在实现复杂且高精度图像编辑效果的同时,EditGAN 还能保持较高的图像质量和对象身份,英伟达在图像处理领域果然「出手不凡」。
当前,AI 驱动的照片和图像编辑技术有助于简化摄影师和内容创作者的工作流程,并赋能更高水平的创意和数字艺术。基于 AI 的图像编辑工具也已经以神经照片编辑过滤器(filter)的形式应用在消费级软件上,并且深度学习研究社区积极地开发新的技术。其中,各式各样基于生成对抗网络(GAN)的模型和技术层出不穷,在实现原理上,领域研究人员要么将图像嵌入到 GAN 的隐空间,要么直接使用 GAN 生成图像。
大多数基于 GAN 的图像编辑方法分为以下几类。一些工作依赖于 GAN 在类标签或像素级语义分割注释上发挥作用,不同的条件会使输出结果出现变动;另一些工作使用辅助的属性分类器来指导图像的合成和编辑。然而,训练这种条件式 GAN 或外部分类器需要大规模的标注数据集。因此,这些方法目前仅适用于拥有大规模标注数据集的图像类型,如肖像等。即使拥有足够注释的数据集,大多数方法也仅能提供有限的编辑控制,这是因为这些注释通常仅包含高级的全局属性或者比较粗糙的像素级分割。
另一些方法专注于对不同图像的特征进行混合和插值,因此需要参照图像作为编辑目标,通常也无法提供微调控制。还有一些方法仔细剖析 GAN 的隐空间,找出适合编辑的解耦隐变量或者控制 GAN 的网络参数。但遗憾的是,这些方法无法实现精细的编辑,速度也通常较慢。
近日,英伟达、多伦多大学等机构在论文《EditGAN: High-Precision Semantic Image Editing》中克服了这些局限,并提出了一个全新的基于 GAN 的图像编辑框架 EditGAN——通过允许用户修改对象部件(object part)分割实现高精度的语义图像编辑。
相关研究已被 NeurIPS 2021 会议接收,代码和交互式编辑工具之后也会开源。

论文地址:https://arxiv.org/pdf/2111.03186.pdf
项目主页:https://nv-tlabs.github.io/editGAN/
具体而言,EditGAN 在最近提出的 GAN 模型基础上构建,不仅基于相同的潜在隐编码来共同地建模图像及其语义分割,而且仅需要 16 个标注示例,从而可以扩展至很多目标类和部件标签。研究者根据预期编辑结果来修改分割掩码,并优化隐编码以与新的分割保持一致,这样就可以高效地改变 RGB 图像。
此外,为了实现效率,他们通过学习隐空间中的编辑向量(editing vector)来实现编辑,并在无需或仅需少量额外优化步骤的情况下直接在其他图像上应用。因此,研究者预训练了一个感兴趣编辑的库以使得用户可以在交互工具中直接使用。
研究者表示,EditGAN 是首个同时实现以下目标的 GAN 驱动的图像编辑框架:
提供非常高精度的编辑;
仅需极少量的标注训练数据,并且不依赖额外的分类器;
实时交互运行;
多个编辑的直接语义合成;
在真实的嵌入式、GAN 生成的甚至域外(out-of-domain)图像上运行。
研究者在包括汽车、猫、鸟和人脸等在内的广泛图像上应用了 EditGAN,最终都展现出了前所未有的高精度编辑。他们还将 EditGAN 与多个基准方法进行定量比较,并在身份和质量保持、目标属性准确性等指标上胜过它们,同时需要的标注训练数据少了数个量级。
在项目主页中,研究者展示了多个 EditGAN 相关的 Demo 视频,如下动图(左)为编辑向量插值效果,图(右)为在域外图像上应用 EditGAN 编辑向量的效果。

下图(左)为交互 demo 工具中使用 EditGAN 的效果,图(右)为使用 EditGAN 时可以实现多个编辑和预定义编辑向量。
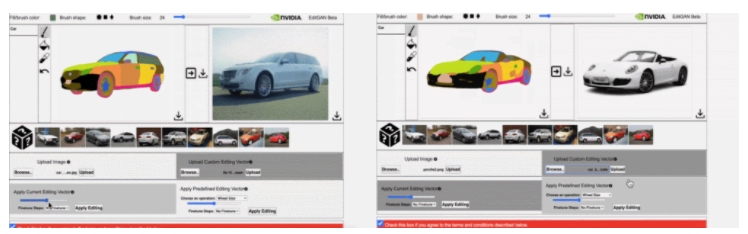
使用 EditGAN 如何完成高精度语义图像编辑?
