在日常工作中,我们通常需要存储一些日志,譬如用户请求的出入参、系统运行时打印的一些 info、error 之类的日志,从而对系统在运行时出现的问题有排查的依据。
图片来自 包图网
日志存储和检索是个很常见且简单的工作,市面也有很多关于日志搜集、存储、检索的框架可供使用。
譬如我们只有个位数机器时,可以通过登录服务器,查看 Log4j 之类的框架打印到本地文件的日志。当日志多起来后,可以用 ELK 三剑客处理日志。
当日志量进一步增多,我们可以上消息队列,譬如 Kafka 之类来承接,然后消费入库。或者写本地文件,再采用 Filebeat 之类上报再入库。
以上都是较为常见的日志传输和存储的方案,成本可控的情况下,可适用于绝大多数场景。
我们可以简单总结一下日志框架的功能,大概是暂存、传输、入库保存、快速检索。
量级上升,成本高昂
技术方案的设计和取舍,往往强受限于成本。当成本高企到难以承受时,将必须导致技术方案的升级换代。那么问题来了,我就是存个日志而已,怎么就成本难以承受了呢?
我们以一个常见的日志传输及存储方案来举例,如下图,暂存就是采用客户端写本地文件存日志,传输即是采用 MQ,消费入库常见的如 ES。
下图方案,为了减少部分存储成本,将日志详情存储于压缩更好的 Hbase,仅将查询时需要的一些索引字段放在了 ES。
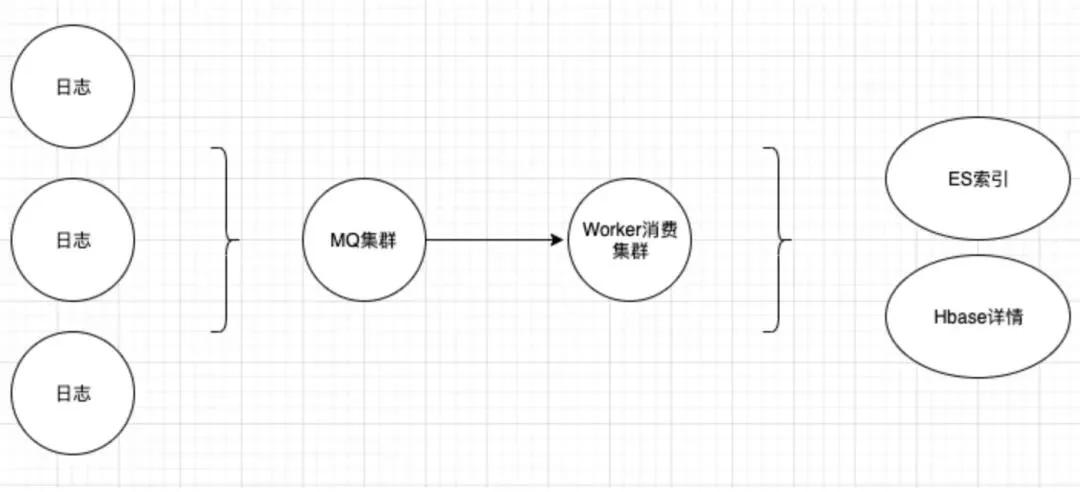
以上作为一个常用的方案,为什么会成本高昂呢?
