













一 、前言
可观测性这个概念最早出现于20世纪70年代的电气工程,核心的定义是:
A system is said to be observable if, for any possible evolution of state and control vectors, the current state can be estimated using only the information from outputs.

相比传统的告警、监控,可观测性能够以更加“白盒”的方式看透整个复杂的系统,帮助我们更好的观察系统的运行状况,快速定位和解决问题。就像发动机而言,告警只是告诉你发动机是否有问题,而一些包含转速、温度、压力的仪表盘能够帮我们大致确定是哪个部分可能有问题,而真正定位细节问题还需要观察每个部件的传感器数据才行。
二 、IT系统的可观测性
电气化时代起源于第二次工业革命(Second Industrial Revolution)起于19世纪七十年代,主要标志是:电力、内燃机的广泛应用。而可观测性这一概念为何在近100年后才会被提出?难道在此之前就不需要依赖各类传感器的输出定位和排查故障和问题?显然不是,排查故障的方式一直都在,只是整个系统和情况更加复杂,所以才需要更加体系化、系统化的方式来支持这一过程,因此演化出来可观测性这个概念。所以核心点在于:
- 系统更加的复杂:以前的汽车只需要一个发动机、传送带、车辆、刹车就可以跑起来,现在随便一个汽车上至少有上百个部件和系统,故障的定位难度变的更大。
- 开发涉及更多的人:随着全球化时代的到来,公司、部分的分工也越来越细,也就意味着系统的开发和维护需要更多的部门和人来共同完成,协调的代价也越来越大。
- 运行环境多种多样:不同的运行环境下,每个系统的工作情况是变化的,我们需要在任何阶段都能有效记录好系统的状态,便于我们分析问题、优化产品。

而IT系统经过几十年的飞速发展,整个开发模式、系统架构、部署模式、基础设施等也都经过了好几轮的优化,优化带来了更快的开发、部署效率,但随之而来整个的系统也更加的复杂、开发依赖更多的人和部门、部署模式和运行环境也更加动态和不确定,因此IT行业也已经到了需要更加系统化、体系化进行观测的这一过程。
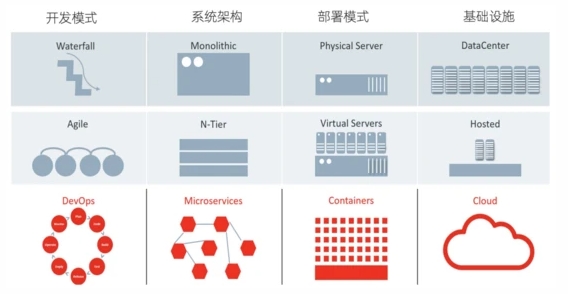
IT系统的可观测性实施起来其实和电气工程还是比较类似,核心还是观察我们各个系统、应用的输出,通过数据来判断整体的工作状态。通常我们会把这些输出进行分类,总结为Traces、Metrics、Logs。关于这三种数据的特点、应用场景以及关系等,我们会在后面进行详细展开。
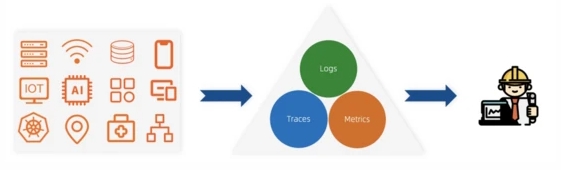
三、IT可观测性的演进
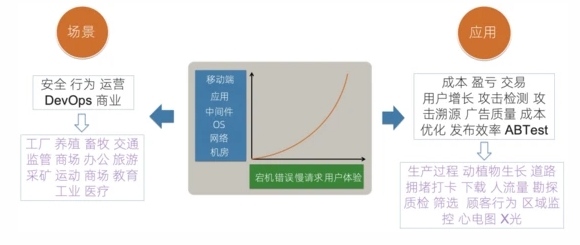
IT的可观测性技术一直在不断的发展中,从广义的角度上讲,可观测性相关的技术除了应用在IT运维的场景外,还可以应用在和公司相关的通用场景以及特殊场景中。
- IT运维场景:IT运维场景从横向、纵向来看,观察的目标从最基础的机房、网络等开始向用户的端上发展;观察的场景也从纯粹的错误、慢请求等发展为用户的实际产品体验。
