













1.序篇
进入正文。
下面即是文章目录,也对应到本文的结论,小伙伴可以先看结论快速了解本文能给你带来什么帮助:
- 背景及应用场景介绍:join 作为离线数仓中最常见的场景,在实时数仓中也必然不可能缺少它,flink sql 提供的丰富的 join 方式(总结 6 种:regular join,维表 join,temporal join,interval join,array 拍平,table function 函数)对我们满足需求提供了强大的后盾
- 先来一个实战案例:以一个曝光日志 left join 点击日志为案例展开,介绍 flink sql join 的解决方案
- flink sql join 的解决方案以及存在问题的介绍:主要介绍 regular join 的在上述案例的运行结果及分析源码机制,它虽然简单,但是 left join,right join,full join 会存在着 retract 的问题,所以在使用前,你应该充分了解其运行机制,避免出现数据发重,发多的问题。
- 本文主要介绍 regular join retract 的问题,下节介绍怎么使用 interval join 来避免这种 retract 问题,并满足第 2 点的实战案例需求。
2.背景及应用场景介绍
在我们的日常场景中,应用最广的一种操作必然有 join 的一席之地,例如
计算曝光数据和点击数据的 CTR,需要通过唯一 id 进行 join 关联
事实数据关联维度数据获取维度,进而计算维度指标
上述场景,在离线数仓应用之广就不多说了。
那么,实时流之间的关联要怎么操作呢?
flink sql 为我们提供了四种强大的关联方式,帮助我们在流式场景中达到流关联的目的。如下图官网截图所示:

join
- regular join:即 left join,right join,full join,inner join
- 维表 lookup join:维表关联
- temporal join:快照表 join
- interval join:两条流在一段时间区间之内的 join
- array 炸开:列转行
- table function join:通过 table function 自定义函数实现 join(类似于列转行的效果,或者说类似于维表 join 的效果)
在实时数仓中,regular join 以及 interval join,以及两种 join 的结合使用是最常使用的。所以本文主要介绍这两种(太长的篇幅大家可能也不想看,所以之后的文章就以简洁,短为目标)。
3.先来一个实战案例
先来一个实际案例来看看在具体输入值的场景下,输出值应该长啥样。
场景:即常见的曝光日志流(show_log)通过 log_id 关联点击日志流(click_log),将数据的关联结果进行下发。
来一波输入数据:
曝光数据:
| log_id | timestamp | show_params |
|---|---|---|
| 1 | 2021-11-01 00:01:03 | show_params |
| 2 | 2021-11-01 00:03:00 | show_params2 |
| 3 | 2021-11-01 00:05:00 | show_params3 |
点击数据:
| log_id | timestamp | click_params |
|---|---|---|
| 1 | 2021-11-01 00:01:53 | click_params |
| 2 | 2021-11-01 00:02:01 | click_params2 |
预期输出数据如下:
| log_id | timestamp | show_params | click_params |
|---|---|---|---|
| 1 | 2021-11-01 00:01:00 | show_params | click_params |
| 2 | 2021-11-01 00:01:00 | show_params2 | click_params2 |
| 3 | 2021-11-01 00:02:00 | show_params3 | null |
熟悉离线 hive sql 的同学可能 10s 就写完上面这个 sql 了,如下 hive sql
- INSERT INTO sink_table
- SELECT
- show_log.log_id as log_id,
- show_log.timestamp as timestamp,
- show_log.show_params as show_params,
- click_log.click_params as click_params
- FROM show_log
- LEFT JOIN click_log ON show_log.log_id = click_log.log_id;
那么我们看看上述需求如果要以 flink sql 实现需要怎么做呢?