我们来简单计算一下,京东 App 某个模块(是一个模块,非整个 App 累计),单次用户请求,用户的入参+返回值+流程中打印的日志占用的大小在 40k-2M 之间,中位数在 60k 左右。
该模块日常每秒约 2-5 万次访问,高峰时会翻 10 倍,极高峰可达百万。
以 3 万每秒来算,产生的日志大小为 1.8G,也就是说即便是低负载时,这个日志框架要吞下 1.8G 的传输与存储。
但这是远远不够的,因为我们即便放弃极高峰,仅仅支撑偶现的高峰,也需要该系统能支撑秒级 15G 以上的吞吐。但是这仅仅才是一个模块而已,算上前中台这样的模块还有很多。
那么我们就可以来算一算了,一秒 1.5 G,一个小时就是 5.4TB。小高峰是肯定要支撑的,也就是秒级 30 万是要保的,那么我们的系统就要能支撑秒级 15G 单模块,算上各模块,200G 秒级是跑不了了。
这只是各个机器所打印在各自本地的原始日志文件占用的大小,然后要发到 MQ 集群。
大家都知道,MQ 也是写磁盘的,这 200G 一点不少的在 MQ 机器上做了保存,并且 MQ 还有备份机制。
就以最简陋的单备份来说,MQ 每秒要承接 400G 的磁盘,并且离删除后释放磁盘还有挺长一段时间,哪怕只存 1 个小时,也是一个巨大的数字。
我们知道,一般服务器在磁盘还不错的情况下,单机秒级写入量 200 多 M 算比较不错的情况,通过上面的了解,我们仅仅做到日志的暂存和传输就需要 2000 台以上的服务器资源。
然后就到了 worker 消费集群,该集群只是纯粹的内存数据交换,不占磁盘,worker 消费后写入数据库。大家基本可以想象到,数据库的占用是如何。
OK,我们终于把数据存了进去,查询问题就成了另外一个必须面对的事情,如何快速从无数亿中找到你要查询的那个用户的链路日志。
到了此时,成本就成了非常要命的事情,尤其方案的设计,会导致原本就很庞大的数据,在链路上再次放大多倍,那么巨大的硬件成本如何解决。
缩短流程,缩减流量
通过上面的分析,我们已经发现,即便是市面上最通用的日志方案,在如此巨大的流量面前,也难以持续下去,高昂的硬件成本,将迫使我们去寻找更合适的技术方案。
世界上有一个著名的法则叫"奥卡姆剃刀定律",讲的是程序员该如何选择合适的剃刀,来让自己的秀发光滑柔顺有光泽。
其实不是的,该定律主要就是八个字"如无必要,勿增实体"。当一个流程难以支撑当前的业务时,我们就该审视一下,哪些步骤是不必要的。
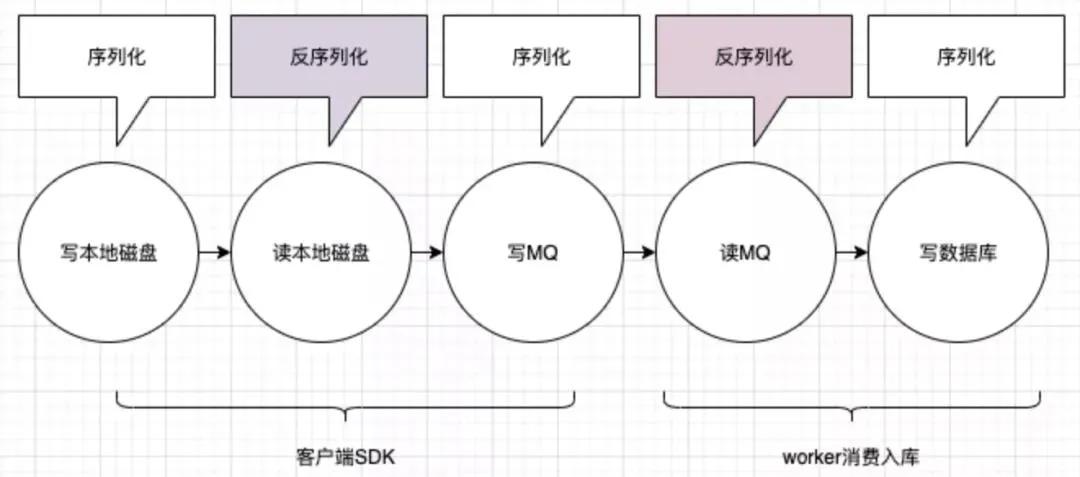