- 通用场景:观测本质上是一个通用的行为,除了运维场景外,对于公司的安全、用户行为、运营增长、交易等都适用,我们可以针对这些场景构建例如攻击检测、攻击溯源、ABTest、广告效果分析等应用形式。
- 特殊场景:除了场景的公司内通用场景外,针对不同的行业属性,也可以衍生出特定行业的观测场景与应用,例如阿里云的城市大脑,就是通过观测道路拥堵、信号灯、交通事故等信息,通过控制不同红绿灯时间、出行规划等手段降低城市整体拥堵率。
四 、Pragmatic可观测性如何落地
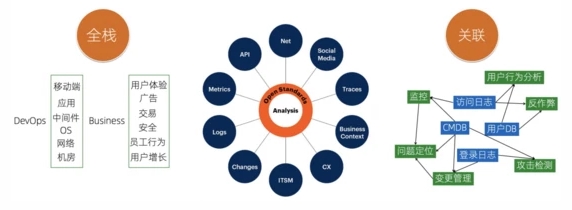
回到可观测性方案落地上,我们现阶段可能无法做出一个适用于各个行业属性的可观测引擎,更多的还是专注于DevOps和通用的公司商业方面。这里面的两个核心工作是:
- 数据的覆盖面足够的全:能够包括各类不同场景的不同类型的数据,除了狭义的日志、监控、Trace外,还需要包括我们的CMDB、变更数据、客户信息、订单/交易信息、网络流、API调用等
- 数据关联与统一分析:数据价值的发掘不是简单的通过一种数据来实现,更多的时候我们需要利用多种数据关联来达到目的,例如结合用户的信息表以及访问日志,我们可以分析不同年龄段、性别的用户的行为特点,针对性的进行推荐;通过登录日志、CMDB等,结合规则引擎,来实现安全类的攻击检测。

从整个流程来看,我们可以将可观测性的工作划分为4个组成部分:
- 传感器:获取数据的前提是要有足够传感器来产生数据,这些传感器在IT领域的形态有:SDK、埋点、外部探针等。
- 数据:传感器产生数据后,我们需要有足够的能力去获取、收集各种类型的数据,并把这些数据归类分析。
- 算力:可观测场景的核心是需要覆盖足够多的数据,数据一定是海量的,因此系统需要有足够的算力来计算和分析这些数据。
- 算法:可观测场景的终极应用是数据的价值发掘,因此需要使用到各类算法,包括一些基础的数值类算法、各种AIOps相关的算法以及这些算法的组合。
五 、再论可观测性数据分类
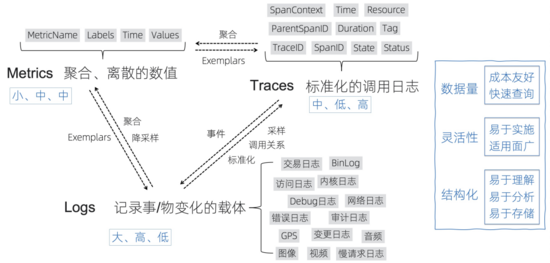
Logs、Traces、Metrics作为IT可观测性数据的三剑客,基本可以满足各类监控、告警、分析、问题排查等需求,然而实际场景中,我们经常会搞混每种数据的适用形态,这里再大致罗列一下这三类数据的特点、转化方式以及适用场景:
- Logs:我们对于Logs是更加宽泛的定义:记录事/物变化的载体,对于常见的访问日志、交易日志、内核日志等文本型以及包括GPS、音视频等泛型数据也包含在其中。日志在调用链场景结构化后其实可以转变为Trace,在进行聚合、降采样操作后会变成Metrics。
- Metrics:是聚合后的数值,相对比较离散,一般有name、labels、time、values组成,Metrics数据量一般很小,相对成本更低,查询的速度比较快。
- Traces:是最标准的调用日志,除了定义了调用的父子关系外(一般通过TraceID、SpanID、ParentSpanID),一般还会定义操作的服务、方法、属性、状态、耗时等详细信息,通过Trace能够代替一部分Logs的功能,通过Trace的聚合也能得到每个服务、方法的Metrics指标。
六 、“割裂”的可观测性方案

业界也针对这种情况推出了各类可观察性相关的产品,包括开源、商业化的众多项目。例如:
- Metrics:Zabbix、Nagios、Prometheus、InfluxDB、OpenFalcon、OpenCensus
