互联网的系统常常面临庞大的用户群体,意味着系统需要时刻面临着大量高并发请求,海量的数据存储等问题的挑战,在解决这些问题的同时还要保证系统的高可用性。同时互联网行业更新迭代快,很多互联网巨头的发展初始阶段,为了快速把产品上线发布以占据用户流量,会以最简单的应用架构形态对系统进行部署,不会过多地考虑未来的应用架构的发展,所以很多互联网公司发展到一定规模,都会进行相应的架构重构与改进,以便适应业务的发展。
我这几年经历过很多家公司,从几个开发人员的小公司到拥有 10+ 亿用户规模的公司都经历过,因此我对互联网公司的系统应用架构的演进有着一些深刻的感悟。
单点应用
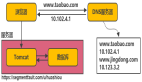
公司发展初期,由于用户量少,系统的并发请求并不高,且数据量少,往往只需要将应用单点部署即可满足业务的需求:
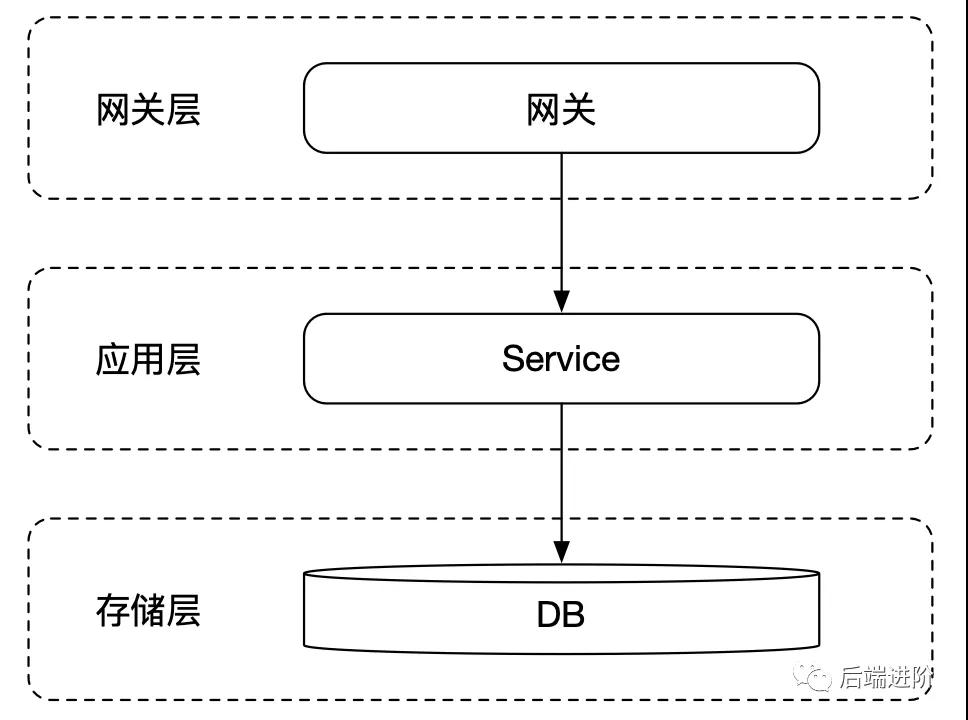
以上就是一个典型的早期互联网应用的架构模式,应用只需要部署在单台服务器上,甚至数据库都放在同一台服务器,流量直上直下,一杆子到底。
由于应用和数据库都是单体形式,所以缺点明显,不能进行故障转移,一旦应用或者数据库其中之一遇到故障,则整个系统不可用。