虽然不 flink sql 提供了 left join 的能力,但是在实际使用时,可能会出现预期之外的问题。下节详述。
4.flink sql join
4.1.flink sql
还是上面的案例,我们先实际跑一遍看看结果:
- INSERT INTO sink_table
- SELECT
- show_log.log_id as log_id,
- show_log.timestamp as timestamp,
- show_log.show_params as show_params,
- click_log.click_params as click_params
- FROM show_log
- LEFT JOIN click_log ON show_log.log_id = click_log.log_id;
flink web ui 算子图如下:
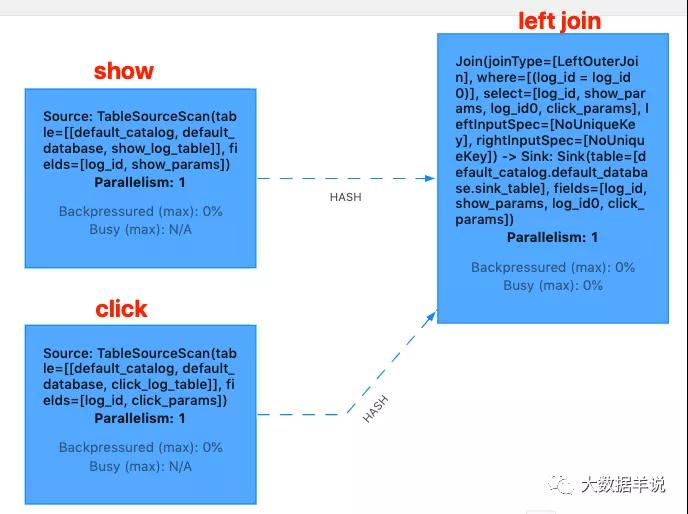
flink web ui
结果如下:
- +[1 | 2021-11-01 00:01:03 | show_params | null]
- -[1 | 2021-11-01 00:01:03 | show_params | null]
- +[1 | 2021-11-01 00:01:03 | show_params | click_params]
- +[2 | 2021-11-01 00:03:00 | show_params | click_params]
- +[3 | 2021-11-01 00:05:00 | show_params | null]
从结果上看,其输出数据有 +,-,代表其输出的数据是一个 retract 流的数据。分析原因发现是,由于第一条 show_log 先于 click_log 到达, 所以就先直接发出 +[1 | 2021-11-01 00:01:03 | show_params | null],后面 click_log 到达之后,将上一次未关联到的 show_log 撤回, 然后将关联到的 +[1 | 2021-11-01 00:01:03 | show_params | click_params] 下发。
但是 retract 流会导致写入到 kafka 的数据变多,这是不可被接受的。我们期望的结果应该是一个 append 数据流。
为什么 left join 会出现这种问题呢?那就要从 left join 的原理说起了。
来定位到具体的实现源码。先看一下 transformations。
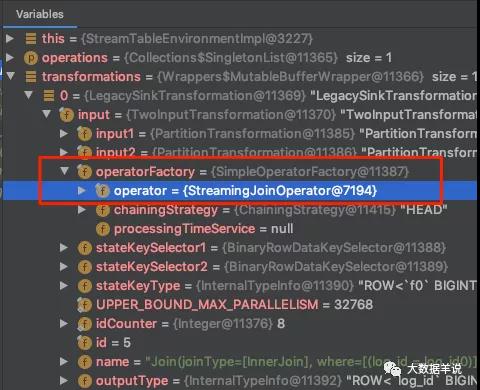
transformations
可以看到 left join 的具体 operator 是 org.apache.flink.table.runtime.operators.join.stream.StreamingJoinOperator。
其核心逻辑就集中在 processElement 方法上面。并且源码对于 processElement 的处理逻辑有详细的注释说明,如下图所示。
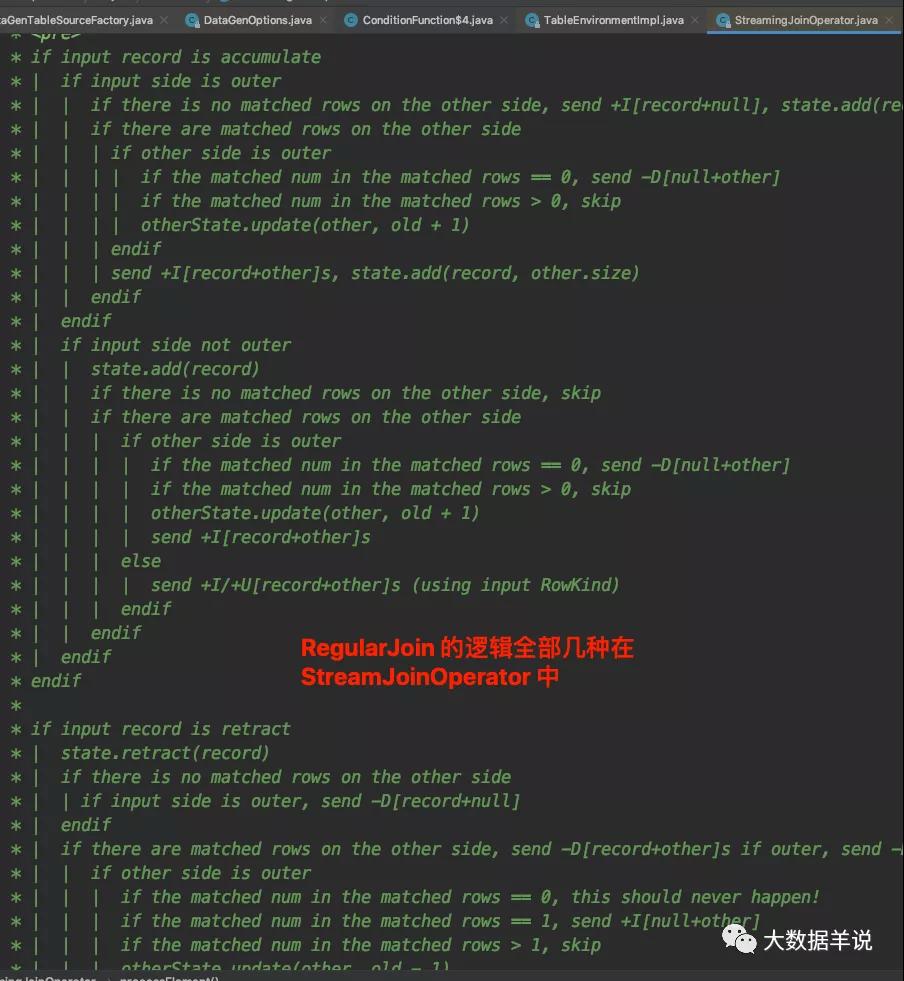
StreamingJoinOperator#processElement
注释看起来逻辑比较复杂。我们这里按照 left join,inner join,right join,full join 分类给大家解释一下。
4.2.left join
首先是 left join,以上面的 show_log(左表) left join click_log(右表) 为例:
- 首先如果 join xxx on 中的条件是等式则代表 join 是在相同 key 下进行的,join 的 key 即 show_log.log_id,click_log.log_id,相同 key 的数据会被发送到一个并发中进行处理。如果 join xxx on 中的条件是不等式,则两个流的 source 算子向 join 算子下发数据是按照 global 的 partition 策略进行下发的,并且 join 算子并发会被设置为 1,所有的数据会被发送到这一个并发中处理。
- 相同 key 下,当 show_log 来一条数据,如果 click_log 有数据:则 show_log 与 click_log 中的所有数据进行遍历关联一遍输出[+(show_log,click_log)]数据,并且把 show_log 保存到左表的状态中(以供后续 join 使用)。