从这个通用流程中,其实我们很容易就能发现,我们经历了很多读写,每次读写都伴随着磁盘的读写(包括 MQ 也是写磁盘的),和频繁的序列化反序列化,以及翻倍的网络 IO。
那么让我们挥舞起奥卡姆的剃刀,做一些删减,把非必要的部分给删掉,就变成了下图的流程:
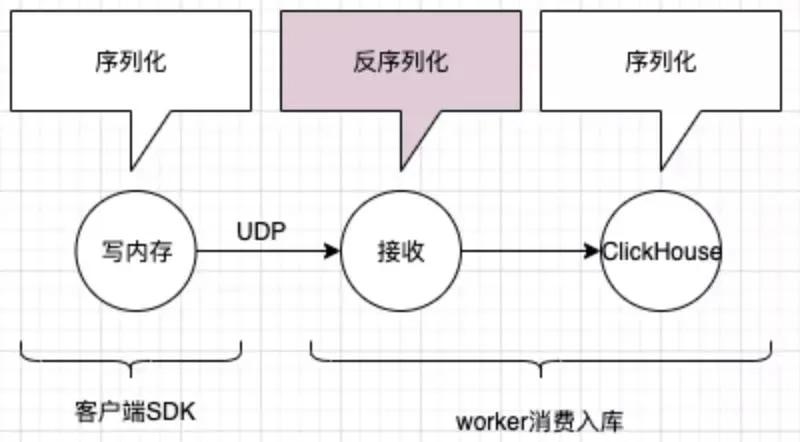
我们发现,其实写本地磁盘、和 MQ 都是没有必要的,我们完全可以将日志数据写到本地内存,然后搞个线程,定时通过 UDP 将日志直接发送到 worker 端即可。
worker 接收到之后,解析一下,写入自己的内存队列,再起数个异步线程,批量将队列的数据写入 ClickHouse 数据库即可。
大家可能看到了,下图的流程中,那个圆圈明显比上图的圆圈要小,这是为什么呢?因为我做了压缩。
前文讲过,我们单条报文 40k-2M,这是一个非常大的报文,这里面都是一些用户请求的入参 Json 和出参 Json 以及一些中途日志,我们完全没有必要将原文原封不动往外传输。
通过采用主流的 snappy、zstd 等压缩工具类,可以直接将字符串压缩成 byte[] 再往外传输,这个被压缩后的字符串,直至入库都是 byte[],全程不对大报文解压。
那么这个压缩能压多少呢,80%-90%,一个 60k 的报文,往外送时就剩 6-8k 了,可想而知,仅仅压缩一下原始数据,就在整个流程中,节省了巨大的带宽,同时也大幅提升了 worker 的吞吐量。
这里有个小细节,udp 单个最大报文是 64kb,如果我们压缩后,还是超过了 64kb 的话,udp 是送不出去的,这里可以选择发个 http 请求送到 worker 即可。
通过上图,我们可以看到,当流程中的某些环节并不是必需的时,我们应该果断砍掉,不要轻易照搬网上的方案,而应该选择更适合自己的方案。下面我们详细讲一下系统是如何设计、运转的。
更强悍的日志搜集系统
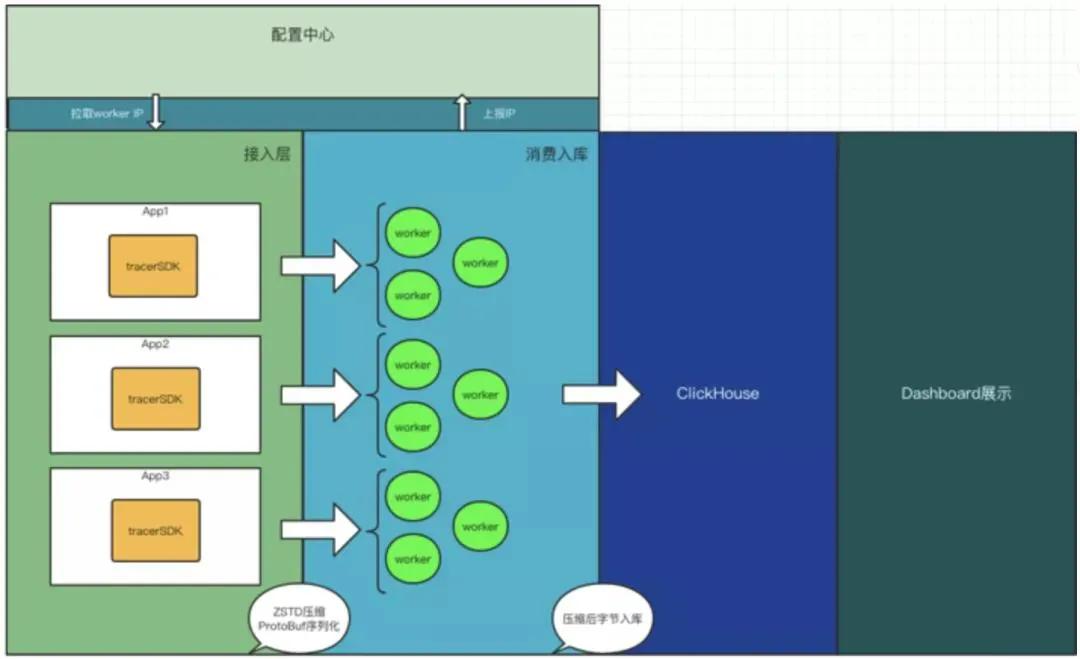
我们来审视一下这个链路极短的日志搜集系统:
- 配置中心:用来存储 worker 的 IP 地址,供客户端获取自己模块所分配的 worker 集群的 ip。
- client:客户端启动后,从配置中心拉取分配给自己这个模块的 worker 集群的 IP,并轮询将搜集的日志压缩后发送过去,通过 UDP 的方式。
- worker:每个模块会分配数量不等的 worker 机器,启动后上报自己的 IP 地址到配置中心。接受到客户端发来的日志后,解析相应的字段,批量写入 clickhouse 数据库。
- clickhouse:一个强大的数据库,压缩比很高,写入性能极强,按天分片,查询速度佳。非常适合应用于日志系统这种写入极大,查询较少的系统。