- Traces:Jaeger、Zipkin、SkyWalking、OpenTracing、OpenCensus
- Logs:ELK、Splunk、SumoLogic、Loki、Loggly
利用这些项目的组合或多或少可以解决针对性的一类或者几类问题,但真正应用起来你会发现各种问题:
- 多套方案交织:可能要使用至少Metrics、Logging、Tracing3种方案,维护代价巨大
- 数据不互通:虽然是同一个业务组件,同一个系统,产生的数据由于在不同的方案中,数据难以互通,无法充分发挥数据价值
在这种多套方案组合的场景下,问题排查需要和多套系统打交道,若这些系统归属不同的团队,还需要和多个团队进行交互才能解决问题,整体的维护和使用代价非常巨大。因此我们希望能够使用一套系统去解决所有类型可观测性数据的采集、存储、分析的功能。
七 、可观测性数据引擎架构
基于上述我们的一些思考,回归到可观测这个问题的本质,我们目标的可观测性方案需要能够满足以下几点:
- 数据全面覆盖:包括各类的可观测数据以及支持从各个端、系统中采集数据
- 统一的系统:拒绝割裂,能够在一个系统中支持Traces、Metrics、Logs的统一存储与分析
- 数据可关联:每种数据内部可以互相关联,也支持跨数据类型的关联,能够用一套分析语言把各类数据进行融合分析
- 足够的算力:分布式、可扩展,面对PB级的数据,也能有足够的算力去分析
- 灵活智能的算法:除了基础的算法外,还应包括AIOps相关的异常检测、预测类的算法,并且支持对这些算法进行编排
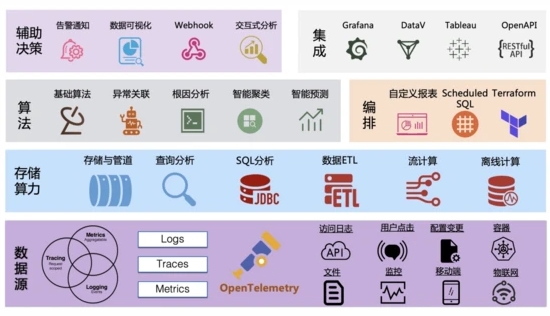
可观测数据引擎的整体架构如下图所示,从底到上的四层也基本符合方案落地的指导思想:传感器+数据+算力+算法。
- 传感器:数据源以OpenTelemetry为核心,并且支持各类数据形态、设备/端、数据格式的 采集 ,覆盖面足够的“广”。
- 数据+算力:采集上来的数据,首先会进入到我们的 管道系统 (类似于Kafka),根据不同的数据类型构建不同的索引,目前每天我们的平台会有几十PB的新数据写入并存储下。除了常见的 查询 和 分析 能力外,我们还内置了 ETL 的功能,负责对数据进行清洗和格式化,同时支持对接外部的流计算和离线计算系统。
- 算法:除了基础的数值算法外,目前我们支持了十多种的 异常检测/预测算法 ,并且还支持 流式异常检测 ;同时也支持使用 Scheduled SQL 进行数据的编排,帮助我们产生更多新的数据。
- 价值发掘:价值发掘过程主要通过 可视化 、 告警 、 交互式分析 等人机交互来实现,同时也提供了 OpenAPI 来对接外部系统或者供用户来实现一些自定义的功能。
八 、数据源与协议兼容
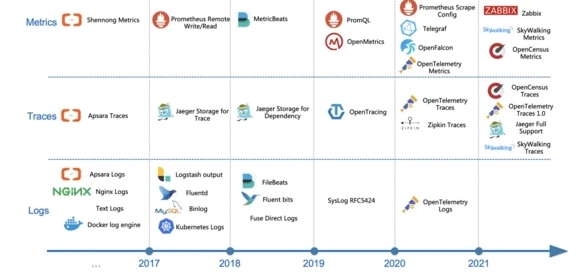
随着阿里全面拥抱云原生后,我们也开始逐渐去兼容开源以及云原生的可观测领域的协议和方案。相比自有协议的封闭模式,兼容开源、标准协议大大扩充了我们平台能够支持的数据采集范围,而且减少了不必要的造轮子环节。上图展示了我们兼容外部协议、Agent的整体进度:
- Traces:除了内部的飞天Trace、鹰眼Trace外,开源的包括Jaeger、OpenTracing、Zipkin、SkyWalking、OpenTelemetry、OpenCensus等。
