












【51CTO.com快译】本文对软件供应商为什么会为反向ETL引入新的解决方案,何时需要反向ETL,以及它如何适合企业的架构进行了分析和探讨。而使用Apache Kafka等工具来处理动态数据的事件流是实时用例反向ETL的关键部分。

什么是ETL和反向ETL?
首先从了解术语开始,ETL和反向ETL是什么?
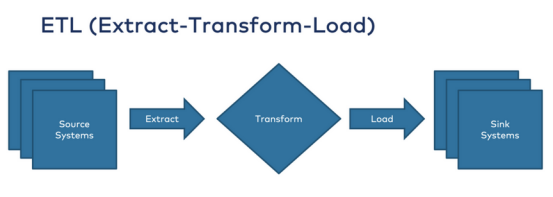
1.ETL(提取-转换-加载)
ETL(提取-转换-加载)是数据集成的常用术语。Informatica公司或Talend公司等供应商提供可视化编码来实现强大的ETL管道。云计算将新的SaaS参与者和术语集成平台即服务(iPaaS)带入ETL市场,其供应商包括Boomi公司、SnapLogic公司或Mulesoft Anypoint公司。
大多数ETL工具针对大数据工作负载以批处理方式运行,或者使用SOAP/REST Web服务和API进行不可扩展的实时通信。ETL管道使用来自各种数据源的数据,对其进行转换或聚合,并将处理之后的静态数据存储在数据接收器中,例如数据库、数据仓库或数据湖:
提取-加载-转换(ELT)是一种非常相似的方法。但是,转换和聚合发生在摄取到数据存储区域之后:

Databricks和Snowflake等数据存储和分析供应商推广ELT方法也就不足为奇了。例如,Snowflake提出了“内部缓冲网格”,其中所有域和数据产品都构建在其云服务中。
2.反向ETL
顾名思义,反向ETL是ETL的反转。这意味着将数据从数据存储移动到第三方系统以“使数据可操作”的过程,正如解决方案的营销人员所说:
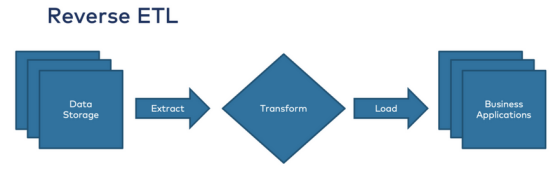
数据从长期存储系统(数据仓库、数据湖)消耗。然后将数据推送到业务应用程序,例如Salesforce(CRM)、Marketo(营销)或Service Now(客户成功),以利用它进行管道生成、营销活动或客户沟通。
用于反向ETL的产品和SaaS产品
人们只需在谷歌搜索引擎中搜索“反向ETL”,即可找到专门推销其解决方案的供应商。他们还为“正常数据集成条款”支付广告费用。因此,即使没有搜索这些厂商,也很可能看到它们。这些厂商的大多数都是初创公司,他们围绕反向ETL产品开展新业务。其软件供应商包括Hightouch、Census、Grouparoo、Rudderstack、Omnata和Seekwell。
有趣的事实:如果搜索Snowflake的反向ETL,将搜索不到任何结果,因为他们希望将数据保存在他们的数据仓库中。
所有ETL工具的一个关键优势和卖点是可视化编码,因此是ETL管道开发和维护的上市时间。一些解决方案针对公民集成商(这是Gartner公司创造的术语),即构建集成的业务人员。
1.反向ETL==销售、营销、客户成功的实时数据
大多数反向ETL的成功案例都在谈论关注销售、营销或客户成功。这些用例吸引了业务部门。这些团队不想购买像Informatica或Talend这样的ETL工具。企业期望提供简单直观的用户界面,就像公民集成商一样。
供应商以业务人员为目标,并承诺提供简化的技术基础设施。例如,一家供应商表示,可以淘汰遗留中间件并减少ETL工作。而这让人想到了“影子IT”。
尽管如此,了解一下反向ETL的用例:
- 在发生之前识别有风险的客户和潜在的客户流失。
