












这个问题挺有区分度的,我也是昨天整理面经才看见的这道题。
注意这里问的是为什么进程切换比线程慢,而不是问为什么进程比线程慢。当然这里的线程肯定指的是同一个进程中的线程。
引子
在进入文题之前,我想有必要解释下虚拟地址(逻辑地址)和物理地址的区别
下面这段 C 代码摘录自《操作系统导论 - [美] 雷姆兹·H.阿帕希杜塞尔》,依次打印出 main 函数的地址,由 malloc(类似于 Java 中的 new 操作)返回的堆空间分配的值,以及栈上一个整数的地址:
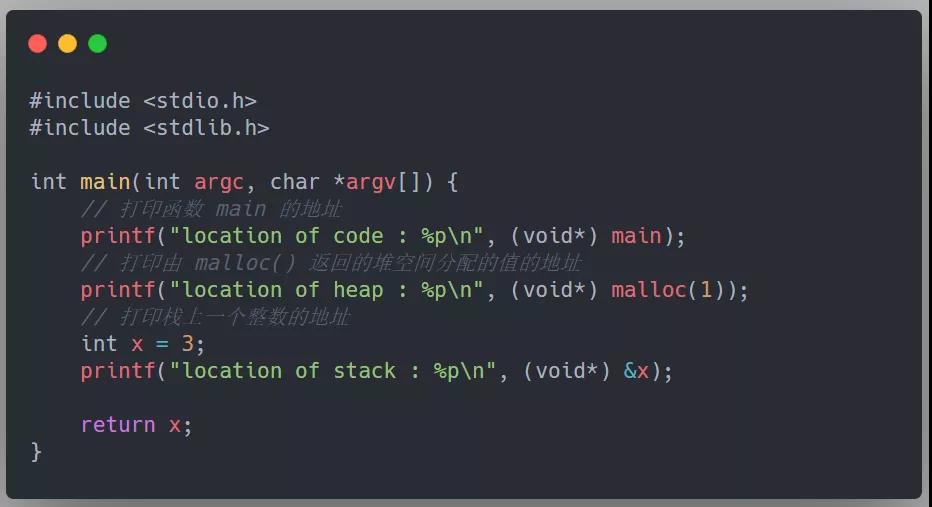
得到以下输出:
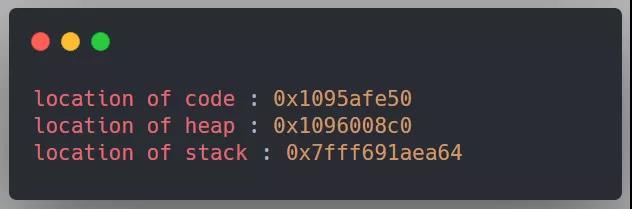
我们需要知道的是,所有这些打印出来的地址都是虚拟的,在物理内存中这些地址并不真实存在,它们最终都将由操作系统和 CPU 硬件翻译成真正的物理地址,然后才能从真实的物理位置获取该地址的值。
OK,上述就当作一个引子,让各位对物理地址和虚拟地址有个直观的理解,下面正文开始。
物理寻址 Physical Addressing
物理地址的概念很好理解,你可以把它称为真正的地址。《深入理解计算机系统 - 第 3 版》中给出的物理地址(physical address)的定义如下:
计算机系统的主存被组织成一个由 M 个连续的字节大小的单元组成的数组。每字节都有一个唯一的物理地址。
比如说,第一个字节的物理地址是 0,接下来的字节地址是 1,再下一个是 2,以此类推,给定这种简单的结构,CPU 访问内存的最自然的方式就是使用这样的物理地址。我们把这种方式称为物理寻址(physical addressing)。
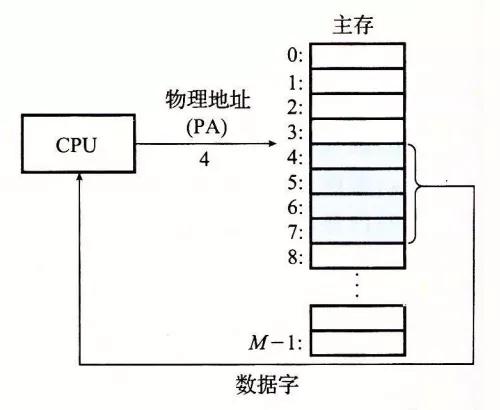
举个例子,比如说当程序执行了一条加载指令,指令内容是从物理地址 4 中读取 4 字节字传送到某个寄存器中。
物理寻址过程如下:当 CPU 执行到这条指令时,会生成物理地址 4,然后通过内存主线,把它传递给内存,内存取出从物理地址 4 处开始的 4 字节字,并将它返回给 CPU,CPU 会将它存放到指定的寄存器中。看下图:
其实不难发现,物理寻址这种方式,每一个程序都直接访问物理内存,其实是存在重大缺陷的:
1)首先,用户程序可以寻址内存的任意一个字节,它们就可以很容易地破坏操作系统,从而使系统慢慢地停止运行。
2)再次,这种寻址方式使得操作系统中同时运行两个或以上的程序几乎是不可能的。
举个例子,我们打开了三个相同的程序(计算器),都执行到某一步。比方说,用户在这三个计算器程序的界面上分别输入了 10、100、1000,其对应的指令就是把用户输入的数字保存在内存中的某个地址中。如果这个位置只能保存一个数,那应该保存哪个呢?这不就冲突了吗?