- dashboard:可视化界面,从 clickhouse 查询数据展示给用户,具有多条件多维度查询功能。
大家都能看出来,这其中最关键的地方是 worker 端,它的承接流量、消费性能、入库性能将决定着整个链路能否良好地运转。
我们主要分别讲解一下 client 端和 worker 端的实现。
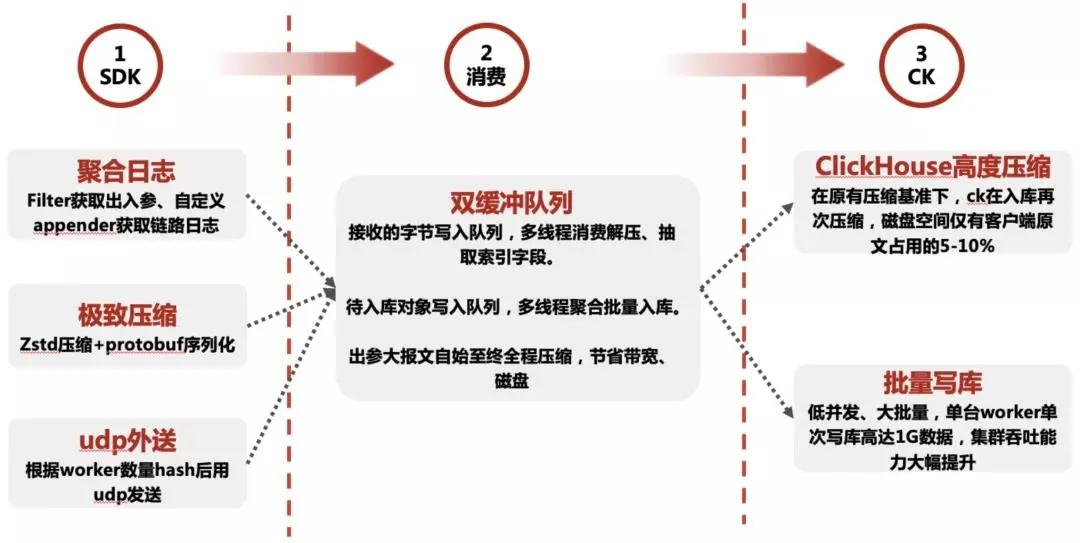
Client 端聚合日志
一次请求中,我们通常要保留的日志信息主要有:
①请求的出入参
如果是 http web 应用,要获取出入参比较简单的方式就是通过自定义 filter 即可。client 的 sdk 里定义了一个 filter,接入方通过配置该 filter 生效即可搜集到出入参。
如果是其他 rpc 应用非 http 请求的,也提供了对应的 filter 拦截器来获取出入参。
在获取到出入参后,sdk 对其中大报文,主要是出参进行了压缩,并将整个数据定义为一个 Java 对象,做 protobuf 序列化,通过 UDP 方式往自己对应的 worker 集群轮询传输。
②链路上自己打印的一些关键信息,如调用其他系统的的出入参,自己打印的一些 info、error 信息
sdk 分别提供了 log4j、logback、log4j2 三个常用日志框架的自定义 appender。
用户可以通过在自己的日志配置文件(如 logback.xml)中,将我自定义的 appender 定义出来即可,那么后续用户在代码里所有打印的 info、error 等日志都会执行这个自定义 appender。
同样,这个自定义 appender 也是将日志暂存内存,然后异步 UDP 外送到 worker。
这里主要有两个地方需要注意,一是当压缩后的报文依旧超出 udp 最大报文值时,即通过 http 送出。
二是这一次请求,链路中可能会使用多线程、线程池技术,为避免链路 tracer 的唯一 id 在线程池丢失,sdk 采用了 TransmittableThreadLocal 来保持链路的 ID,这个查一下就懂。
总体来说,client 端实现较为简单,省略了写本地磁盘、消费文件发 MQ 等等步骤。
整体只有一次 Protobuf 序列化操作,对 CPU、接入方性能影响极小,采用 UDP 外送,不需要 worker 的任何回复,也不用考虑 tcp 模式下 worker 消费慢导致自己阻塞的问题。整体非常简洁高效。
Worker 端消费日志并入库