应用 SOA 化
1、水平拆分
单体应用缺乏故障转移,同时随着请求数量的增多,单体应用部署的请求处理不过来了,常见的问题是应用连接数被打满,用户的请求超时,而且响应耗时长。
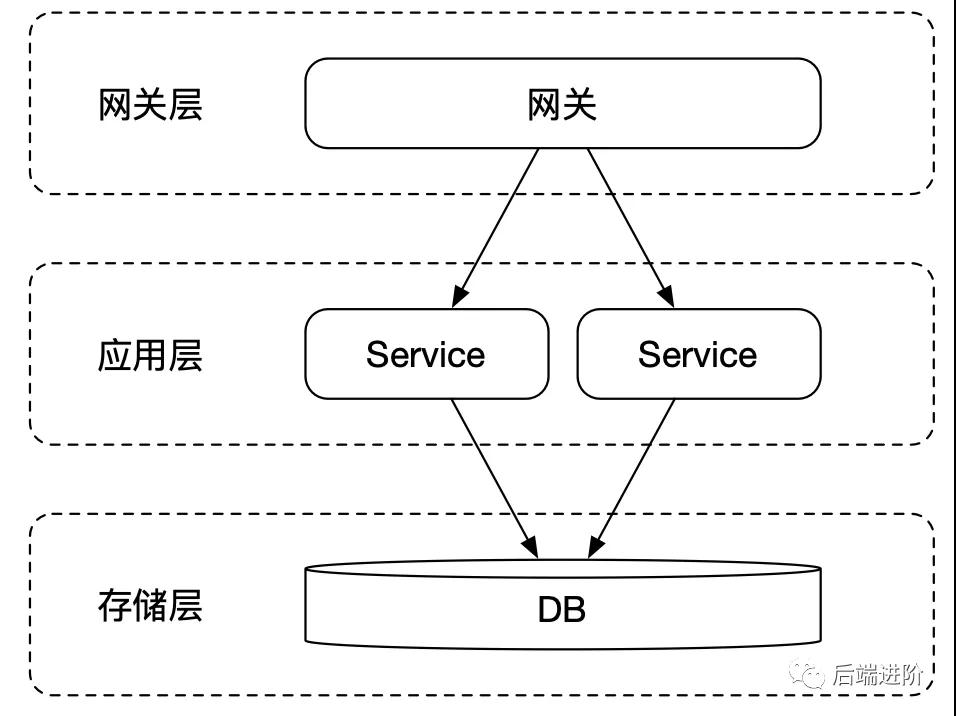
如上图所示,将系统进行水平化拆分,部署多个应用实例,同时网关将流量进行平均分配,有效减少单个应用的请求压力,同时应用服务具备故障转移,当服务遇到故障,只要还保持着一个以上应用实例,系统就能够运转(还需要考虑降级处理)。
这是初级的应用 SOA 化阶段。
2、垂直拆分
随着公司业务的高速发展,业务的体量越来越大,一个应用承载了全部的业务,所有的业务代码都放在同一个代码仓库中,虽然这样容易部署,运维成本低,但缺点非常明显,随着业务的体量越来越大,项目的代码急剧增加,各个业务间的越来越复杂,耦合度越来越高。而且扩展性随着代码量的增多越来越差,而且发布周期窗口会越来越长,无法做到快速迭代快速上线。
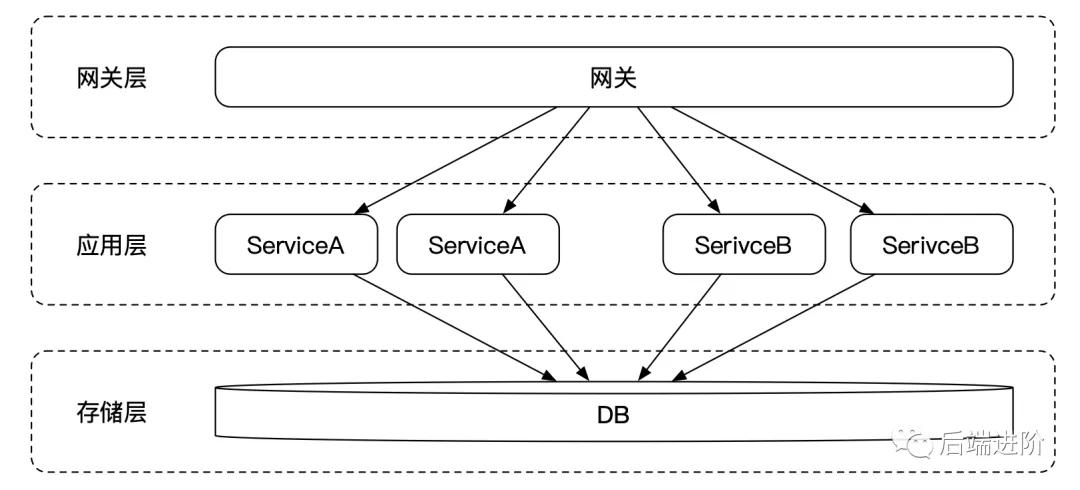
为了解决以上问题,我们可以对系统按照业务的维度进行垂直拆分,比如商城系统,可以拆分成用户服务、交易服务、订单服务等,如上图所示。