- 通过关联来自CRM和其他界面的数据来推动新的销售。
- 用于向现有客户进行交叉销售和追加销售的超个性化营销。
- 运营分析以更快地监控业务应用程序和数据的变化。
- 将数据复制到现代云计算应用程序,以获得更好的报告功能和洞察力。
此外,所有供应商都讨论了上述用例的实时数据。但不幸的是,反向ETL是构建实时用例的巨大反模式。以下更详细地探讨原因。
2.反向ETL+数据湖+实时==神话
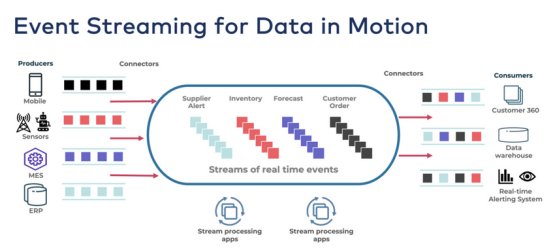
以上描述的一些用例非常好,具有巨大的商业价值。这些实时用例是使用活动中的事件流处理数据构建的。
如果将数据存储在数据仓库或数据湖中,则无法再实时处理它,因为它已经处于静止状态。这些数据存储是为索引、搜索、批处理、报告、模型训练和其他在存储系统中有意义的用例而构建的。但是不能从静态存储中实时消耗动态数据:

这就是事件流发挥重要作用的地方。Apache Kafka等平台支持实时处理事务和分析工作负载的动态数据。因此了解现代企业架构,它利用事件流进行动态数据处理,利用数据仓库或数据湖进行静态数据处理。
企业架构中的反向ETL
以下探讨反向ETL如何适应企业架构,以及何时需要一个单独的工具。为此先了解反向ETL有什么作用?它从存储中提取数据,转换或聚合数据,然后将其摄取到业务应用程序中。
反向ETL有两个选项:SQL查询和变更数据捕获(CDC)。
1.反向ETL==SQL查询与变更数据捕获
如果反向ETL工具使用SQL,那么它通常是对静态数据的查询。这一用例使业务人员能够在直观的用户界面中创建查询。其用例包括创建新的营销活动或分析客户成功之旅。基于SQL的反向ETL需要易于使用的直观工具。
如果反向ETL工具提供实时数据关联并推送通知,则它使用变更数据捕获(CDC)。CDC是自动化的,可以实时处理数据存储中的变化。管道包括来自不同数据源的数据关联以及向业务应用程序发送实时推送消息。基于CDC的反向ETL需要可扩展、可靠的事件流基础设施。
众所周知,SQL和CDC方法都有自己的用例,有时在工具和基础设施方面有重叠。基于变更日志的CDC通常是首选的技术方法,而不是在重复计划中与SQL同步数据或在通过调用API触发时同步数据,无论是只使用事件流平台还是特定的Revere ETL产品。
然而,更重要的问题是如何设计企业架构来避免对反向ETL的需求。
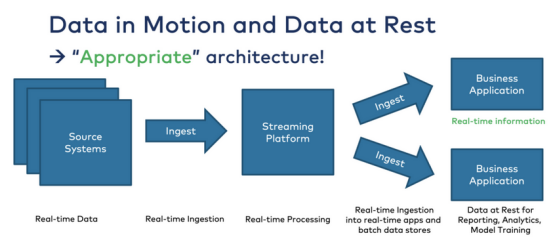
2.事件驱动架构+流式ETL==内置反向ETL
实时数据胜过处理过程较慢的数据。对于大多数用例来说都是如此。因此,事件驱动架构的兴起势不可挡:
现代事件驱动架构不需要反向ETL。它“内置”在开箱即用的架构中。如果合适且技术上可行,每个消费者都会直接实时消费数据。数据仓库或数据湖仍然以近乎实时或批量的方式按自己的节奏使用它:
Kafka原生的流式SQL引擎ksqlDB提供了CDC功能和连续流处理。因此,如果营销需要的急,甚至可以将ksqlDB称为反向ETL工具。
如果想了解有关构建实时数据平台的更多信息,人们可以查看一篇名为“Kappa架构是替代Lambda的主流”的文章。这篇文章探讨了Uber、Shopify和Disney等公司如何为任何用例构建事件驱动的Kappa架构,其中包括实时、近实时、批处理和请求响应。
什么时候需要反向ETL?
