












本文转载自微信公众号「Linux开发那些事儿」,作者LinuxThings。转载本文请联系Linux开发那些事儿公众号。
日常工作的过程中,关于字符编码的问题经常让人头疼不已,这篇文章就来捋一捋关于 GB2312、GBK、GB18030 相关的知识 以及它们和 Unicode 的关系。
简介
- GB2312
1980 年,中国发布了第一个汉字编码标准,也即 GB2312 ,全称 《信息交换用汉字编码字符集·基本集》,通常简称 GB (“国标”汉语拼音首字母), 共收录了 6763 个常用的汉字和字符,此标准于次年5月实施,它满足了日常 99% 汉字的使用需求
- GBK
由于有些汉字是在 GB2312 标准发布之后才简化的,还有一些人名、繁体字、日语和朝鲜语中的汉字也没有包括在内,所以,在 GB2312 的基础上添加了这部分字符,就形成了 GBK ,全称 《汉字内码扩展规范》,共收录了两万多个汉字和字符,它完全兼容 GB2312
GBK 于 1995 年发布,不过它只是 "技术规范指导性文件",并不属于国家标准
- GB18030
GB18030 全称《信息技术 中文编码字符集》 ,共收录七万多个汉字和字符, 它在 GBK 的基础上增加了中日韩语中的汉字 和 少数民族的文字及字符,完全兼容 GB2312,基本兼容 GBK
GB18030 发布过两个版本,第一版于 2000 年发布,称为 GB18030-2000,第二版于 2005 年发布,称为 GB18030-2005
编码方式
ASICII、GB2312、GBK、GB18030 之间的关系可以用下图表示
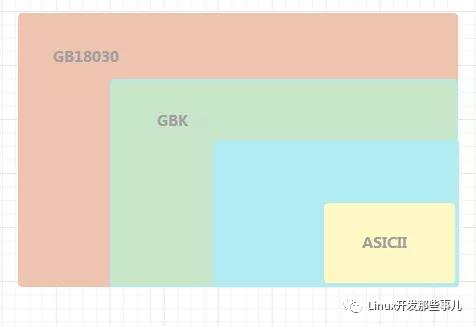
GB2312 兼容 ASICII 编码, GBK 兼容 GB2312 编码,GB18030 兼容 GB2312 编码 和 GBK 编码
实际生活中,我们用到的 99% 的汉字,都属于 GB2312 编码范围 ,GB2312 每个编码对应的是哪个汉字可以参考 GB2312简体中文编码表, GBK 编码可以参考 GBK编码表, GB18030 可以参考 GB18030-2005 文档
GB2312 编码
GB2312 把每个汉字都编码成两个字节,第一个字节是高位字节,第二个字节是低位字节
GB2312 为了兼容 ASICII ,其编码需要进行一些转换才能避免和 ASICII 编码重叠,转换的过程涉及到区位码和国标码的概念,下面说明转成内码的过程
- 区位码
GB2312 对汉字进行了分区处理,每个区含有 94 个汉字或者字符,总共有 94 个区,每个汉字或者字符都对应一个 分区编号和分区内的位置编号,称为 区位码
比如:汉字 "中" 字的 分区编号是 54,分区内位置编号是 48,所以,"中" 字的区位码是 54 48
- 国标码
国标码 也叫 交换码,用于交换文件所使用的编码,在早期,不同的操作系统可能使用不同的内码,如果它们之间要交换文件,则会发生乱码的现象,当时的解决方法是交换文件之前先转成交换码再交换,接收者收到之后再转成内码
交换码是比较早期的一种方案,目前系统大都采用内码作为交换码
ASICII 码为 0- 31 的这 32 个字符是不可显示的字符,为了避免和这些字符的码点冲突,将 分区编号和分区内位置编号都加上 32 ,把这个转换的结果称为 国标码
比如:汉字 "中" 字分区编号是 54,分区内位置编号是 48,加上 32 之后,分区编号是 54 + 32 = 86, ,分区内位置编号是 48 + 32 = 80,所以 "中" 字 的国标码是 86 80
- 内码
国标码 和 ASICII 码还是存在一定的重复,比如 "中" 字 的国标码是 86 80,对应第一个字节是 86,第二个字节是 80,而在 ASICII 码中它们分别代表大写字母V 和 大写字母 P,这就无法区分它们到底是一个汉字,还是两个字母
为了解决这一点,把国标码中的每个字节的最高位置为 1,也即相当于每个字节都加上 128 ( 2的7次方 ),还是以 "中" 字为例,它的 国标码是 86 80,加上 128 后, 第一个字节是 86 + 128 = 214, 第二个字节是 80 + 128 = 208,转化成 16 进制是 0xD6 0xD0 ( 214 的十六进制是 0xD6, 208 的十六进制是 0xD0 )
国标码的每个字节都加上 128 后,得到国标码的机内码,简称 内码,汉字是以内码的形式在计算机中存储和传播的
上面介绍 区位码 和 国标码,主要是是为了说明 汉字内码是如何一步一步发展而来的
可以看出,汉字的 区位码 + 32 + 128 就得到了内码,进一步简化,区位码 + 32 + 128 = 区位码 + 160 = 区位码 + 0xA0(128 的十六进制) , 因此 内码 = 区位码 + 0xA0
比如:"中" 字的区位码是 54 48,对应的十六进制是0x36 0x30,因此它的内码为 (0x36 + 0xA0) (0x30 + 0xA0),也即 0xD6 0xD0
关于汉字的区位码请参考:汉字区位码
GB2312 有效的编码范围如下图所示
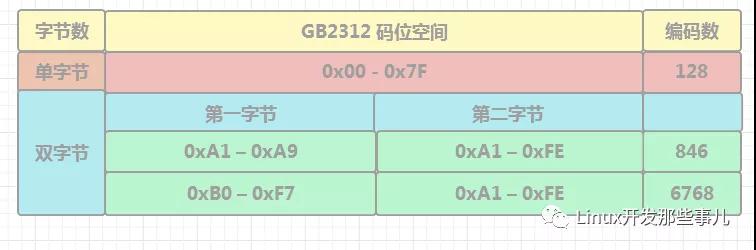
上图中 红色栏 表示 ASICII 的编码范围,绿色栏表示 GB2312 编码范围
GBK 编码
和 GB2312 一样,GBK 也是双字节编码,为了向下兼容 GB2312, GBK 使用了 GB2312 没有用到的编码区域,总的编码范围是: 第一个字节 0x81–0xFE,第二个字节 0x40–0xFE, 具体的编码范围细分如下