worker 端是调优的重点,由于要接收海量客户端发来的日志,解析后入库,所以 worker 需要具备很强的缓冲能力。
我们都能看出来,系统的瓶颈点肯定在入库这个阶段,解析日志,抽取字段都是效率很高的,而且完全可以通过控制线程的数量来控制住,而入库将强受限于 clickhouse 的写入性能。
至于 clickhouse 是如何做的优化,后面会有 clickhouse 集群负责人来讲一下做了哪些优化。
为了做好这个缓冲,即便日志接收量大于入库量,我们也要能接下来这些数据,尽量不丢失。
首先硬件上,采用大内存机器,8 核 32G 的容器,来尽量多屯一些数据。其次,采用了双缓冲队列,先将所有接收的数据放一个队列,然后多线程消费、解析成可供入库的行数据,再放入一个待入库队列,然后批量入库。
那么我们做的这些操作,能支撑什么样的数据量呢?
通过线上的应用和严苛的压测,这样一台单机 docker 容器,每秒可以处理原始日志 1-5 千万行。
譬如一条用户请求,中途产生了共计 1 千多行日志,那么这样的一台 worker 单机,每秒可以处理 2 万客户端 QPS。对外写 clickhouse 数据库,每秒可以写 160M-200M 比较稳定。
通过对上文的了解,我们知道,这些数据都是被压缩过的,直至库里面的都是压缩过的,只有当最终用户查询时,才会进行解压。所以,这 200M,基本相当于原始数据 1G 多的大小。
也就是说,只要 clickhouse 写入速度跟的上,这个系统仅需 100 台就可以极其高效地处理原始秒级百 G 的日志。
对比写 MQ 的方案,中途所有会出现瓶颈的点如 MQ 写磁盘速度、消费拉取速度等,都将不复存在。这是一个纯内存交换的链路系统。
强悍的 Clickhouse
通过以上的了解,我们可以清楚的看到,worker 作为一个纯内存计算的组件,client 端通过 worker 的数量进行 hash 均匀分发到各个 worker。
所以 worker 可以动态扩容而且不存在性能瓶颈,其唯一受限制的就是写入库的速度。
倘若写库速度跟不上,则 worker 必须要拿有限的内存去屯下发来的大量数据,一旦写满则就会开始丢弃接收到的数据。所以整个系统的瓶颈点,就是写库的速度。
Clickhouse 是面向海量数据实时、多维分析、高性能的新一代 OLAP 数据库管理系统,实现了向量化执行和 SIMD 指令,对内存中的列式数据,一个 batch 调用一次 SIMD 指令,大幅缩短了计算耗时,带来数倍的性能提升。
目前已成为驱动京东集团业务增长、创新的“超级引擎”。那么在京东 App 秒级百 G 日志传输存储架构中,Clickhouse 如何支撑大吞吐量数据的写入?