到这里,系统经过水平拆分和垂直拆分,应用层基本完成了 SOA 化。
存储拆分
1、存储读写分离
随着业务的发展,这时发现应用服务不再是负担,但数据层成为了整个系统的唯一单点,这时候,随着系统 TPS 的增多,应用的实例部署越来越多,单个数据库的连接数变多,数据的写入效率变慢了,单主库无法维持整个系统的数据读写。
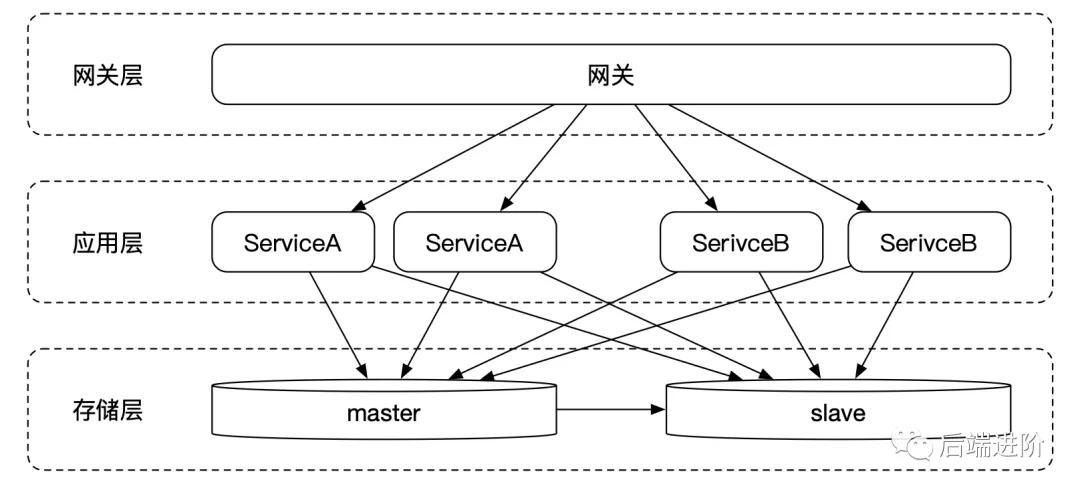
这时将数据层进行读写分离,将数据库拆分成一个主数据库和若干个从数据库,数据的写入还是由主数据库负责,读数据则由从数据库负责,这样就可以大大减轻了数据写入的负担。但读写分离就是读和写不是严格同步的,主数据库同步数据给从数据库需要一定的时间,但大部分的数据延迟都能够接受。
2、存储垂直拆分
数据读写分离之后,数据写入减轻了一定的负担,但我们发现,整个系统全局只有只有一个主库,各个业务域的数据写入都严重依赖于这个主库,流量一旦上来,单主数据库根本扛不住。
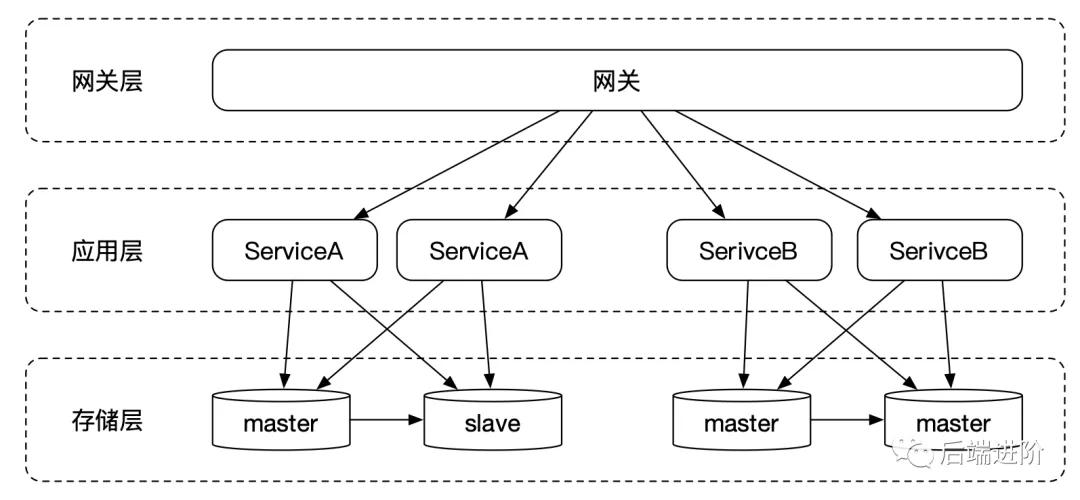
与应用垂直拆分类似,存储层的垂直拆分,同样根据业务维度去拆分,拆分成若干个库,比如商城系统,可以拆分成用户库、订单库等。从上图可以看到,数据写入的流量,各个业务域独自负担自己的数据读写。