下图 2(1)为训练 EditGAN 的流程;图 2(2&3)分别为编辑分割掩码和利用编辑向量的实时编辑,其中用户可以修改分割掩码,并由此在 GAN 的隐空间中进行优化以实现编辑;图 2(4)为在隐空间中学习编辑向量,用户通过应用以往学习到的编辑向量进行编辑,并可以交互式地操纵图像。
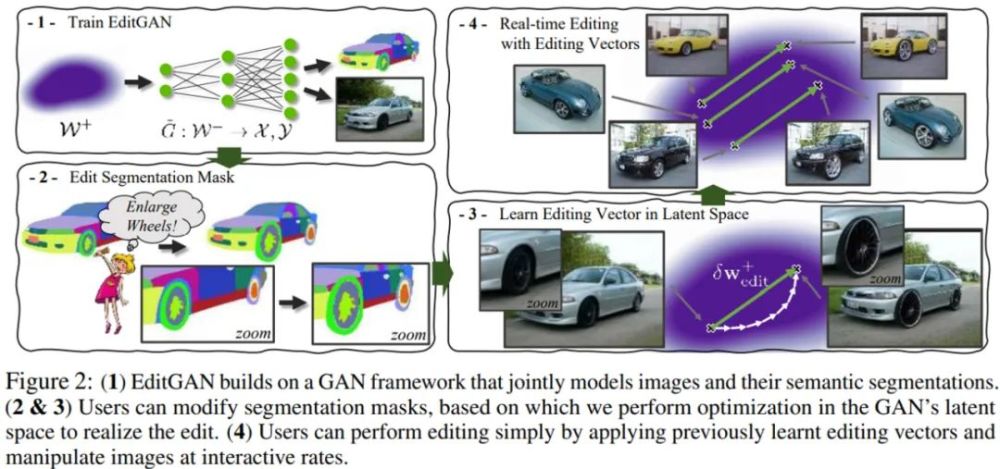
通过分割编辑在隐空间中找出语义
EditGAN 的核心思想是在实现高精度图像编辑中利用图像和语义分割的联合分布 p(x, y)。给定一张待编辑的新图像 x,我们可以将它嵌入到 EditGAN 的 W^+ 隐空间中。然后,分割部分将生成相应的分割 y,这是因为分割和 RGB 图像共享相同的隐编码 w^+。使用简单的交互式数字绘画或标注工具,即可根据预期的编辑手动修改分割。研究者将编辑的分割掩码表示为了 y_edited。
例如,当修改右侧汽车照片中的车轮时,Q_edit 将包含轮胎、辐条和轮毂等所有与车轮相关的零件的标签:
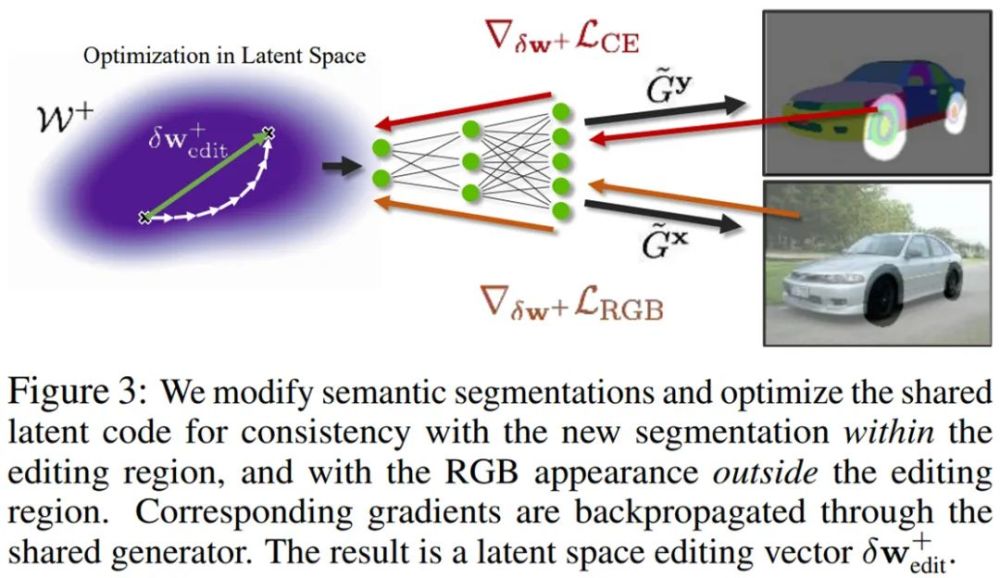
推理过程中不同的编辑方法
总的来说,我们可以通过以下三种不同的模式使用 EditGAN 进行图像编辑:
使用编辑向量进行实时编辑。对于局部解耦良好的编辑,仅通过应用先前学习的具有不同尺度的编辑向量即可进行编辑,并以交互式速率(interactive rate)操纵图像;
