本文转载自微信公众号「黑客下午茶」,作者为少 。转载本文请联系黑客下午茶公众号。
探索 Snuba 数据模型
为了构建 Snuba 查询,第一步是能够知道您应该查询哪个数据集,您应该选择哪些实体以及每个实体的 schema 是什么。
有关数据集和实体的介绍,请参阅 Snuba 数据模型部分。
- https://getsentry.github.io/snuba/architecture/datamodel.html
数据集可以在这个模块中找到。每个数据集都是一个引用实体的类。
- https://github.com/getsentry/snuba/blob/master/snuba/datasets/factory.py
系统中的实体列表可以通过 snuba entity 命令找到:
- snuba entities list
会返回如下内容:
- Declared Entities:
- discover
- errors
- events
- groups
- groupassignee
- groupedmessage
- .....
一旦我们找到了我们感兴趣的实体,我们就需要了解在该实体上声明的 schema 和 relationship。相同的命令描述了一个实体:
- snuba entities describe groupedmessage
会返回:
- Entity groupedmessage
- Entity schema
- --------------------------------
- offset UInt64
- record_deleted UInt8
- project_id UInt64
- id UInt64
- status Nullable(UInt8)
- last_seen Nullable(DateTime)
- first_seen Nullable(DateTime)
- active_at Nullable(DateTime)
- first_release_id Nullable(UInt64)
- Relationships
- --------------------------------
- groups
- --------------------------------
- Destination: events
- Type: LEFT
- Join keys
- --------------------------------
- project_id = LEFT.project_id
- id = LEFT.group_id
它提供列的列表及其类型以及与数据模型中定义的其他实体的关系。
准备对 Snuba 的查询
Snuba 查询语言称为 SnQL。它记录在 SnQL 查询语言部分。所以本节不赘述。
- https://getsentry.github.io/snuba/language/snql.html
有一个 python sdk 可用于构建 Snuba 查询,它可以用于任何 Python 客户端,包括 Sentry。snuba-sdk。
- https://github.com/getsentry/snuba-sdk
查询表示为一个 Query 对象,如:
- query = Query(
- dataset="discover",
- match=Entity("events"),
- select=[
- Column("title"),
- Function("uniq", [Column("event_id")], "uniq_events"),
- ],
- groupby=[Column("title")],
- where=[
- Condition(Column("timestamp"), Op.GT, datetime.datetime(2021, 1, 1)),
- Condition(Column("project_id"), Op.IN, Function("tuple", [1, 2, 3])),
- ],
- limit=Limit(10),
- offset=Offset(0),
- granularity=Granularity(3600),
- )
有关如何构建查询的更多详细信息,请参见 sdk 文档。
- https://getsentry.github.io/snuba-sdk/
一旦查询对象准备就绪,它就可以发送到 Snuba。
使用 Sentry 向 Snuba 发送查询
查询 Snuba 时最常见的用例是通过 Sentry。本节说明如何在 Sentry 代码库中构建查询并将其发送到 Snuba。
Sentry 导入了上述的 Snuba sdk。这是构建 Snuba 查询的推荐方法。
一旦创建了 Query 对象,Sentry 提供的 Snuba client api 就可以并且应该用于将查询发送到 Snuba。
api 在这个模块中。它负责缓存、重试并允许批量查询。
- https://github.com/getsentry/sentry/blob/master/src/sentry/utils/snuba.py#L667
该方法返回一个字典,其中包含响应中的数据和其他元数据:
- {
- "data": [
- {
- "title": "very bad",
- "uniq_events": 2
- }
- ],
- "meta": [
- {
- "name": "title",
- "type": "String"
- },
- {
- "name": "uniq_events",
- "type": "UInt64"
- }
- ],
- "timing": {
- ... details ...
