












模型非要大,性能才会好吗?
那可不一定!
当为新的机器学习应用程序构建深度模型时,研究人员通常会从现有的网络架构,比如ResNets或EfficientNets中筛选出一个初始架构。
如果初始模型的精度不够高,那么换用一个更大的模型可能是一个比较常见的选择,但这实际上可能不是最佳解决方案。
相反,通过设计一个针对特定任务优化的新模型,可能会获得更好的性能。然而,这种努力可能具有挑战性,通常需要耗费大量资源。
华人研究员Wang Xiaofang在Google Research实习期间,发表的论文「Wisdom of Committees:An Overlooked Approach to Faster and More Accurate Models」中,给出了模型集成和模型级联两种方法。

https://arxiv.org/pdf/2012.01988.pdf
这两种方法都是通过收集现有模型并组合它们的输出来构建新模型的简单方法。
研究证明,即使是少量易于构建的模型的集合也可以匹配或超过最先进模型的精度,同时效率显著提高。
Wang Xiaofang是卡内基梅隆大学机器人研究所的一名博士研究生,本科就读于北京大学计算机科学专业,是IJCV、TIP、ACM Computing Surveys等期刊的审稿人,也是CVPR、ICCV、ECCV、NeurIPS、ICML、ICLR等会议的审稿人。
什么是模型集成和级联?
集成(ensemble)和级联(cascade)是相关的方法,它们利用多个模型的优势来实现更好的解决方案。
集成并行执行多个模型,然后组合它们的输出来进行最终预测。
级联是集合的子集,但是顺序执行收集的模型,并且一旦预测具有足够高的置信度,就合并解。
对于简单的输入,级联使用较少的计算,但是对于更复杂的输入,可能会调用更多的模型,从而导致更高的计算成本。
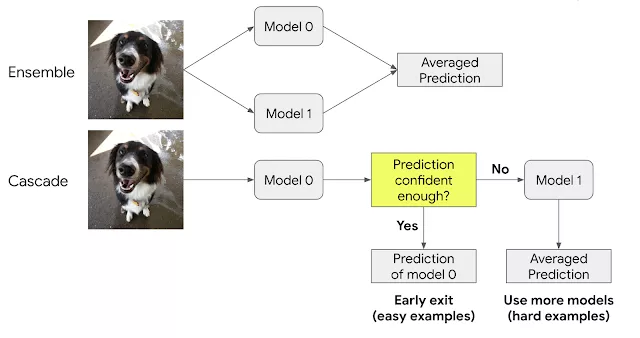
集成和级联概述,此示例显示了集成和级联的二模型组合。
与单一模型相比,如果收集到的模型预测存在差异,集成可以提供更高的准确性。
例如,ImageNet中的大多数图像对于现在的图像识别模型来说很容易分类,但是有许多图像的预测在模型之间有所不同,这种情况下,模型集成受益最大。
虽然集成(ensemble)是众所周知的,但它们通常不被认为是深度模型架构的核心构建块,并且在研究人员开发更高效的模型时很少被探索。
因此,该工作对集成效率进行了全面的分析,并表明简单的集成或现成预训练模型的级联可以提高最先进模型的效率和准确性。
模型集成有以下有益特性:
- 易于构建:集成不需要复杂的技术(例如,早期退出学习)。
- 易于维护:模型经过独立训练,易于维护和部署。
- 可负担的训练成本:一个集合中模型的总训练成本通常低于同样精确的单个模型。
- 设备加速:计算成本的降低成功地转化为真实硬件上的加速。
效率和训练速度
集成可以提高准确性并不奇怪,但是在集成中使用多个模型可能会在运行时引入额外的计算成本。
问题来了,一个模型集合是否能比具有相同计算成本的单个模型更精确呢?