利用自监督细化的向量编辑。对于未与图像其他部分完美解耦的局部编辑,可以通过测试过程中的额外优化去除编辑伪影,同时使用学习到的向量初始化编辑;
基于优化的编辑。特定图像和大规模的编辑不能通过编辑向量迁移到其他图像。对于此类操作,则可以从零开始进行优化。
实验结果
在实验部分,研究者在四种不同类别的图像上对 EditGAN 进行了广泛的评估,它们分别是:
汽车(空间分辨率 384×512)
鸟(512×512)
猫(256×256)
人脸(1024×1024)
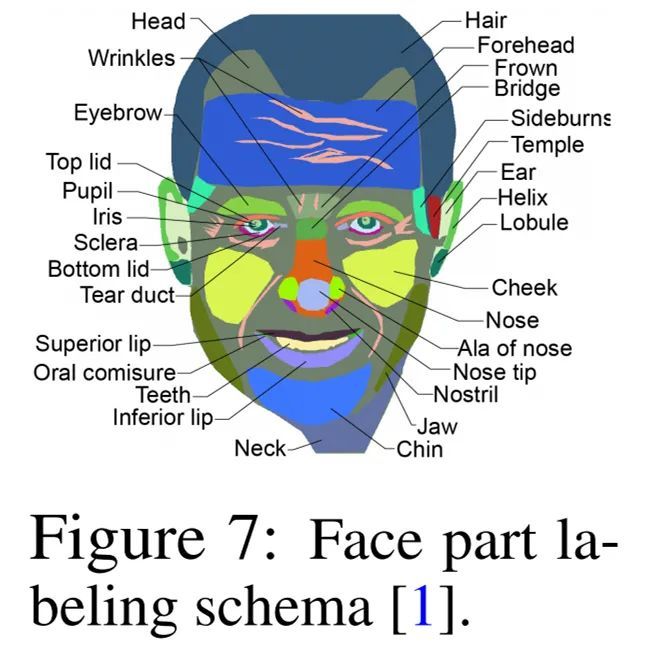
其中,人脸示例的注释细节如下图 7 所示:
当仅基于优化或通过学习编辑向量完成编辑时,研究者通常使用 Adam 执行 100 steps 的优化。对于汽车、猫和人脸,他们使用 DatasetGAN 测试集中的真实图像,使用这些非 GAN 训练数据的图像是为了验证编辑功能;对于鸟,他们在 GAN 生成的图像上展示编辑功能。
定性结果
首先来看域内(in-domain)结果。在下图 4 中,研究者展示了当在新图像上应用以往学习到的编辑向量并执行 30 steps 的优化细化时,EditGAN 框架的图像编辑效果。结果显示,使用 EditGAN 的编辑操作保持了高图像质量并对所有类别的图像实现了良好的解耦。
研究者表示,以往没有任何一种方法可以做到像 EditGAN 那样复杂且高精度的编辑,同时还能保持较高的图像质量和对象身份。