主要在于以下两点:
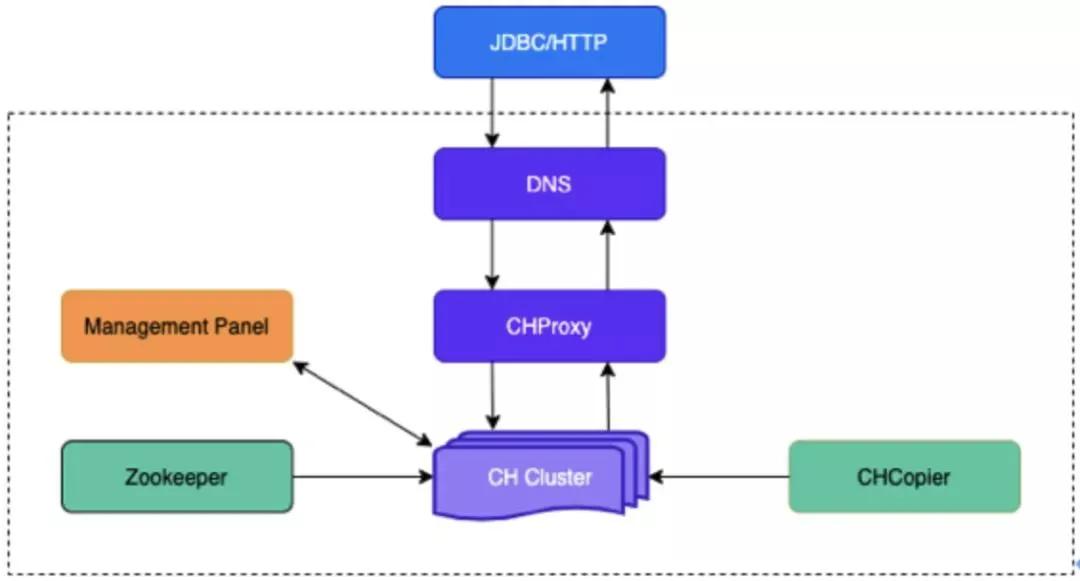
①集群高可用架构
EasyOLAP 部署 CH 集群是三层结构:域名+CHProxy+CH 节点,域名转发请求到 CHProxy,再由 CHProxy 根据集群节点状态来转发。
CHProxy 的引入是为了让 Query 均匀分布在每个节点上,,并对 CHProxy 做了一定的改进,自动感知集群节点的状态变化。
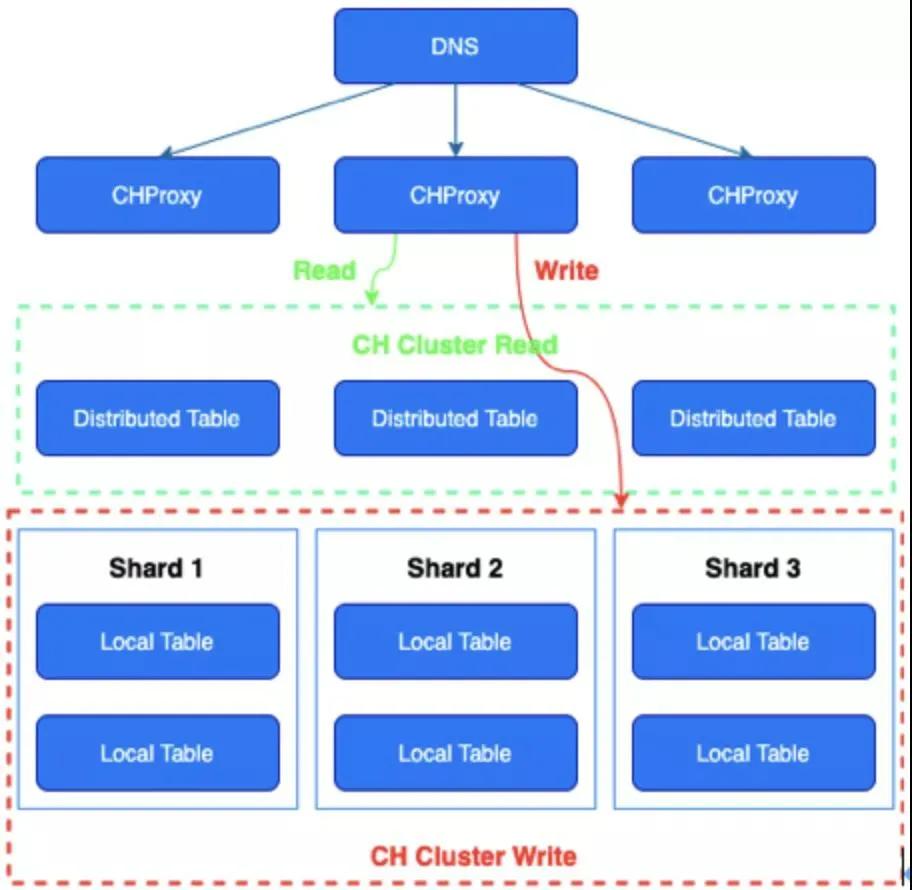
②本地表写入
大吞吐量的数据写入分布式表时,分布式表会将接收的 insert 数据拆分成多个 parts,并通过 rand 或者 shard_key 方式转发到各个分片。
这会引起 ch 节点网络带宽和 merge 的工作量增加,导致写入性能下降,并且会增加 too many parts 的风险和加大 zookeeper 的压力。
另外数据会在分布式表所在节点进行临时落盘,然后异步的发送到本地表所在的节点进行物理存储,中间没有一致性校验,如果分布式表所在的节点出现故障,会存在数据丢失的风险。
所以针对以上风险,大吞吐量的数据可直接写入本地表,相较于写入分布式表可以大幅度提升 2-3 倍的写入性能。
多条件查询控制台
