乱。这种技术为人工智能系统的未来研究提供重要方向。
训练DL代理
强化学习(RL)可以不知疲倦地学习任何具有明确奖励、动作和状态的任务。如果有足够的计算能力和时间,DL代理可以利用其环境学习一系列动作或“策略”,从而最大化其奖励。事实证明,DL在玩游戏时非常有效。
但通常情况下,DL代理学习的策略与人类玩法不兼容。当与人类合作时,它们执行的操作会让人们感到困惑,这使得它们难以在需要人类共同规划和分工的应用中使用。弥合人工智能与人类之间的差距已成为人工智能社区的重要挑战。
研究人员正在寻找方法来创建能够适应各种合作伙伴(包括其他DL代理和人类)习惯的多功能DL代理。
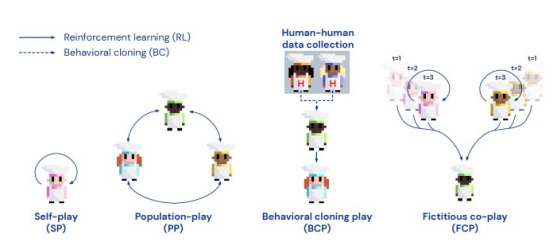
训练DL代理的不同方法
为游戏训练DL代理的传统方法是自我对弈(SP),其中DL代理不断地与自己的副本对战。自我对弈(SP) 可以非常有效地快速学习策略,使游戏的回报最大化,但由此产生的DL模型过度拟合了自己的游戏玩法,而与以不同方式训练的成员合作的结果是很糟糕的。
另一种训练方法是群体游戏(PP),它训练DL代理以及具有不同参数和架构的各种合作伙伴。群体游戏(PP)代理在竞技游戏中与人类合作的效果比自我对弈(SP)要好得多。但它们仍然缺乏共同回报设置所需的多样性,在这种情况下,玩家必须共同解决问题并根据环境的变化协调他们的策略。
另一种选择是行为克隆游戏(BCP),它使用人工生成的数据来训练DL代理。BCP模型不是从随机探索环境开始,而是根据从人类游戏中收集的数据来调整参数。这些代理开发的行为更接近于人类发现的游戏模式。如果数据是从具有不同技能水平和游戏风格的不同用户中收集的,DL代理可以更灵活地适应合作伙伴的行为。因此,它们更有可能与人类玩家兼容。然而,生成人类数据具有挑战性,特别是因为DL模型通常需要大量练习能达到最佳设置的情况下。
FCP
DeepMind公司新推出的DL技术FCP的主要思想是创建代理,可以帮助具有不同风格和技能水平的玩家,而无需依赖人工生成的数据。
FCP培训分两个阶段进行:在第二阶段,DeepMind的研究人员创建了一组自我对弈DL代理。这种代理是独立训练的,并且具有不同的初始条件。因此它们会集中在不同的参数设置上,并创建一个多样化的DL代理池。为了使代理池的技能水平多样化,研究人员在训练过程的不同阶段保存了每个代理的快照。
研究人员在论文中指出,“最后一个检查点代表一个训练有素的‘熟练’伙伴,而较早的检查点代表不太熟练的伙伴。值得注意的是,通过为每个合作伙伴使用多个检查点,这种额外的技能多样性不会导致额外的培训成本。”
在第二阶段,以代理池中的所有代理作为其合作伙伴训练新的DL模型。这样,新代理必须调整其策略才能与具有不同参数值和技能水平的合作伙伴合作。DeepMind公司的研究人员写道:“FCP代理将跟随人类伙伴的脚步,并学习一系列策略和技能的通用策略。
测试FCP
DeepMind公司的人工智能研究人员将FCP应用于Overcooked,这是一款解谜游戏,玩家必须在网格世界中移动,与其他玩家互动,并执行一系列步骤来进行烹饪和送餐。Overcooked游戏很有趣,因为它具有非常简单的动态,但同时需要队友之间的协调和劳动力分配。
为了测试FCP,DeepMind公司简化了Overcooked以包含在整个游戏中执行的任务的子集。人工智能研究人员还包括一系列精心挑选的地图,这些地图提出了各种挑战,例如强制协调和狭窄的空间。