如下图 8 所示,使用 EditGAN,研究者甚至可以实现极高精度的编辑,例如旋转汽车的轮辐(左)或者扩大人的瞳孔(右)。EditGAN 可以对那些像素极少对象的语义部分进行编辑,同时还能实现大规模的修改。

在下图 9 中,研究者展示了仅通过修改分割掩码和优化即可以去除汽车的车顶或将其改装成旅行车。值得注意的是,通过一些编辑操作生成的图像与 GAN 训练数据中出现的图像不同。

其次是域外结果。研究者在 MetFaces 数据集上展示 EditGAN 对域外数据的泛化能力。他们使用在 FFHQ 上训练的 EditGAN 模型,并使用域内真实人脸数据创建编辑向量。接着嵌入域外 MetFaces 肖像(使用 100 steps 的优化),再通过 30 steps 的优化应用编辑向量。结果如下图 6 所示,该研究的编辑操作无缝地迁移至相差甚远的域外图像示例。

定量结果
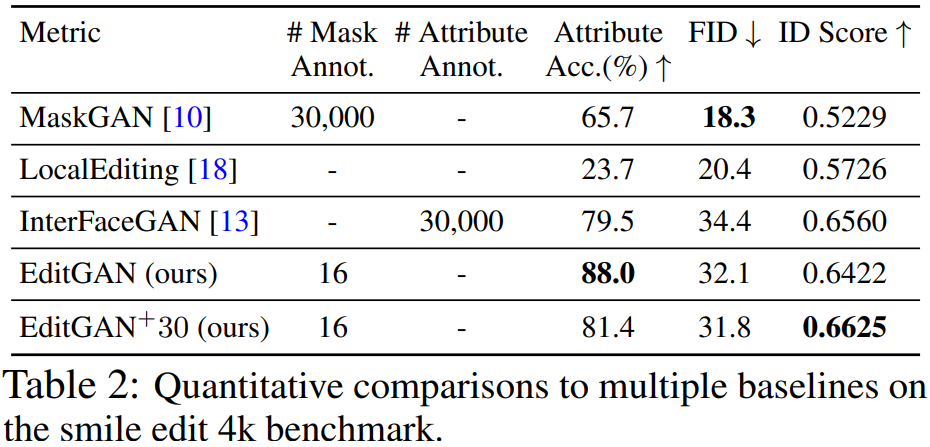
为了展示 EditGAN 的图像编辑能力的定量评估结果,研究者使用了 MaskGAN 引入的笑脸编辑(smile edit)基准。中性表情的人脸被转换为笑脸,并使用以下三项指标对性能进行度量,它们分别是:
语义正确性(Semantic Correctness)
分布级图像质量(Distribution-level Image Quality)