至此,一个基本完整的分布式应用架构基本成型了,随之而来的就是要解决因数据库拆分而伴生的分布式事务问题。
3、存储水平拆分
当业务发展到一定量级,单库单表不足以承担起各自业务域的数据读写,那这时怎么办呢?
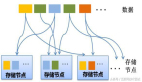
这时我们可以按照用户维度,对数据进行水平拆分,比如按照用户 ID 最后两位,将一张大表切分成 100 张小表,再新建 100 个库(当然数据库可以少于表的数量),我们可以将这种分库分表规则称为百库百表模式。
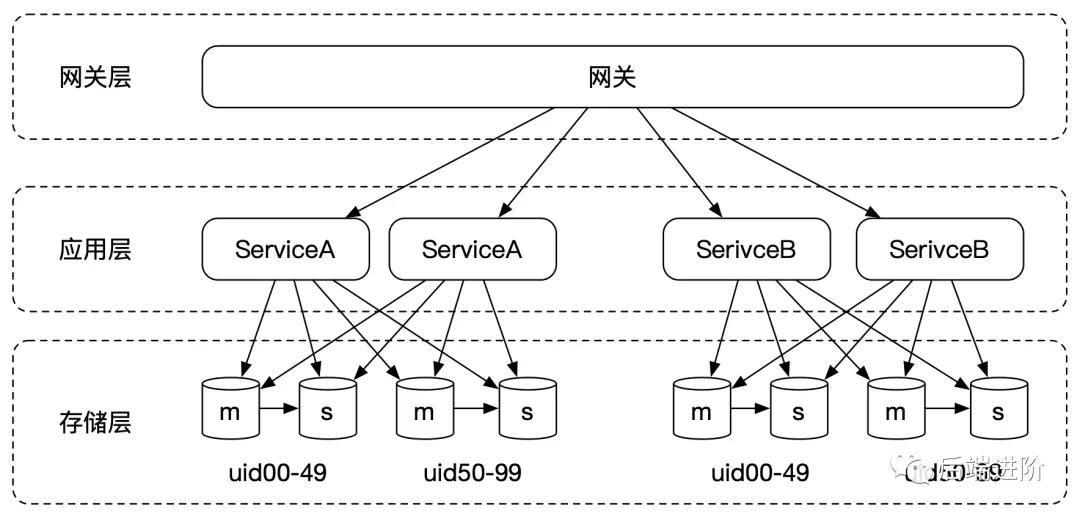
分库分表可以有效减少单表数据的数据量,还可以按照用户维度将流量分散到各个库和表中,性能得到了全面的提升。
至此,一个完整的分布式架构已经成型,事实上这是很多大型互联网公司当前的部署架构现状。
单元化部署
随着业务的进一步发展,类似某些拥有 10 亿+用户量级的巨头公司,因此他们的应用实例部署规模都非常大,这随着而来会伴随着数据库连接数量不够的问题,从上图我们可以看出,随着应用实例的增加,数据库的链接数量就会增多。
为什么呢?