控制台比较简单,主要就是做一些 sql 语句查询,做好 clickhouse 的高效查询,这里简单提一些知识点。
做好数据的分片,如按天分片。用好 prewhere 查询功能,可以带来性能的提升。做好索引字段的设计,譬如检索常用的时间、pin。
细节难以尽述,要从百亿千亿数据中,做好极速的查询,还需要对 clickhouse 的一些查询特性有所了解。
下图界面展示的即为一些索引项,点击查看详情,则从数据库捞出压缩过的数据,此时才解压并展示给前端。查看链路,则是该次请求中,整个链路用户打印的 log(包括线程池内的)。
总结与对比
我们可以简单的做一些对比,主要在于硬件成本和软件性能的对比。
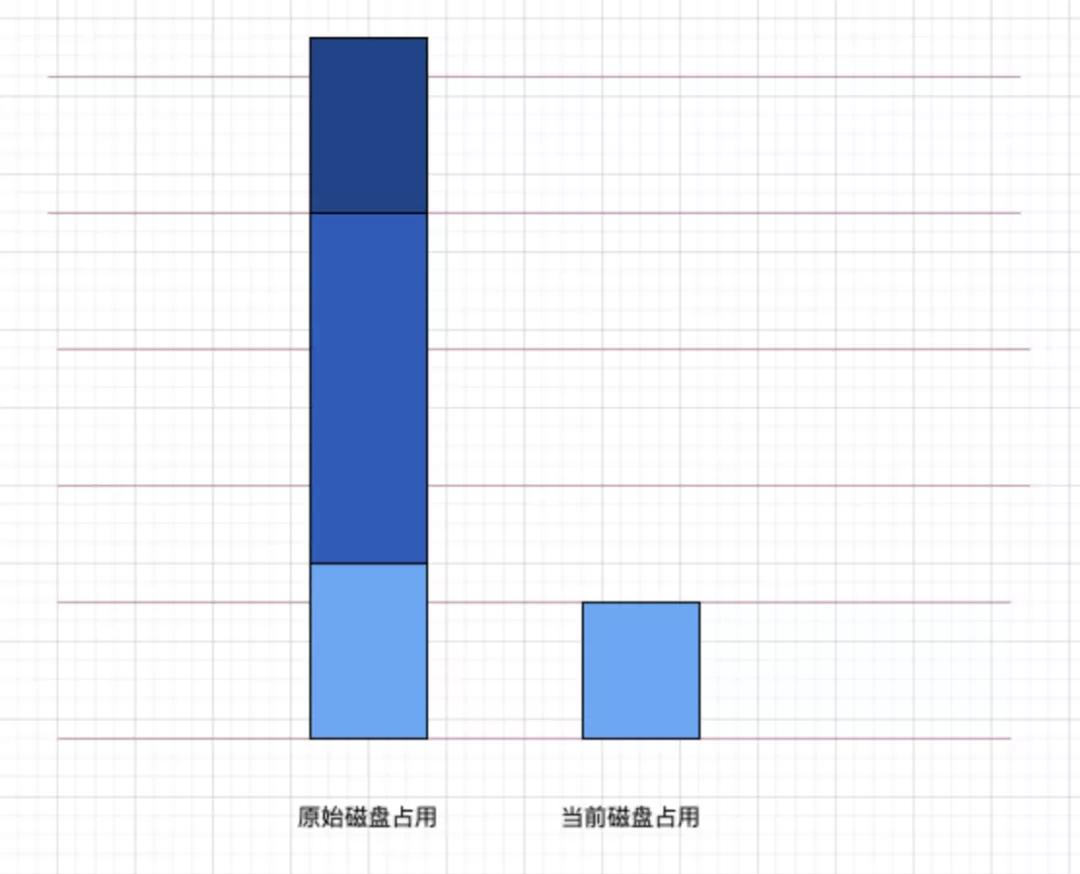
从上文可知,磁盘的占用原始方案占用了磁盘(1 份),MQ(2 份),数据库(1 份)。
而在新的方案中,磁盘的占用仅剩下 clickhouse 的(0.8 份),clickhouse 自身又对数据做了压缩,实际占用空间不到入库容量的 80%。那么仅磁盘即可节省 75% 以上的存储成本。
大家都知道,秒级的吞吐量,是伴随着服务器 CPU 的耗费的,并不是说只给个大硬盘,即可一台服务器每秒吞吐 1 个 G 的。
