














1、应用场景
对于高精度采样结果,其数值最大可能需要3字节,最少1字节,采用标准C的基础数据类型,U16太小无法满足需求,U32则浪费内存。当样本量很大时,其占用的空间问题便突显出来。能否采用变长数据类型存储呢?对小数据采用U8,大数据采用U32,随着数值大小动态分配存储空间,就是本文的讨论的重点。
2、数据去冗余
U32的空间其数值范围最大接近2^32,该值非常大,实际数值范围远小于它,高位必然为0。例如U32表示1使用0x00000001,前面位都是0,其表达的数值和U8的0x01是一样的,前面重复的一串0属于冗余数据区,是可以剔除的。
假设5个数据D0..4,原本每个数据固定为U32类型,将其高位冗余0去掉,再拼接到U8的一维数组,则占用的空间和大大缩小。思路的核心是把 U32 或者U64 数组裁剪后拼接成U8 数组,同时确保使用时可
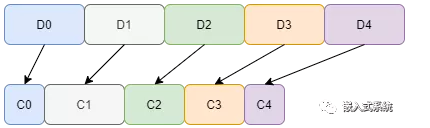
根据U8 数组中存储的信息将对应的数值还原。
假设有0x00000001、0x00000101、0x00000001三个数据,其有效部分是0x01、0x0101、0x01,如果直接拼接在一起,则没法区分0x01010101的含义。因此数据在去掉高位0之后,还需进行编码标记,便于后续解析还原。
3、数据编码
数据编码的主要作用是标记当前数据占用多少连续字节,有两种方案:
1、固定位来定义字节长度(2位可以表示4字节)
一字节:00******
二字节:01******,00******
三字节:10******,01******,00******
四字节:11******,10******,01******,00******
五字节:使用2位不支持
每个字节的最高2位表示属于原始数据的第几个(从0开始),前面举例的3个字节可以表示为:
0x01 编码后二进制为 00-000001,最高2位为0,表示当前是编码后的数据的最后一个字节;
0x0101 编码后二进制为 01-000001--00-000001 解析时取每个字节的2位判断,若为00则表示一个编码数值结束。
因为前面2位固定用于标记字节数,每个字节实际可用范围只有6位,如果原数据位1000 0001,则最高两位的10需要再占用一个字节表示,最终编码为 01-000010--00-000001。
这种编码方式,所有字节有效位是固定的,编解码实现容易。缺点是4字节只有24位有效数据,假如原数据最大到25位,则每个字节分配3位来表示,不过这种大数据一般嵌入式很少使用。
2、字节最高位表示还有剩余数据,借鉴UTF8的编码方式
一字节:0*******
两字节:110*****,10******
三字节:1110****,10******,10******
四字节:11110***,10******,10******,10******
五字节:111110**,10******,10******,10******,10******
六字节:1111110*,10******,10******,10******,10******,10******
七字节:不支持
这种编码方式,最高字节的有效位是变化的,其它字节有效位是6位。
两种编码方式的选取,主要是依据原始数据分布概率,如果原数据范围在24位内,则前面固定位的方式占优,超过32位内则动态的合适,如果数据范围在16位内则没必要如此折腾。
关于源码或者更多交流,请关注微信公众号 嵌入式系统。
4、数据访问
原数据每个值占用固定字节长度,可以方便的使用数组下标遍历,即地址偏移为(单个数字占用的字节数)*(第几个),编码为变长数据后,要想取到某个原数据编码后的值,如果从数组头开始遍历效率是相当低的,有没有更好的办法呢?
将前面一维数组转为二维数组,每行数组按前面的编码实现,数据中预留4个字节,每行占满时尾部标记当前行结束累计包括多少个原始数据,下个编码值则存入下一行,依次类推。
图片如上图,二维数组的一行就退化为一维数组,每行在固定位置标记存储的数量。如果需要查找C10,先按标记数目的字节地址遍历,则可以找到第2行(从0开始)为13,表示需要查找的数据在本行,只需要遍历该行,从C9开始往后查询。
5、总结
选择合适的数据类型的减小存储空间,对大范围的数据使用变长的类型拼接存储,牺牲了部分时间,但节约了ram或flash空间,对资源紧缺的嵌入式设备具有一定的价值。
本文转载自微信公众号「嵌入式系统」,可以通过以下二维码关注。转载本文请联系嵌入式系统公众号。

