因为每个数据库的实例,都是被应用实例所共享的,那你可能要问为什么要共享,那是因为网关的流量是按平均分配的,你的每个请求,都有可能落到任意的应用实例中,那么这时应用实例就必须要根据你的用户 ID,将数据落在指定的表中,这时应用实例必须要拥有所有数据库的连接才能做到。
那么像 10 亿+用户量级的系统,本身流量已经非常高了,每当让服务进行水平扩容,都异常艰难,甚至已经到了数据库连接的上限,服务不能继续水平扩容了。
那应该怎么办?
既然数据可以按照用户维度进行分库分表,那么请求的流量何尝不能按照用户维度进行水平拆分呢?
我们将按照用户维度对应用实例进行单元化隔离,每个单元都部署了系统所有的服务,用户可在某个单元内走完所有的业务流程,如下图所示:
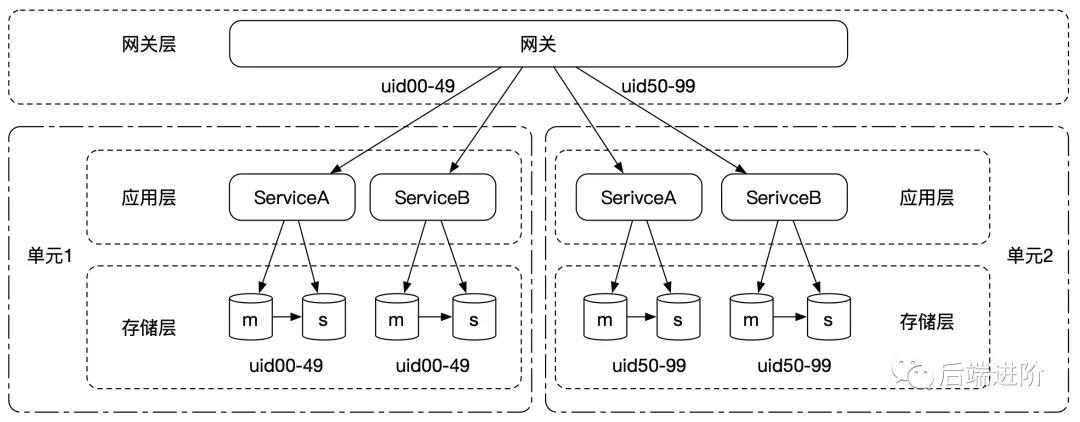
可以看出,经过单元化隔离,数据库的连接数量成倍地减少,如果单元化粒度拆分更小,那么数据库的连接数量会更少。
数据分区
对于大型互联网公司来说,往往拥有多个物理机房,在多个机房中,部署模式主要分成两种:
垂直部署(扩展模式):将系统的服务、数据库划分为若干份,每个机房拥有部分服务和数据库,这样可以解决机房容量问题,但是要完成一个业务,可能需要经过多个机房协作,且某个机房出现故障,会导致整个系统不可用,不具备容灾能力;
水平部署(镜像模式):每个机房拥有所有的服务,即每个机房都能够完成一个业务的流转,具备容灾能力。
一般大多数公司都会采用第二种水平部署模式,但是这种模式下,需要解决数据分区问题,我们知道应用都是无状态的,我们可以很容易地将流量随机分配给各个机房,让每个机房承载一定的流量。但是数据却不行,要做到每个机房拥有独立的数据库是一件挺难的事情。
那怎么解决数据分区问题呢?