身份保持(Identity Preservation)
研究者将 EditGAN 与三个强基准方法进行比较,分别是 MaskGAN2、LocalEditing 和 InterFaceGAN,最后还与 StyleGAN2 蒸馏做了比较。结果如下表 2 所示,EditGAN 在三项指标上均优于其他方法。此外,EditGAN 在身份保持和属性分类准确率方面也优于 InterFaceGAN。在与 StyleGAN2 蒸馏的比较中,EditGAN 也表现出了强大的性能。
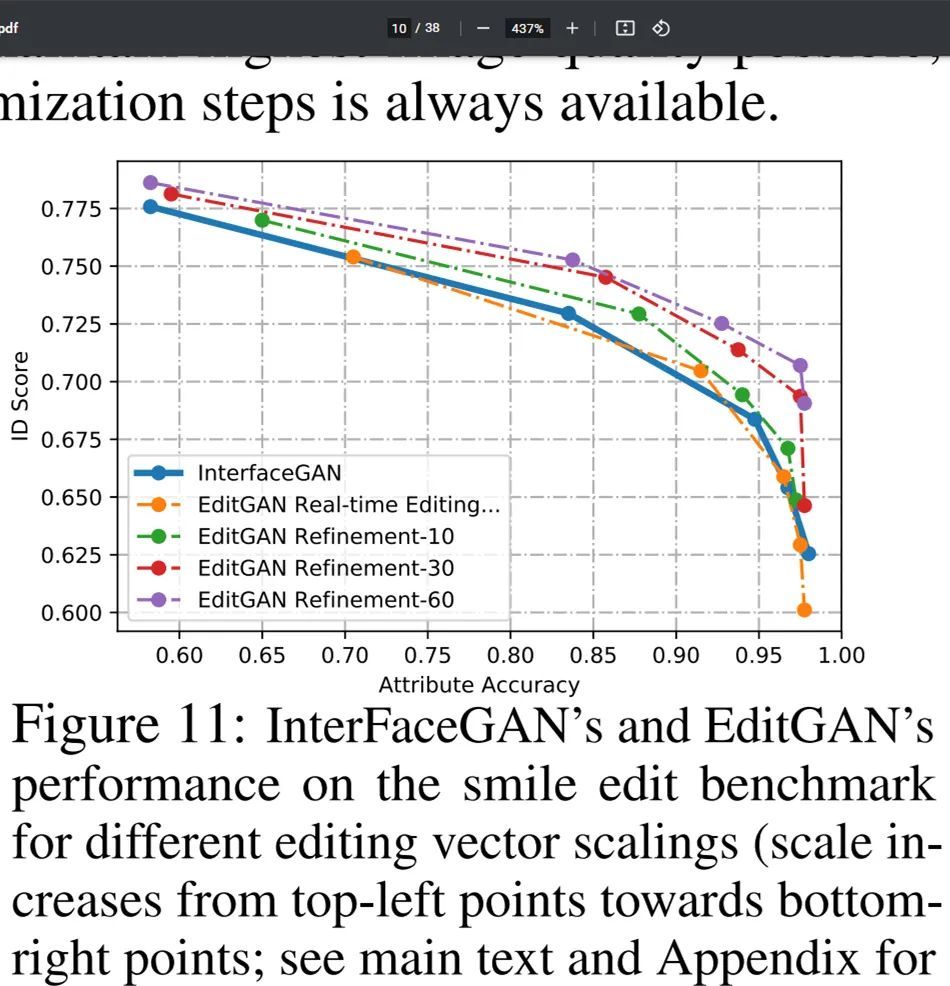
在下图 11 中,研究者展示了与 InterFaceGAN 比较的更多细节,其中应用了具有从 0 到 2 不同尺度系数的笑脸编辑向量。当编辑向量尺度较小时,身份分数高但笑脸属性分数低,这是对原始图像修改最小化导致的。他们发现,使用编辑向量的实时编辑效果可以媲美 InterFaceGAN。
最后说下运行时间。研究者仔细记录了 EditGAN 在 NVIDIA Tesla V100 GPU 上的运行时间。给定一个编辑好的分割掩码的情况下,走完 30 (60) 个优化 steps 的条件式优化耗时 11.4 (18.9) 秒。这一操作为他们提供了编辑向量。此外,编辑向量的应用几乎是瞬间完成的,仅耗时 0.4 秒,因此得以实现复杂的实时交互编辑。走完 10 (30) steps 的自监督细化将额外耗时 4.2 (9.5) 秒。