通过分析一系列模型,从EfficientNet-B0到EfficientNet-B7,当应用于ImageNet输入时,它们具有不同的精度和浮点运算水平(FLOPS)。
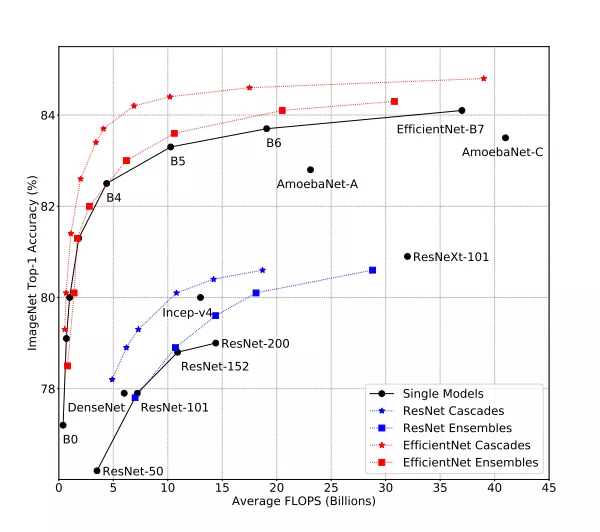
集成模型比ImageNet上的单一模型精度更高,同时使用的FLOPs更少。
集成预测是通过平均每个单独模型的预测来计算的。
他们发现,在大计算量范围内(大于 5B FLOPS),集成明显更具成本效益。
例如,两个EfficientNet-B5模型的集成可以匹配单个EfficientNet-B7模型的精度,但是使用大约50%的FLOPS。
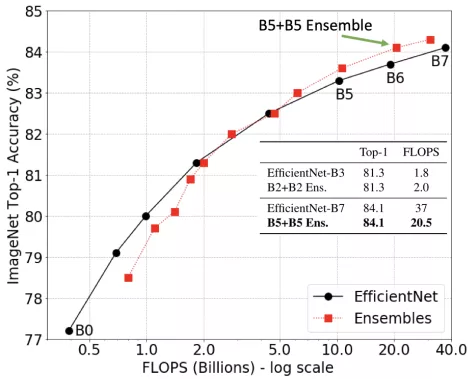
在大计算量范围内(超过5B FLOPS),模型集成优于单个模型。
这表明,在这种情况下,应该使用多个小得多的模型的集合,而不是使用大的模型,这将降低计算要求,同时保持准确性。
此外,集成的训练成本可以低得多(例如,训练两个B5模型需要总共96个TPU天;训练一个B7模型需要160TPU天)。
在实践中,模型集成训练可以使用多个加速器并行化,从而进一步减少训练时长。这种模式也适用于ResNet和MobileNet系列。
级联的强大和简洁
虽然我们已经演示了模型集成的效用,但是应用集成对于简单的输入来说往往是浪费的,因为集成的子集会给出正确的答案。
在这些情况下,级联通过允许提前退出来节省计算量,可能会在使用所有模型之前停止并输出答案,而挑战在于确定何时退出级联。

级联(cascade)算法伪代码
为了突出级联的实际好处,选择一种简单的启发式方法来测量预测的置信度:将模型的置信度视为分配给每个类的概率的最大值。
例如,如果图像是猫、狗或马的预测概率分别为20%、80%和20%,则模型预测(狗)的置信度为0.8,使用置信度得分的阈值来确定何时退出级联。
为了测试这种方法,他们为EfficientNet、ResNet和MobileNetV2系列构建模型级联,以匹配计算成本或精度(将级联限制为最多四个模型)。