简单来说,第一个计算器程序给物理内存地址赋值 10,第二个计算器程序也同样给这个地址赋值为 100,那么第二个程序的赋值会覆盖掉第一个程序所赋的值,这会造成两个程序同时崩溃。
当然了,我们也说了是几乎不可能,不是完全不可能,还是有一些方法可以在物理寻址这种方式下实现多个程序并发运行的。
最简单的方法就是:首先,将空闲的进程存储在磁盘上,这样当它们不运行时就不会占用内存,然后,让一个程序(或者说进程)单独占用全部内存运行一小段时间,当发生上下文切换的时候,就停止这个进程,并将它所有的状态信息保存在磁盘上,再加载其他进程的状态信息,然后运行一段时间...... 只要在某一个时间内存中只有一个程序,那么就不会发生上述所说的地址冲突。这就实现了一种比较粗糙的并发。
为什么说他是粗糙的呢,因为这种方法有一个问题:将全部的内存信息保存到磁盘太慢了!特别是当内存增长的时候。
因此,我们考虑把进程对应的内存一直留在物理内存中,给每个进程分别划分各自的区域,在发生上下文切换的时候就切换到特定的区域。
如下图所示,有 3 个进程(A、B、C),每个进程拥有从 512KB 物理内存中切出来给它们的一小部分内存,可以理解为这 3 个进程共享物理内存:

显然,这种方式是存在一定安全隐患的。毕竟如果各个进程之间可以随意读取、写入内容的话那就乱套了。
那么如何对每个进程使用的地址进行保护(protection)呢?继续使用物理内存模型肯定是不行了,因此操作系统创造了一个新的内存抽象,引入了一个新的内存模型,那就是虚拟地址空间,很多书中都会直接称呼为 “地址空间(Address Space)”。
虚拟寻址 Virtual Addressing
上面提到,对于物理内存模型来说,如果各个进程之间可以随意读取、写入内容的话那就乱套了。
所以,每个进程的栈啊、堆啊、代码段啊等等它们的实际物理内存地址对于这个进程来说应该是不可见的,这样谁也不能直接访问这个物理地址。
那问题就来了,物理地址被隐藏起来了,我们该怎么去访问这个进程呢?
操作系统会给每个进程分配一个虚拟地址空间(vitural address),每个进程包含的栈、堆、代码段这些都会从这个地址空间中被分配一个地址,这个地址就被称为虚拟地址。底层指令写入的地址也是虚拟地址。
每个进程都拥有一个自己的虚拟地址空间,并且独立于其他进程的地址空间。(注意这句话非常重要!!!兄弟姐妹们背起来)
也就是说一个进程中的虚拟地址 28 所对应的物理地址与另一个进程中的虚拟地址 28 所对应的物理地址是不同的,这样就不会发生冲突了。
可以这么理解,物理地址就是一个仓库,虚拟地址就是一个门牌,比方说一共有三十个门牌,那么所有的进程都能看见这三十个门牌,但是他们看见的某个相同门牌,指向的并不是同一个仓库。
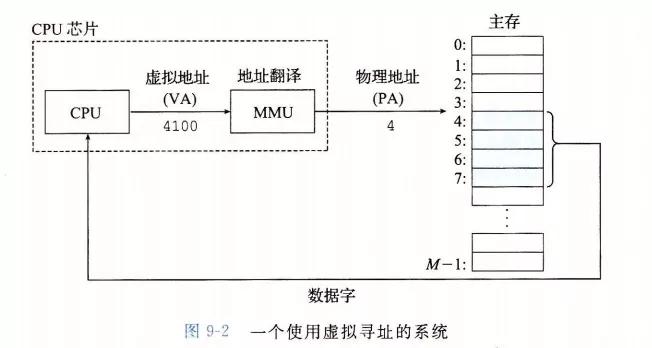
有了虚拟地址空间后,CPU 就可以通过生成一个虚拟地址来访问主存,这个虚拟地址在被送到内存之前会先被转换成合适的物理地址,这个虚拟地址到物理地址的转换过程称为 地址翻译/地址转换(address translation)。
地址翻译需要 CPU 硬件和操作系统的密切合作:CPU 上的内存管理单元(Memory Management Unit,MMU)就是专门用来进行虚拟地址到物理地址的转换的,不过 MMU 需要借助存放在内存中的页表,而这张表的内容正是由操作系统进行管理的。
页表是一个十分重要的数据结构!