- Logs:Logs的协议较少,但是设计比较多的日志采集Agent,我们平台除了自研的Logtail外,还兼容包括Logstash、Beats(FileBeat、AuditBeat)、Fluentd、Fluent bits,同时还提供syslog协议,路由器交换机等可以直接用syslog协议上报数据到服务端。
- Metrics:时序引擎我们在新版本设计之初就兼容了Prometheus,并且支持Telegraf、OpenFalcon、OpenTelemetry Metrics、Zabbix等数据接入。
九 、统一存储引擎
对于存储引擎,我们的设计目标的第一要素是统一,能够用一套引擎存储各类可观测的数据;第二要素是快,包括写入、查询,能够适用于阿里内外部超大规模的场景(日写入几十PB)。

对于Logs、Traces、Metrics,其中Logs和Traces的格式和查询特点非常相似,我们放到一起来分析,推导的过程如下:
Logs/Traces:
- 查询的方式主要是通过关键词/TraceID进行查询,另外会根据某些Tag进行过滤,例如hostname、region、app等
- 每次查询的命中数相对较少,尤其是TraceID的查询方式,而且命中的数据极有可能是离散的
- 通常这类数据最适合存储在搜索引擎中,其中最核心的技术是倒排索引
Metrics:
- 通常都是range查询,每次查询某一个单一的指标/时间线,或者一组时间线进行聚合,例如统一某个应用所有机器的平均CPU
- 时序类的查询一般QPS都较高(主要有很多告警规则),为了适应高QPS查询,需要把数据的聚合性做好
- 对于这类数据都会有专门的时序引擎来支撑,目前主流的时序引擎基本上都是用类似于LSM Tree的思想来实现,以适应高吞吐的写入和查询(Update、Delete操作很少)
同时可观测性数据还有一些共性的特点,例如高吞吐写入(高流量、QPS,而且会有Burst)、超大规模查询特点、时间访问特性(冷热特性、访问局部性等)。
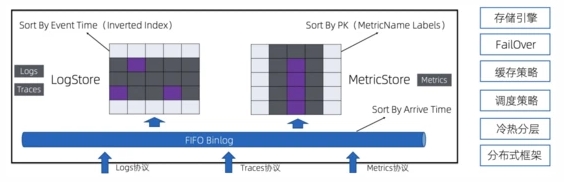
针对上述的特性分析,我们设计了一套统一的可观测数据存储引擎,整体架构如下:
- 接入层支持各类协议写入,写入的数据首先会进入到一个FIFO的管道中,类似于Kafka的MQ模型,并且支持数据消费,用来对接各类下游
- 在管道之上有两套索引结构,分别是倒排索引以及SortedTable,分别为Traces/Logs和Metrics提供快速的查询能力
- 两套索引除了结构不同外,其他各类机制都是共用的,例如存储引擎、FailOver逻辑、缓存策略、冷热数据分层策略等
- 上述这些数据都在同一个进程内实现,大大降低运维、部署代价
- 整个存储引擎基于纯分布式框架实现,支持横向扩展,单个Store最多支持日PB级的数据写入
十 、统一分析引擎

如果把存储引擎比喻成新鲜的食材,那分析引擎就是处理这些食材的刀具,针对不同类型的食材,用不同种类的刀来处理才能得到最好的效果,例如蔬菜用切片刀、排骨用斩骨刀、水果用削皮刀等。同样针对不同类型的可观测数据和场景,也有对应的适合的分析方式:
- Metrics:通常用于告警和图形化展示,一般直接获取或者辅以简单的计算,例如PromQL、TSQL等
- Traces/Logs:最简单直接的方式是关键词的查询,包括TraceID查询也只是关键词查询的特例
