













【51CTO.com快译】作为一名分析师,我花很多时间来跟踪新闻和行业最新资讯。我在休产假时考虑了这个问题,决定构建一个简单的应用程序来跟踪有关绿色技术和可再生能源的新闻。使用AWS Lambda及AWS的其他服务(比如EventBridge、SNS、DynamoDB和Sagemaker),可以非常轻松地上手,在几天内构建好原型。
该应用程序由一系列无服务器Lambda函数和作为SageMaker端点来部署的文本摘要机器学习模型提供支持。AWS EventBridge规则每24小时触发一次Lambda函数,从DynamoDB数据库获取新闻源(feed)。
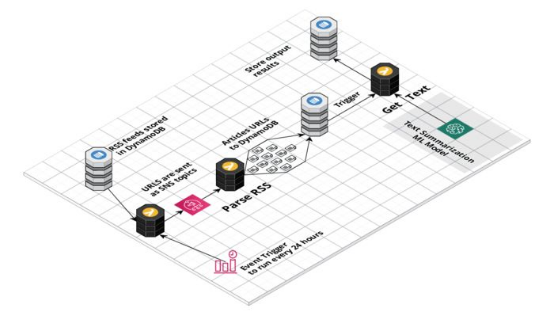
然后这些新闻源作为SNS主题来发送,以触发多个Lambda分析新闻源并提取新闻URL。每个网站每天更新RSS新闻源最多只更新几篇文章,因此我们不会发送大批流量,不然可能会导致消耗任何特定新闻出版物的过多资源。
然而,一大问题是提取文章的全文,因为每个网站不一样。对我们来说幸运的是,goose3之类的库通过运用机器学习方法提取页面正文来解决这个问题。由于版权问题,我无法存储文章的全文,这就是为什么我运用HuggingFace文本摘要转换器模型来生成简短摘要。
下面详细介绍了如何自行构建基于机器学习的新闻聚合管道。
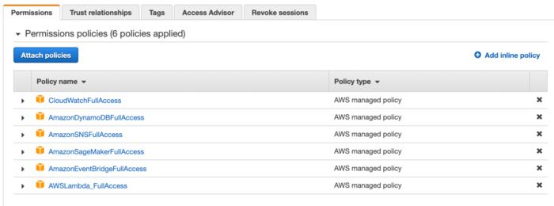
1. 设置拥有必要权限的IAM角色。
虽然这个数据管道很简单,但它连接许多AWS资源。想授予我们的函数访问所有所需资源的权限,我们需要设置IAM角色。该角色为函数赋予了使用云端其他资源的权限,比如DynamoDB、Sagemaker、CloudWatch和SNS。出于安全原因,最好不要为我们的IAM角色赋予全面的AWS管理访问权限,只允许它使用所需的资源。
2. 在RSS Dispatcher Lambda中从DynamoDB获取RSS新闻源
使用AWS Lambda几乎可以做任何事情,它是一种非常强大的无服务器计算服务,非常适合短任务。对我而言,主要优点在于很容易访问AWS生态系统中的其他服务。
我将所有RSS新闻源存储在DynamoDB表中,使用boto3库从Lambda访问它真的很容易。一旦从数据库获取所有新闻源后,我将它们作为SNS消息发送,以触发新闻源解析Lambda。
- import boto3
- import json
- def lambda_handler(event, context):
- # Connect to DynamoDB
- dynamodb = boto3.resource('dynamodb')
- # Get table
- table = dynamodb.Table('rss_feeds')
- # Get all records from the table
- data = table.scan()['Items']
- rss = [y['rss'] for y in data]
- # Connect to SNS
- client = boto3.client('sns')
- # Send messages to the queue
- for item in rss:
- client.publish(TopicArn="arn:aws:sns:eu-west-1:802099603194:rss_to-parse", Message = item)
3. 使用必要的库创建层
想在AWS Lambdas中使用一些特定库,您需要将它们作为层来导入。想准备库导入,它需要位于python.zip压缩包中,然后我们可以将其上传到AWS并在函数中使用。想创建层,只需cd进入到Python文件夹中,运行pip install命令,将其压缩并准备好上传。
- pip install feedparser -t
然而,我将goose3库作为一个层来部署时遇到了一些困难。简单的调查后发现,LXML等一些库需要在类似Lambda的环境(Linux)中加以编译。因此如果库在Windows上编译,然后导入到函数中,就会发生错误。为了解决这个问题,在创建压缩包之前,我们需要在Linux上安装该库。
这有两种方法。首先,安装在带有Docker的模拟Lambda环境上。对我来说,最简单的方法是使用AWS sam build命令。函数构建后,我只需从构建文件夹中拷贝所需的包,并将它们作为层来上传。
- sam build --use-container
4. 启动Lambda函数来解析新闻源
一旦我们将新闻URL作为主题发送到SNS,就可以触发多个Lambda从RSS新闻源去获取新闻文章。一些RSS新闻源不一样,但新闻源解析器库允许我们使用不同的格式。我们的URL是事件对象的一部分,所以我们需要通过key来提取它。
- import boto3
- import feedparser
- from datetime import datetime
- def lambda_handler(event, context):
- #Connect to DynamoDB
- dynamodb = boto3.resource('dynamodb')
- # Get table
- table = dynamodb.Table('news')
- # Get a url from from event
- url = event['Records'][0]['Sns']['Message']
- # Parse the rss feed
- feed = feedparser.parse(url)
- for item in feed['entries']:
- result = {
- "news_url": item['link'],
- "title": item['title'],
- "created_at": datetime.now().strftime('%Y-%m-%d') # so that dynamodb will be ok with our date