从头开始构建的以事件流平台为核心的全新架构不需要反向ETL来消费来自数据仓库或数据湖的数据,因为每个消费者已经可以实时消费数据。
然而,为业务用户提供接口并不能通过像Apache Kafka这样的事件流平台开箱即用地解决。而需要添加其他工具,例如Kafka CDC连接器或具有直观用户界面的第三方工具。因此,反向ETL可以在两种情况下提供帮助:棕地架构和面向业务用户的简单工具。
在棕地架构中的数据可以静态存储,业务人员需要在业务应用程序中使用它。对于销售、营销或客户成功用例,需要将数据从数据存储中推出:
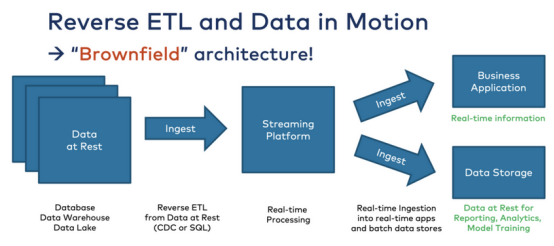
与传统的ETL和iPaaS解决方案相比,面向业务人员的简单集成工具更加直观且易于使用。即使采用全新的方法,反向ETL工具可能仍然是最简单的解决方案,并提供最佳的上市时间。
此外,需要记住的是,Salesforce或SAP等现代工具已经提供了基于事件的界面。Elastic、Splunk或Snowflake等数据存储供应商也在流媒体层上进行了大量投资,以与Apache Kafka等工具进行本地集成。与业务应用程序的集成可以通过实时事件流而不是通过来自数据存储的反向ETL进行集成。出于这些原因需要评估的业务问题,以及是否需要事件流平台、反向ETL工具或两者的组合。
反向ETL的Kafka示例
以下来看两个具体的例子。
1.Apache Kafka+Salesforce+Oracle CDC+Snowflake
以下架构结合了实时数据流、变更数据捕获、数据湖和反向ETL云服务:
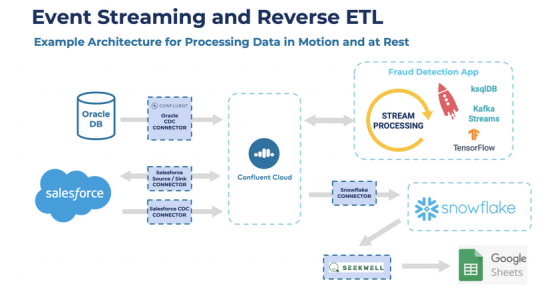
关于这个架构的一些注意事项:
- 中枢神经系统是一个事件流平台(Confluent Cloud),提供可扩展的实时数据流和任何数据源和接收器之间的真正解耦。
- SaaS云服务(Salesforce)为基于事件的实时集成提供了本地的异步API。
- 使用Confluent的Oracle CDC连接器用于Kafka Connect,通过更改数据捕获将传统关系数据库(Oracle)与反向ETL集成。
- 使用Kafka Streams和ksqlDB等流处理工具连续处理来自所有数据源的数据。
- 将数据摄取到数据仓库(Snowflake)中,该数据仓库配置为Confluent Cloud完全托管的Kafka Connect连接器的一部分。
- 业务用户利用专用的反向ETL解决方案(Seekwell)将数据从数据仓库(Snowflake)获取到业务应用程序(Google Sheets)中。
基础设施提供了一个基于事件的、可扩展的、可靠的实时神经系统。每个应用程序都可以实时使用和处理动态数据(如果需要)。静态数据存储是批处理用例的补充,并与基于事件的平台集成。
这种架构真正解耦了应用程序,避免了点对点的“意大利面条式”通信,并支持所有技术、云计算服务和通信模式。
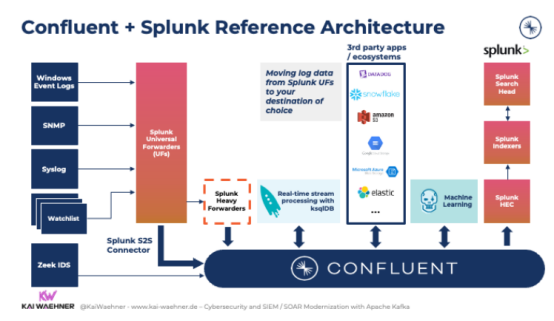
2.使用Kafka在动态中利用Splunk摄取层
避免存储系统需要反向ETL的另一个选择是利用现有的存储摄取层。
Confluent的Splunk S2S连接器就是一个很好的例子。假设企业已经拥有数百或数千个通用转发器(UF)和重型转发器(HF)。在这种情况下,这种方法允许用户经济高效且可靠地将数据从Splunk Forwarders读取到Kafka。它使用户能够将数据从通用转发器转发到Kafka主题中,以解锁数据的分析能力:
不要设计静态数据来反转
良好的企业架构不应该一开始就以规划反向ETL为目标。只有在数据静态存储的棕地架构中才需要它,而不是为实时和批量数据接收器构建基于事件的架构。反向ETL支持影子IT和意大利面条式架构。事件流本质上支持实时数据集成。
然而,反向ETL工具适用于棕地方法(在理想情况下通过持续更改数据捕获,而不是重复的SQL)或如果业务用户需要简单、直观的用户界面。因此,事件流和反向ETL是互补的。同样,事件流和数据仓库/数据湖是互补的。
原文标题:When to Use Reverse ETL and When It Is an Anti-pattern,作者:Kai Wähner
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】

