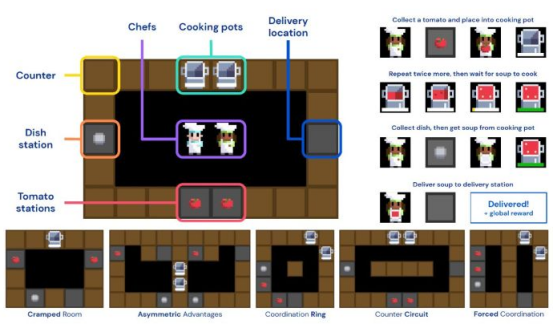
DeepMind使用简化版的Overcooked来测试DL与FCP
研究人员训练了一组SP、PP、BCP和FCP代理。为了比较他们的表现,他们首先针对三组玩家测试了每种DL代理类型,其中包括一个基于人类游戏数据训练的行为克隆(BC)模型、一组在不同技能水平上训练的SP代理,以及代表低技能的随机初始化代理。他们根据在相同数量的回合中提供的食数物量来衡量表现。
他们的研究结果表明,FCP的表现明显优于所有其他类型的DL代理,这表明它在各种技能水平和游戏风格中都能很好地概括。此外,令人惊讶的发现之一是其他训练方法非常脆弱。研究人员写道:“这表明,他们可能无法与技术水平不高的代理合作。”
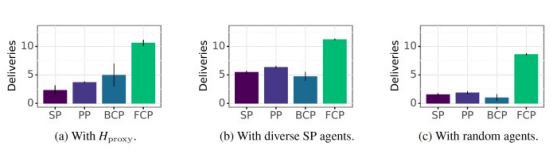
FCP优于其他训练DL代理的方法
然后,他们测试了每种类型的RL代理与人类玩家合作时的表现。研究人员对114名人类玩家进行了一项在线研究,每人都玩了20个回合。在每一回合中,玩家都被放置在一个随机的厨房中,并在不知道是哪种类型的情况下与其中一个RL玩家组队。
根据DeepMind的实验结果,人类与FCP的组合表现优于所有其他类型的RL代理。
在每两个回合之后,参与者以1~5的分数对他们与RL代理的体验进行评分。参与者对FCP的偏好明显高于其他代理,他们的反馈表明FCP的行为更加连贯、可预测和适应性强。例如,RL代理似乎知道其队友的行为,并通过在每个烹饪环境中选择特定角色来防止混淆。
另一方面,调查参与者将其他DL代理的行为描述为“混乱且难以适应”。

DeepMind将人类玩家与不同的DL代理进行组合
还有更多的工作要做
研究人员在论文中指出了他们工作的一些局限性。例如,FCP代理接受了32个DL合作伙伴的训练,这对于Overcooked的淡化版本已经足够了,但对于更复杂的环境可能会受到限制。DeepMind公司的研究人员写道:“对于更复杂的游戏,FCP可能需要一个不切实际的庞大合作伙伴群体规模来代表足够多样化的策略。”
奖励的定义是另一个限制FCP在复杂领域使用的挑战。在Overcooked中,其奖励简单而明确。在其他环境中,RL代理必须完成子目标,直到获得主要奖励。他们实现子目标的方式需要与人类玩家的方式兼容,这在没有人类玩家数据的情况下很难评估和调整。研究人员写道:“如果一项任务的奖励功能与人类处理任务的方式不一致,那么这种方法很可能会产生低于标准的DL代理,就像任何无法访问人类数据的方法一样。”
DeepMind公司的研究是人类与人工智能协作的更广泛研究的一部分。麻省理工学院科学家最近的一项研究探索了DL代理在与人类玩Hanabi纸牌游戏时的局限性。
DeepMind公司新推出的DL技术是弥合人类和人工智能问题解决之间差距的重要一步,而研究人员希望为研究人机协作造福未来社会奠定坚实的基础。
原文标题:DeepMind RL method promises better co-op between AI and humans,作者:Ben Dickson
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】





