- }
- # Save the result to dynamodb
- table.put_item(Item=result, ConditionExpression='attribute_not_exists(news_url)') # store only unique urls
5. 在Sagemaker上创建和部署文本摘要模型
Sagemaker是一项服务,可让您轻松在AWS上编写、训练和部署机器学习模型。 HuggingFace与AWS合作,使用户更容易将其模型部署到云端。
这里我在Jupiter notebook中编写了一个简单的文本摘要模型,并使用deploy()命令来部署它。
- from sagemaker.huggingface import HuggingFaceModel
- import sagemaker
- role = sagemaker.get_execution_role()
- hub = {
- 'HF_MODEL_ID':'facebook/bart-large-cnn',
- 'HF_TASK':'summarization'
- }
- # Hugging Face Model Class
- huggingface_model = HuggingFaceModel(
- transformers_version='4.6.1',
- pytorch_version='1.7.1',
- py_version='py36',
- env=hub,
- role=role,
- )
- # deploy model to SageMaker Inference
- predictor = huggingface_model.deploy(
- initial_instance_count=1, # number of instances
- instance_type='ml.m5.xlarge' # ec2 instance type
- )
一旦部署完毕,我们可以从Sagemaker -> Inference -> Endpoint configuration获取端点信息,并用在我们的Lamdas中。
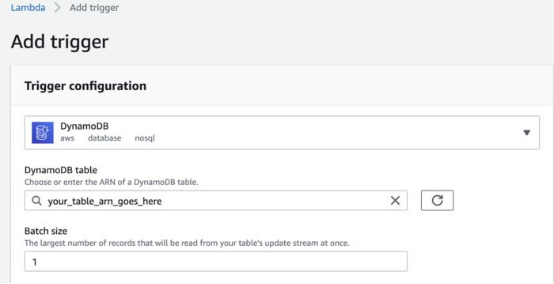
6. 获取文章的全文、摘要文章并将结果存储在DynamoDB中
由于版权我们不会存储全文,这就是为什么所有处理工作都在一个Lambda中进行。一旦URL进入到Dynamo DB表,我启动了文本处理Lambda。为此,我创建了DynamoDB项生成,作为启动Lambda的触发器。我创建了批大小,那样Lambda每次只处理一篇文章。
- import json
- import boto3
- from goose3 import Goose
- from datetime import datetime
- def lambda_handler(event, context):
- # Get url from DynamoDB record creation event
- url = event['Records'][0]['dynamodb']['Keys']['news_url']['S']
- # fetch article full text
- g = Goose()
- article = g.extract(url=url)
- body = article.cleaned_text # clean article text
- published_date = article.publish_date # from meta desc
- # Create a summary using our HuggingFace text summary model
- ENDPOINT_NAME = "your_model_endpoint"
- runtime= boto3.client('runtime.sagemaker')
- response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME, ContentType='application/json', Body=json.dumps(data))
- #extract a summary
- summary = json.loads(response['Body'].read().decode())
- #Connect to DynamoDB
- dynamodb = boto3.resource('dynamodb')
- # Get table
- table = dynamodb.Table('news')
- # Update item stored in dynamoDB
- update = table.update_item(
- Key = { "news_url": url }
- ,
- ConditionExpression= 'attribute_exists(news_url) ',
- UpdateExpression='SET summary = :val1, published_date = :val2'
- ExpressionAttributeValues={
- ':val1': summary,
- ':val2': published_date
- }
- )
这就是我们如何使用AWS工具,构建并部署一个简单的无服务器数据管道以读取最新新闻的过程。
原文标题:Build a Serverless News Data Pipeline using ML on AWS Cloud,作者:Maria Zentsova
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】



