- 相同 key 下,当 show_log 来一条数据,如果 click_log 中没有数据:则 show_log 不会等待,直接输出[+(show_log,null)]数据,并且把 show_log 保存到左表的状态中(以供后续 join 使用)。
- 相同 key 下,当 click_log 来一条数据,如果 show_log 有数据:则 click_log 对 show_log 中所有的数据进行遍历关联一遍。在输出数据前,会判断,如果被关联的这条 show_log 之前没有关联到过 click_log(即往下发过[+(show_log,null)]),则先发一条[-(show_log,null)],后发一条[+(show_log,click_log)] ,代表把之前的那条没有关联到 click_log 数据的 show_log 中间结果给撤回,把当前关联到的最新结果进行下发,并把 click_log 保存到右表的状态中(以供后续左表进行关联)。这也就解释了为什么输出流是一个 retract 流。
- 相同 key 下,当 click_log 来一条数据,如果 show_log 没有数据:把 click_log 保存到右表的状态中(以供后续左表进行关联)。
4.3.inner join
以上面的 show_log(左表) inner join click_log(右表) 为例:
首先如果 join xxx on 中的条件是等式则代表 join 是在相同 key 下进行的,join 的 key 即 show_log.log_id,click_log.log_id,相同 key 的数据会被发送到一个并发中进行处理。如果 join xxx on 中的条件是不等式,则两个流的 source 算子向 join 算子下发数据是按照 global 的 partition 策略进行下发的,并且 join 算子并发会被设置为 1,所有的数据会被发送到这一个并发中处理。
相同 key 下,当 show_log 来一条数据,如果 click_log 有数据:则 show_log 与 click_log 中的所有数据进行遍历关联一遍输出[+(show_log,click_log)]数据,并且把 show_log 保存到左表的状态中(以供后续 join 使用)。
相同 key 下,当 show_log 来一条数据,如果 click_log 中没有数据:则 show_log 不会输出数据,会把 show_log 保存到左表的状态中(以供后续 join 使用)。
相同 key 下,当 click_log 来一条数据,如果 show_log 有数据:则 click_log 与 show_log 中的所有数据进行遍历关联一遍输出[+(show_log,click_log)]数据,并且把 click_log 保存到右表的状态中(以供后续 join 使用)。
相同 key 下,当 click_log 来一条数据,如果 show_log 没有数据:则 click_log 不会输出数据,会把 click_log 保存到右表的状态中(以供后续 join 使用)。
4.4.right join
right join 和 left join 一样,只不过顺序反了,这里不再赘述。
4.5.full join
以上面的 show_log(左表) full join click_log(右表) 为例:
- 首先如果 join xxx on 中的条件是等式则代表 join 是在相同 key 下进行的,join 的 key 即 show_log.log_id,click_log.log_id,相同 key 的数据会被发送到一个并发中进行处理。如果 join xxx on 中的条件是不等式,则两个流的 source 算子向 join 算子下发数据是按照 global 的 partition 策略进行下发的,并且 join 算子并发会被设置为 1,所有的数据会被发送到这一个并发中处理。