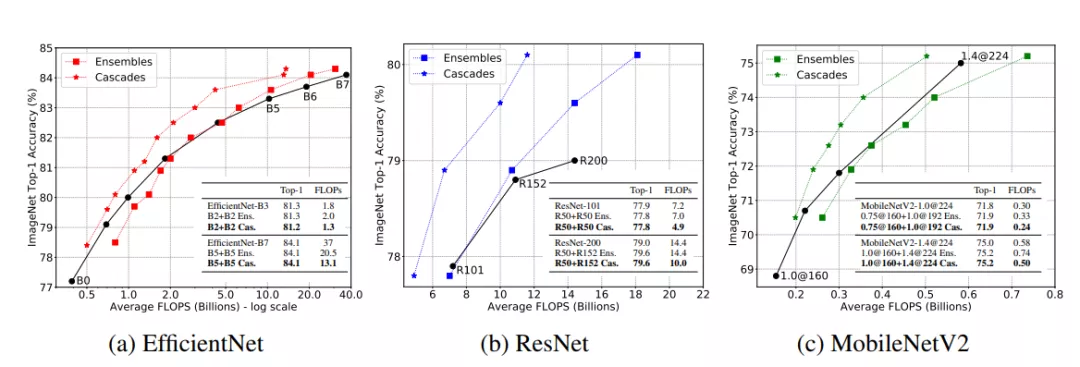
集成在大计算量区域工作良好,级联在所有计算量区域都显示出优势。
通过级联设计,一些困难的图像输入比简单的图像需要更多的FLOPS,因为更具挑战性的输入比更容易的输入在级联中经历更多的模型。
而所有测试图像的平均FLOPS计算结果表明,级联在所有计算领域都优于单个模型(当FLOPS的范围从0.15B到37B时),并且可以提高所有测试模型的精度或减少FLOPS(有时两者都有)。
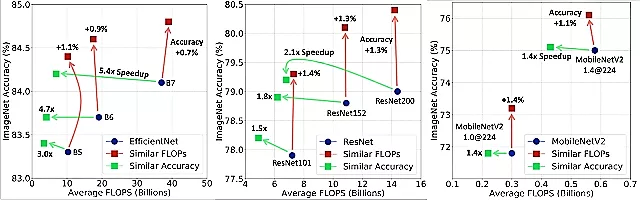
当使用类似的FLOPS时,级联比单个模型获得更高的精度(由指向上方的红色箭头显示)。级联也可以匹配具有明显更少FLOPS的单一模型的精度,例如B7为5.4倍(绿色箭头指向左侧)。
在某些情况下,限制因素不是平均计算成本,而是最坏情况下的成本。通过在级联构建过程中添加简单的约束,可以保证级联计算成本的上限。
除了卷积神经网络,研究人员还考虑了基于Transformer架构的ViT。
他们构建了ViT-Base和ViT-Large模型的级联,以匹配单个最先进的ViT-Large模型的平均计算或精度,并表明级联的优势也适用于基于Transformer的架构。

ViT模型的级联在ImageNet上的表现。级联可以以相似的吞吐量实现比ViT-L-384高1.0%的精度,或者在与其精度匹配的情况下实现比该模型高2.3倍的速度。
推理结果
上面的分析中使用了FLOPS进行平均来衡量计算成本,而验证级联的FLOPS降低实际上转化为了硬件加速也很重要。
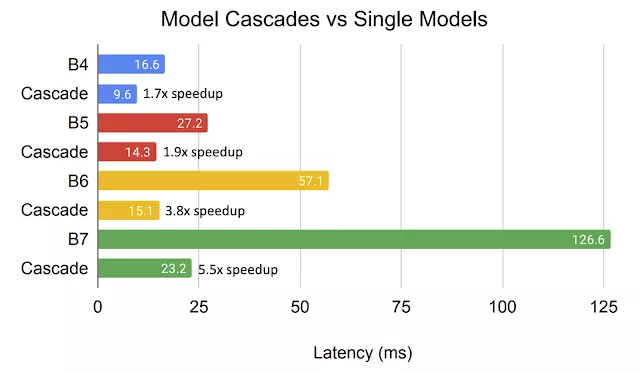
TPUv3上用于在线处理的级联的平均延迟。每对相同颜色的条形都有相当的精确度,而级联可以大幅降低延迟。
通过比较性能相似的单一模型与级联模型在设备上的延迟和加速,他们发现与精度相当的单个模型相比,高效网络的级联模型在TPUv3上的平均在线延迟降低了高达5.5倍。随着模型越来越大,类似级联带来的速度提升也越来越多。





