操作系统为每个进程建立了一张页表。一个进程对应一张页表,进程的每个页面对应一个页表项,每个页表项由页号和块号(页框号)组成,记录着进程页面和实际存放的内存块之间的映射关系。
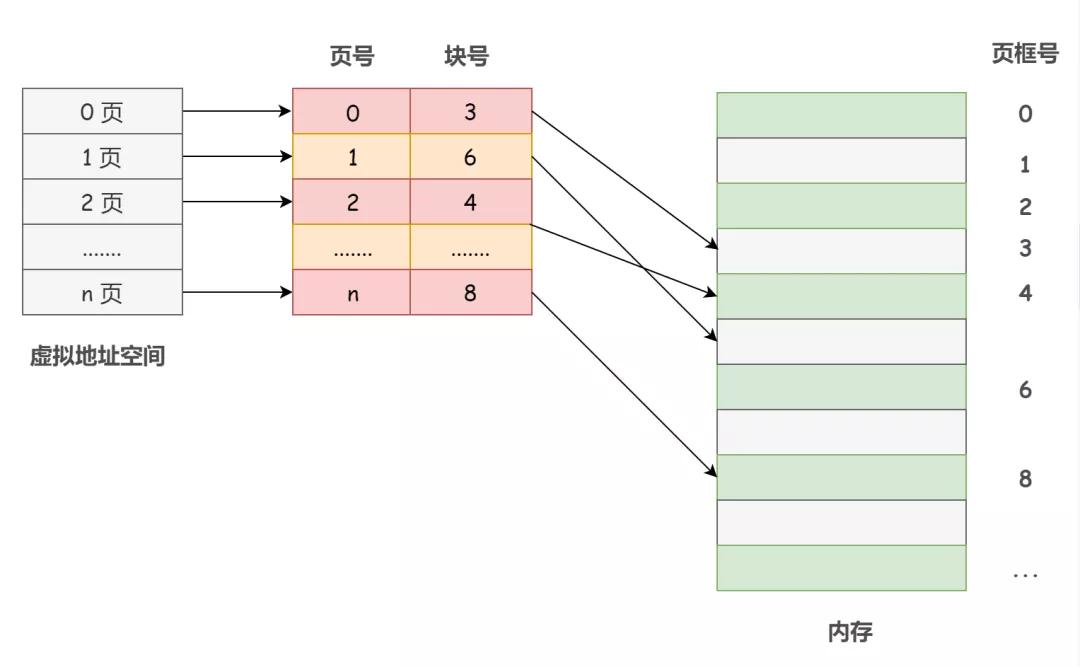
从数学角度来说,页表是一个函数,它的参数是虚拟页号,结果是物理页框号。
至此,上述这一套 CPU 生成虚拟地址并进行地址翻译的流程就是虚拟寻址(virtual addressing):
进程切换为什么比线程切换慢?
呼,讲了一大堆,其实最重要的就是这句话:
每个进程都拥有一个自己的虚拟地址空间,并且独立于其他进程的地址空间
So,Tell me,进程切换会涉及什么的切换?
是的,进程切换会涉及到虚拟地址空间的切换,而这正是导致进程切换比线程切换慢的原因所在!