- 相同 key 下,当 show_log 来一条数据,如果 click_log 有数据:则 show_log 对 click_log 中所有的数据进行遍历关联一遍。在输出数据前,会判断,如果被关联的这条 click_log 之前没有关联到过 show_log(即往下发过[+(null,click_log)]),则先发一条[-(null,click_log)],后发一条[+(show_log,click_log)] ,代表把之前的那条没有关联到 show_log 数据的 click_log 中间结果给撤回,把当前关联到的最新结果进行下发,并把 show_log 保存到左表的状态中(以供后续 join 使用)
- 相同 key 下,当 show_log 来一条数据,如果 click_log 中没有数据:则 show_log 不会等待,直接输出[+(show_log,null)]数据,并且把 show_log 保存到左表的状态中(以供后续 join 使用)。
- 相同 key 下,当 click_log 来一条数据,如果 show_log 有数据:则 click_log 对 show_log 中所有的数据进行遍历关联一遍。在输出数据前,会判断,如果被关联的这条 show_log 之前没有关联到过 click_log(即往下发过[+(show_log,null)]),则先发一条[-(show_log,null)],后发一条[+(show_log,click_log)] ,代表把之前的那条没有关联到 click_log 数据的 show_log 中间结果给撤回,把当前关联到的最新结果进行下发,并把 click_log 保存到右表的状态中(以供后续 join 使用)
- 相同 key 下,当 click_log 来一条数据,如果 show_log 中没有数据:则 click_log 不会等待,直接输出[+(null,click_log)]数据,并且把 click_log 保存到右表的状态中(以供后续 join 使用)。
4.6.regular join 的总结
总的来说上述四种 join 可以按照以下这么划分。
inner join 会互相等,直到有数据才下发。
left join,right join,full join 不会互相等,只要来了数据,会尝试关联,能关联到则下发的字段是全的,关联不到则另一边的字段为 null。后续数据来了之后,发现之前下发过为没有关联到的数据时,就会做回撤,把关联到的结果进行下发
4.7.怎样才能解决 retract 导致数据重复下发到 kafka 这个问题呢?
既然 flink sql 在 left join、right join、full join 实现上的原理就是以这种 retract 的方式去实现的,就不能通过这种方式来满足业务了。
我们来转变一下思路,上述 join 的特点就是不会相互等,那有没有一种 join 是可以相互等待的呢。以 left join 的思路为例,左表在关联不到右表的时候,可以选择等待一段时间,如果超过这段时间还等不到再下发 (show_log,null),如果等到了就下发(show_log,click_log)。
interval join 闪亮登场。关于 interval join 是如何实现上述场景,及其原理实现,本篇的(下)会详细介绍,敬请期待。
5.总结与展望
源码公众号后台回复1.13.2 sql join 的奇妙解析之路获取。
本文主要介绍了 flink sql regular 的在满足 join 场景时存在的问题,并通过解析其实现说明了运行原理,主要包含下面两部分:
- 背景及应用场景介绍:join 作为离线数仓中最常见的场景,在实时数仓中也必然不可能缺少它,flink sql 提供的丰富的 join 方式(总结 4 种:regular join,维表 join,temporal join,interval join)对我们满足需求提供了强大的后盾
- 先来一个实战案例:以一个曝光日志 left join 点击日志为案例展开,介绍 flink sql join 的解决方案
- flink sql join 的解决方案以及存在问题的介绍:主要介绍 regular join 的在上述案例的运行结果及分析源码机制,它虽然简单,但是 left join,right join,full join 会存在着 retract 的问题,所以在使用前,你应该充分了解其运行机制,避免出现数据发重,发多的问题。
- 本文主要介绍 regular join retract 的问题,下节介绍怎么使用 interval join 来避免这种 retract 问题,并满足第 2 点的实战案例需求。