前面我们已经谈到单元化部署,由于一个单元包含了系统所有的服务,我们可将其称作一个逻辑数据中心(Logical Data Center),简称 LDC。
同样,水平部署模式下,一个物理机房也拥有所有的服务,我们可将其称作一个互联网数据中心(Internet Data Center),简称 IDC。
那么,它们的关系:
LDC 是对 IDC 的一种逻辑划分。
用大白话讲就是:
LDC 则是在 IDC 的基础上进行的一个逻辑划分,一个 LDC 逻辑数据中心被称为一个「单元」,每个单元都拥有所有部署的应用,每个单元可以分配到任意一个物理机房,每个物理机房可以拥有若干个单元,如下图所示:
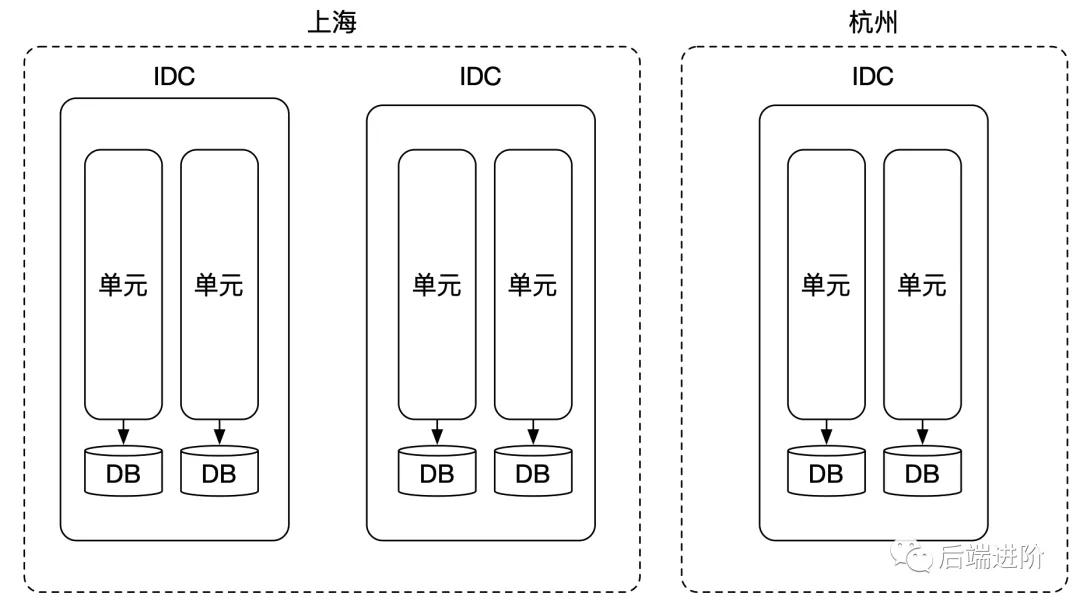
如上图所示,物理机房在水平部署模式下,单元化如何解决数据分区问题呢?
前面我们说了我们按照用户维度进行单元化隔离部署的,那么我们也可以对数据进行分区,将数据按照用户维度对数据进行分区,比如将用户最后 2 位进行数据分区,一共将数据拆分成 100 份,每个单元负责若干份数据,比如系统一共有 10 个单元,那么每个单元负责 10 个分区的数据。
这样,每个单元下都有独立的数据分区,完全可以做到数据的隔离。
如何扩容