每台服务器秒级的吞吐量是有上限的,秒级占用磁盘的上升,即对应 CPU 数量的上升,要支撑一秒 1G 的磁盘写入,需要 5 台或以上的服务器。
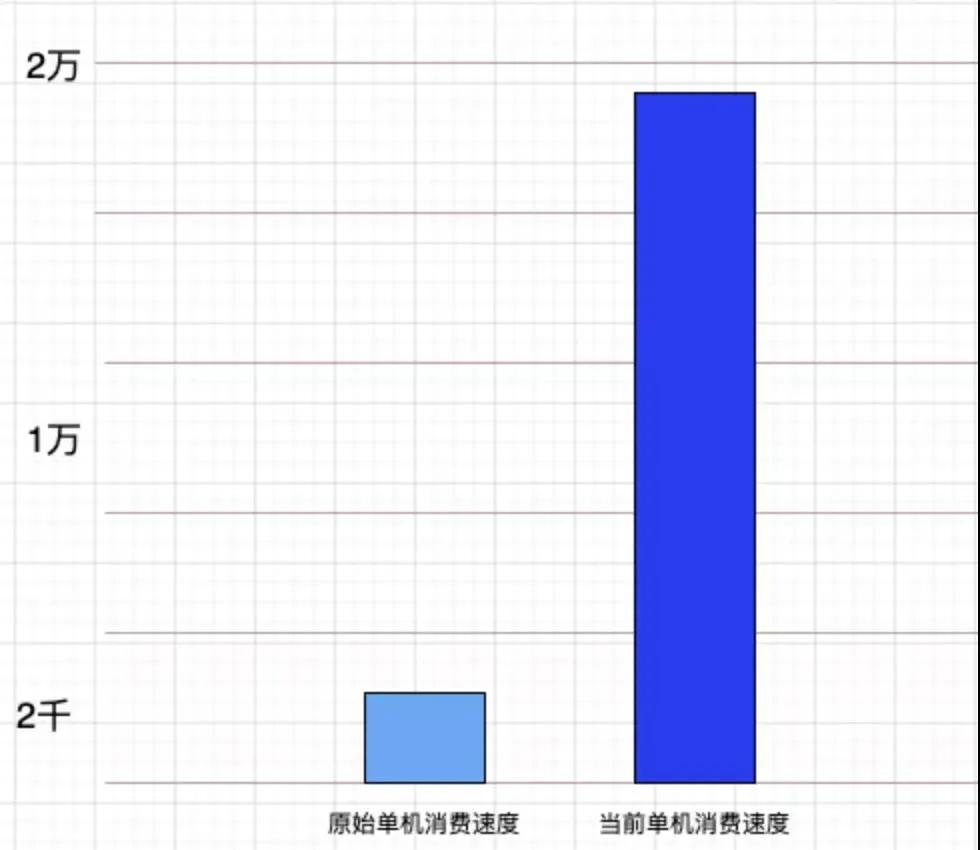
那么在磁盘的大幅节约下,线性地节省了大量的中间过程 CPU 服务器。实际粗略统计效果,流程中服务器可节约 70% 以上。
在软件性能上,过程很好理解。对 Client 端的消耗主要就是序列化、写磁盘、读磁盘、反序列化这几步的消耗,Udp 则仅有一步序列化。
我们假设 MQ 集群是有无限的写入能力,可以吞下所有的发过去的日志,那么就是 worker 端的消费性能对比。
从 MQ 拉取并消费,这个过程如果 MQ 没有积压,则有零拷贝在支撑高速的拉取,如果积压了,则可能产生大量的 MQ 磁盘 IO,拉取速度会大幅下降。
这个过程效率会明显低于 Udp 发送到 worker 的处理效率,而且占用双份的网络带宽。
实际表现上,worker 表现出的强劲性能,较之前单条拉取 MQ 集群时,消费性能提升在 10 倍以上。
本文到此就结束了,主要简略介绍了一个新的日志搜集系统的设计方案,以及该方案能带来的巨大的成本节省。
作者:武伟峰、李阳
编辑:陶家龙
来源:转载自公众号京东零售技术(ID:jd-sys)