- }
- }
data 部分是一个列表,每行一个字典。meta 包含响应中包含的列的列表,其数据类型由 Clickhouse 推断。
通过 Web UI 发送测试查询
Snuba 具有可用于发送查询的最小 Web UI。您可以在本地运行 Snuba, 并且可以通过 http://localhost:1218/[DATASET NAME]/snql 访问 Web UI。
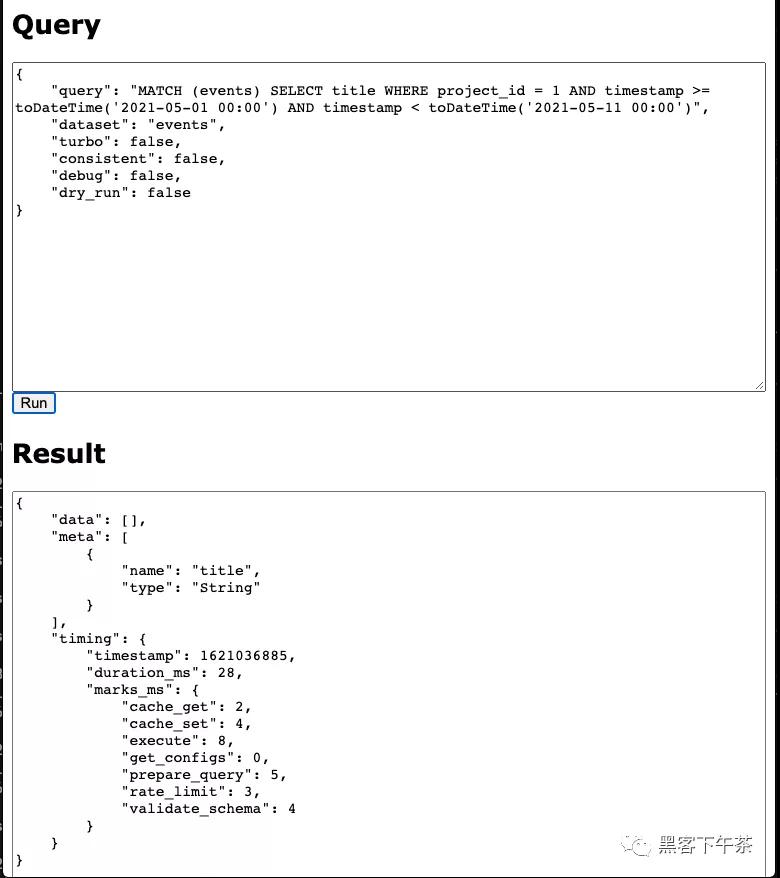
应该在 query 属性中提供 SnQL 查询,并且响应的结构与上一节中讨论的相同。
通过 curl 发送查询
Web UI 仅将 payload 作为 POST 发送。因此,使用 curl 或任何其他 HTTP 客户端可以实现相同的结果。
请求和响应格式
请求格式在上面截图中可见:
- query 包含字符串形式的 SnQL 查询。
- dataset 是数据集名称(如果尚未在 url 中指定。
- debug 使 Snuba 在响应中提供详尽的统计信息,包括 Clickhouse 查询。
- consistent 强制 Clickhouse 查询以单线程模式执行,并且如果 Clickhouse 表被复制,它将强制 Snuba 始终命中同一个节点。可以保证顺序一致性,因为这是消费者默认写入的节点。这是通过设置为 in_order 的负载平衡 Clickhouse 属性实现的。
- https://clickhouse.tech/docs/en/operations/settings/settings/#load_balancing-in_order
- turbo 为 TURBO_SAMPLE_RATE Snuba 设置中定义的查询设置采样率。它还可以防止 Snuba 将 FINAL 模式应用于 Clickhouse 查询,以防在替换后需要保证正确的结果。
Snuba 可以使用 4 个 http code 进行响应。200 表示成功的查询,如果查询无法正确验证,则为 400。500 通常意味着与 Clickhouse 相关的问题(从超时到连接问题),尽管 Snuba 仍然无法提前识别一些无效查询。Snuba 有一个内部速率限制器,所以 429 也是一个可能的返回码。
成功查询的响应格式与上面讨论的相同。完整版本如下所示(在 debug 模式下)
- {
- "data": [],
- "meta": [
- {
- "name": "title",
- "type": "String"
- }
- ],
- "timing": {
- "timestamp": 1621038379,
- "duration_ms": 95,
- "marks_ms": {
- "cache_get": 1,
- "cache_set": 4,
- "execute": 39,
- "get_configs": 0,
- "prepare_query": 10,
- "rate_limit": 4,
- "validate_schema": 34
- }
- },
- "stats": {
- "clickhouse_table": "errors_local",
- "final": false,
- "referrer": "http://localhost:1218/events/snql",
- "sample": null,
- "project_rate": 0,
- "project_concurrent": 1,
- "global_rate": 0,
- "global_concurrent": 1,
- "consistent": false,
- "result_rows": 0,
- "result_cols": 1,
- "query_id": "f09f3f9e1c632f395792c6a4bfe7c4fe"
- },
- "sql": "SELECT (title AS _snuba_title) FROM errors_local PREWHERE equals((project_id AS _snuba_project_id), 1) WHERE equals(deleted, 0) AND greaterOrEquals((timestamp AS _snuba_timestamp), toDateTime('2021-05-01T00:00:00', 'Universal')) AND less(_snuba_timestamp, toDateTime('2021-05-11T00:00:00', 'Universal')) LIMIT 1000 OFFSET 0"
- }
timing 部分包含查询的时间戳和持续时间。有趣的是,持续时间被分解为几个阶段:marks_ms。
sql 元素是 Clickhouse 查询。
stats 字典包含以下 key
- clickhouse_table 是 snuba 在查询处理过程中选取的表。
- final 表示 Snuba 是否决定向 Clickhouse 发送 FINAL 查询,这会迫使 Clickhouse 立即应用相关的合并(Merge Tree)。细节
- https://clickhouse.tech/docs/en/sql-reference/statements/select/from/#select-from-final
- sample 是应用的采样率。
- project_rate 是查询时 Snuba 每秒收到的特定项目的请求数。
- project_concurrent 是查询时涉及特定项目的并发查询数。
- global_rate 与 project_rate 相同,但不专注于一个项目。
- global_concurrent 与 project_concurrent 相同,但不专注于一个项目。
- query_id 是此查询的唯一标识符。
查询验证问题通常采用以下格式:
- {
- "error": {
- "type": "invalid_query",
- "message": "missing >= condition on column timestamp for entity events"
- }
- }
Clickhouse 错误将具有类似的结构。type 字段将显示 clickhouse,该消息将包含有关异常的详细信息。与查询验证错误相反,在 Clickhouse 错误的情况下,实际执行了查询,因此存在为成功查询描述的所有时间和统计信息。