在单元化部署架构下,如何进行扩容呢?
应用扩容
系统经过单元化隔离部署之后,通常情况下数据库连接已不再是瓶颈,这也是单元化部署带来的收益之一,这时我们很容易通过将单元中的每个服务增加若干个应用实例来达到扩容的目的。
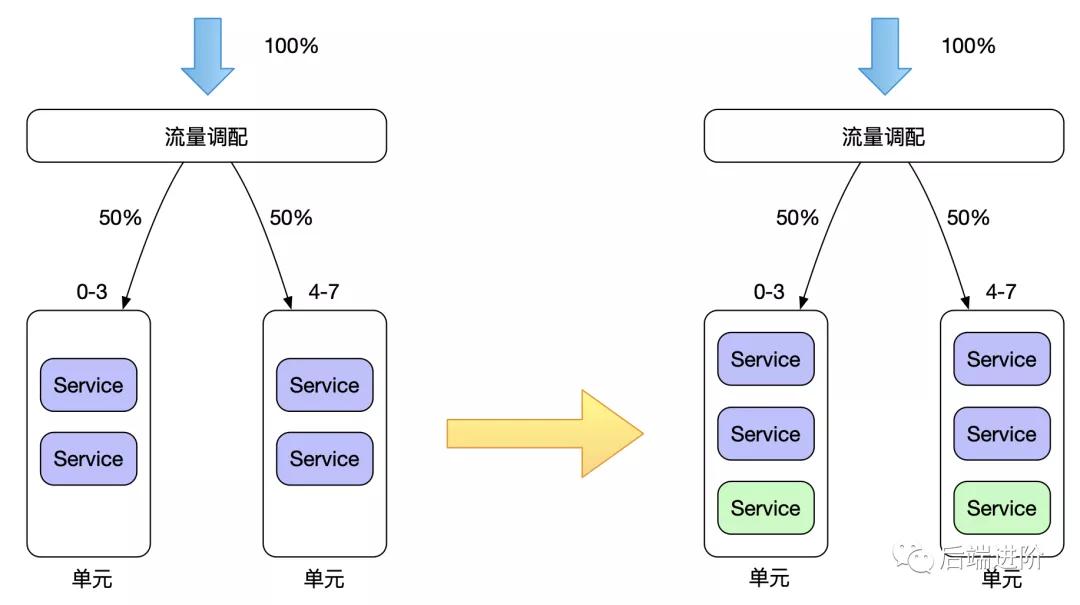
单元扩容
增加单元数量,增加后的每个单元,流量重新分配,但需要注意的是,增加单元数据,并不意味着数据分区会增加,数据层与应用层的扩容完全没有关系,但值得一提的是,单元扩容可以有效减少数据库的连接数,每个单元所连接的数据分区,是按照单元所负责的用户维度的流量来区分的,如下图所示:
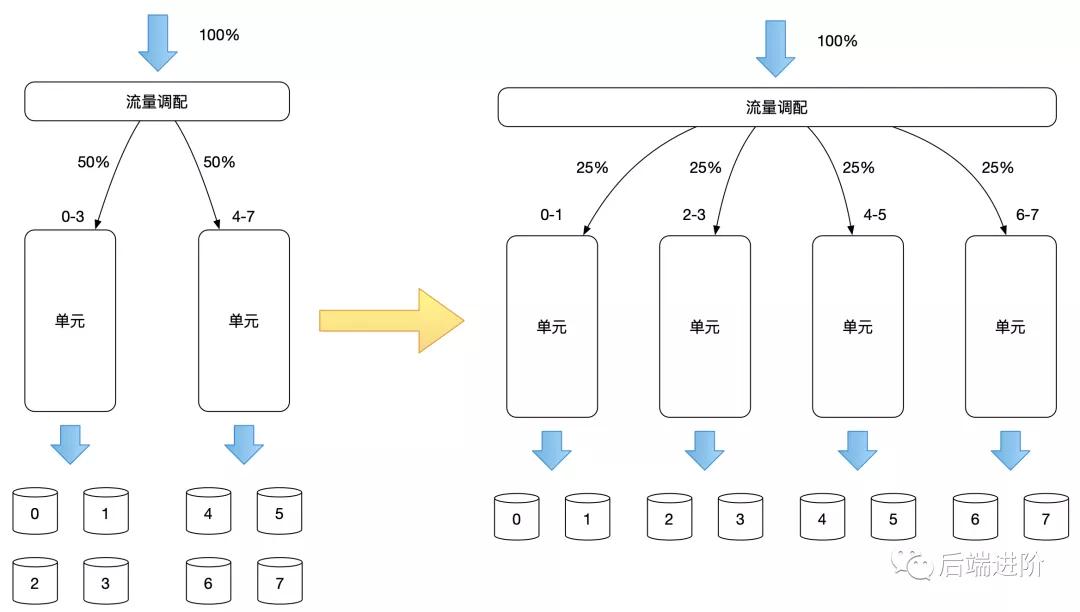
存储扩容
增加一个单元很容易,但是要在原有的数据分区下进行扩容,就不好做了,因为涉及到表路由规则的变更,需要对数据进行迁移,且一般在进行分库分表时,都会提前预估未来业务的容量需求,各个用户维度已经提前进行了 Pre-Sharding 处理了,所以如果数据要进行扩容,则需要对数据进行重新 sharding 处理,这里涉及到数据迁移,就不细展开了。
本文转载自微信公众号「后端进阶」,可以通过以下二维码关注。转载本文请联系后端进阶公众号。