很多小伙伴可能都云里雾里,啊,是这样吗,怎么回事
想一下,上面是不是说过,虚拟地址转换为物理地址需要两个东西:CPU 上的 MMU 和内存中的页表
每次访问内存,都需要进行虚拟地址到物理地址的转换,对吧,因此,每条指令进行一两次或更多地去访问页表是必要的,而页表又是存在于内存中的。
显然,访问页表(内存)次数太多导致其成为了操作系统地一个性能瓶颈,我们得想个法子解决它
于是,转换检测缓冲区(Translation Lookaside Buffer,TLB)应运而生,也称为快表
为啥说他快呢?因为 TLB 通常内置在 CPU 的 MMU 中,这访问速度跟内存不是一个档次的。内存中的页表一般被称为慢表。
事实上,TLB 的出现是基于这样一种现象的:大多数程序总是对少量的页面进行多次的访问。因此,只有很少的页表项会被反复读取,而其他的页表项很少被访问。
TLB 中存放的就是那些会被反复读取的页表项。换句话说,TLB 中存放的就是页表中的一部分副本。
若 TLB 命中,就不需要再访问内存了;若 TLB 中没有目标页表项,则还需要去查询内存中的页表(慢表),从页表中得到物理页框地址,同时将页表中的该表项添加到 TLB 中。
简单理解,TLB 就相当于一个缓存
现在再回到问题,不知道各位小伙伴有没有一点思路了。
由于进程切换会涉及到虚拟地址空间的切换,这就导致内存中的页表也需要进行切换,一个进程对应一个页表是不假,但是 CPU 中的 TLB 只有一个啊,这就尴尬了,页表切换后这个 TLB 就失效了。这样,TLB 在一段时间内肯定是无法被命中的,操作系统就必须去访问内存,那么虚拟地址转换为物理地址就会变慢,表现出来的就是程序运行会变慢。
而线程切换呢,由于不涉及虚拟地址空间的切换,也就不存在这个问题了。
最后放上这道题的背诵版:
面试官:进程切换为什么比线程切换要慢呢?
小牛肉:额,关于这个问题,需要从虚拟地址和物理地址说起
物理地址就是真实的地址嘛,这种寻址方式很容易破坏操作系统,而且使得操作系统中同时运行两个或以上的程序几乎是不可能的(此处可以举个例子,第一个程序给物理内存地址赋值 10,第二个程序也同样给这个地址赋值为 100,那么第二个程序的赋值会覆盖掉第一个程序所赋的值,这会造成两个程序同时崩溃)。
当然,也不是完全不可能,有一种方式可以实现比较粗糙的并发
就是说,我们将空闲的进程存储在磁盘上,这样当它们不运行时就不会占用内存,当进程需要运行的时候再从磁盘上转到内存上来,不过很显然这种方式比较浪费时间。
于是,我们考虑,把所有进程对应的内存一直留在物理内存中,给每个进程分别划分各自的区域,这样,发生上下文切换的时候就切换到特定的区域
那问题还是很明显的,就是仍然没法避免破坏操作系统,因为各个进程之间可以随意读取、写入内容。
所以,我们需要一种机制对每个进程使用的地址进行保护,因此操作系统创造了一个新的内存模型,那就是虚拟地址空间
就是说,每个进程都拥有一个自己的虚拟地址空间,并且独立于其他进程的地址空间,然后每个进程包含的栈、堆、代码段这些都会从这个地址空间中被分配一个地址,这个地址就被称为虚拟地址。底层指令写入的地址也是虚拟地址。
有了虚拟地址空间后,CPU 就可以通过虚拟地址转换成物理地址这样一个过程,来间接访问物理内存了。
地址转换需要两个东西,一个是 CPU 上的内存管理单元 MMU,另一个是内存中的页表,页表中存的虚拟地址到物理地址的映射
但是呢,每次访问内存,都需要进行虚拟地址到物理地址的转换,对吧,这样的话,页表就会被频繁地访问,而页表又是存在于内存中的。所以说,访问页表(内存)次数太多导致其成为了操作系统地一个性能瓶颈。
于是,引入了转换检测缓冲区 TLB,也就是快表,其实就是一个缓存,把经常访问到的内存地址映射存在 TLB 中,因为 TLB 是在 CPU 的 MMU 中的嘛,所以访问起来非常快。
然后,正是因为 TLB 这个东西,导致了进程切换比线程切换慢。
由于进程切换会涉及到虚拟地址空间的切换,这就导致内存中的页表也需要进行切换,一个进程对应一个页表是不假,但是 CPU 中的 TLB 只有一个,页表切换后这个 TLB 就失效了。这样,TLB 在一段时间内肯定是无法被命中的,操作系统就必须去访问内存,那么虚拟地址转换为物理地址就会变慢,表现出来的就是程序运行会变慢。
而线程切换呢,由于不涉及虚拟地址空间的切换,所以也就不存在这个问题了。



