上述表格中,红色栏是 GBK 中包含的 GB2312 以及 ASICII 的编码范围,它们的编码范围保持不变
绿色栏的是 GBK 新增的编码范围
紫色栏是 用户自定义编码范围
GB18030 编码
与 GBK 不同的是,GB18030 是变长多字节字符集,每个字或字符可以由一个,两个或四个字节组成,所以它的编码空间是很大的,最多可以容纳 161 万个字符
由于需要兼容 GBK,四个字节的前两个字节和 GBK 编码保持一致,GB18030 具体的编码范围如下

GB18030 与 Unicode
GB18030 和 Unicode 相当于两套单独的编码体系,它们都对世界上大部分字符进行编码,赋予每个字符一个唯一的编号,只不过对于同一个字符,GB18030 和 Unicode 对应的编号是不一样的, 比如:汉字 "中" 字的 GB18030 编码是 0xD6D0, 对应的 Unicode 码元是 0x4E2D, 从这一点上可以认为 GB18030 是一种 Unicode 的转换格式
注意:要表达 Unicode 的编码格式才真正算得上 Unicode 转换格式,所以严格意义上说 GB18030 并不是真正的 Unicode 转换格式
GB18030 既是字符集又是编码格式,也即字符在字符集中的编号以及存储是进行编码用的编号是完全相同的,而 Unicode 仅仅是字符集,它只规定了字符的唯一编号,它的存储是用其他的编码格式的,比如 UTF8、UTF16 等等
既然 GB18030 和 Unicode 都能表示世界上大部分字符,为什么要弄两套字符集呢,一套的话不更有利于信息的传播吗?
1、在 Unicode 出现之前,没有统一的字符编码,每个操作系统上都有自己的一套编码标准,像早期的 window 上需要安装字符集,才能支持中文,这里的字符集就是微软自定的标准,换个其他系统就会失效
2、对于大部分中文字符来说,采用 GB18030 编码的话,只需两个字节,如果采用 UTF8 编码,就需要三个字节, 所以用 GB18030 存储和传输更节省空间
ASICII、GB2312、GBK、GB18030 以及 UTF8 的关系
它们的关系如下图
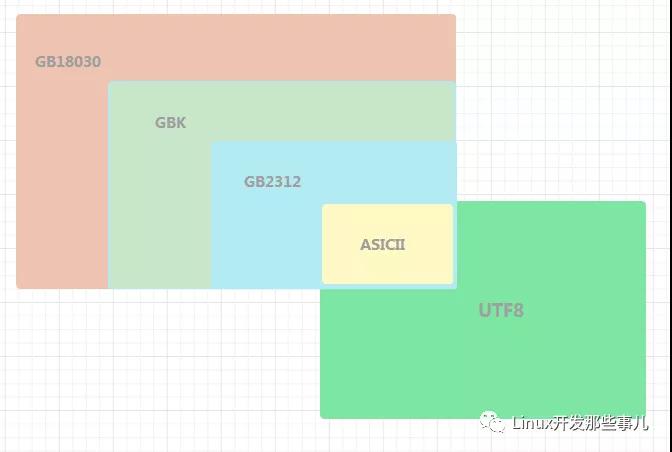
由上图可知,GB2312、GBK、GB18030 以及 UTF8 共同点是都兼容 ASICII
全角和半角字符
使用输入法输入字符的时候,有全角和半角之分,对于同一个字符,全角和半角对应的码点是不一样的
下面列出了一些字符的全角和半角的外观截图

半角是 ASICII 码中的字符,对应的编码范围是 0x00 - 0x7F,每个字符占一个字节
全角是 GB2312 中的字符,每个字符占用两个字节 ,其编码范围和半角字符范围是没有重叠的
对于汉字来说,是没有全角和半角之分的
比如:上图中 @ 符号,全角的编码是 0xA3C0,占两个字节, 半角的编码是 0x40,占一个字节
通过内码输入汉字的方法
有时需要输入一些特殊的字符,比如 带圆圈的数字字符 ①,一般需要借助输入法的小键盘来输入
这里介绍一种使用字符内码来快速输入的方法: 按住 Alt 键不放,输入字符内码的十进制,输入完后松开 Alt 键
例如,输入带圆圈的数字 ② 的步骤
1、查找带圆圈数字 2 的字符的编码 0xA2DA,十进制是 41690
2、按住 Alt 键不放,输入 41690,松开 Alt 键
3、输入完毕,这时就会出现字符 ②
一般 Linux的 SSH 连接工具 或 windows 上的记事本,都支持内码输入






