- 数据分析(一般针对Traces、Logs):通常Traces、Logs还会用于数据分析和挖掘,所以要使用图灵完备的语言,一般程序员接受最广的是SQL
上述的分析方式都有对应的适用场景,我们很难用一种语法/语言去实现所有的功能并且具有非常好的便捷性(虽然通过扩展SQL可以实现类似PromQL、关键词查询的能力,但是写起来一个简单的PromQL算子可能要用一大串SQL才能实现),因此我们的分析引擎选择去兼容关键词查询、PromQL的语法。同时为了便于将各类可观测数据进行关联起来,我们在SQL的基础上,实现了可以连接关键词查询、PromQL、外部的DB、ML模型的能力,让SQL成为顶层分析语言,实现可观测数据的融合分析能力。
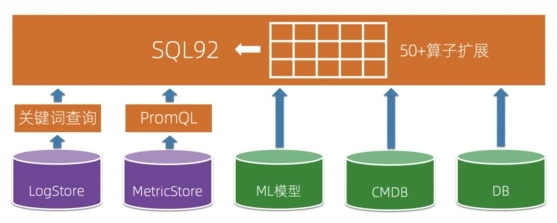
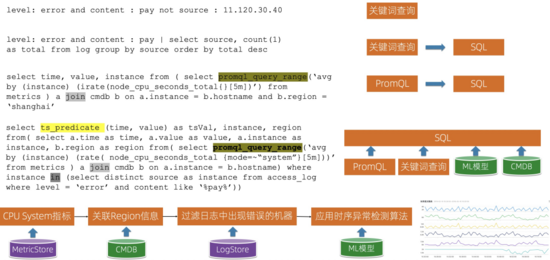
下面举几个我们的查询/分析的应用示例,前面3个相对比较简单,可以用纯粹的关键词查询、PromQL,也可以结合SQL一起使用。最后一个展示了实际场景中进行融合分析的例子:
- 背景:线上发现有支付失败的错误,需要分析这些出现支付失败的错误的机器CPU指标有没有问题
- 实现:首先查询机器的CPU指标;关联机器的Region信息(需要排查是否某个Region出现问题);和日志中出现支付失败的机器进行Join,只关心这些机器;最后应用时序异常检测算法来快速的分析这些机器的CPU指标;最后的结果使用线图进行可视化,结果展示更加直观。
上述的例子同时查询了LogStore、MetricStore,而且关联CMDB以及ML模型,一个语句实现了非常复杂的分析效果,在实际的场景中还是经常出现的,尤其是分析一些比较复杂的应用和异常。
十一、数据编排
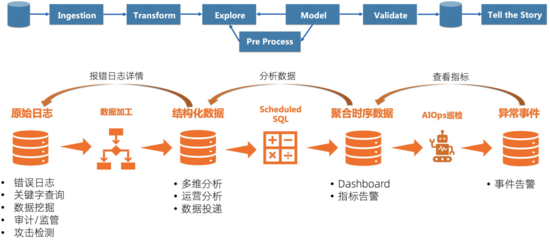
可观测性相比传统监控,更多的还是在于数据价值的发掘能力更强,能够仅通过输出来推断系统的运行状态,因此和数据挖掘这个工作比较像,收集各类繁杂的数据、格式化、预处理、分析、检验,最后根据得到的结论去“讲故事”。因此在可观测性引擎的建设上,我们非常关注数据编排的能力,能够让数据流转起来,从茫茫的原始日志中不断的去提取出价值更高的数据,最终告诉我们系统是否在工作以及为什么不工作。为了让数据能够“流转”起来,我们开发了几个功能:
- 数据加工:也就是大数据ETL(extract, transform, and load)中T的功能,能够帮我们把非结构化、半结构化的数据处理成结构化的数据,更加容易分析。
- Scheduled SQL:顾名思义,就是定期运行的SQL,核心思想是把庞大的数据精简化,更加利于查询,例如通过AccessLog每分钟定期计算网站的访问请求、按APP、Region粒度聚合CPU、内存指标、定期计算Trace拓扑等。
- AIOps巡检:针对时序数据特别开发的基于时序异常算法的巡检能力,用机器和算力帮我们去检查到底是哪个指标的哪个维度出现问题。
十二、可观测性引擎应用实践
目前我们这套平台上已经积累了10万级的内外部用户,每天写入的数据40PB+,非常多的团队在基于我们的引擎在构建自己公司/部门的可观测平台,进行全栈的可观测和业务创新。下面将介绍一些常见的使用我们引擎的场景:
1 全链路可观测
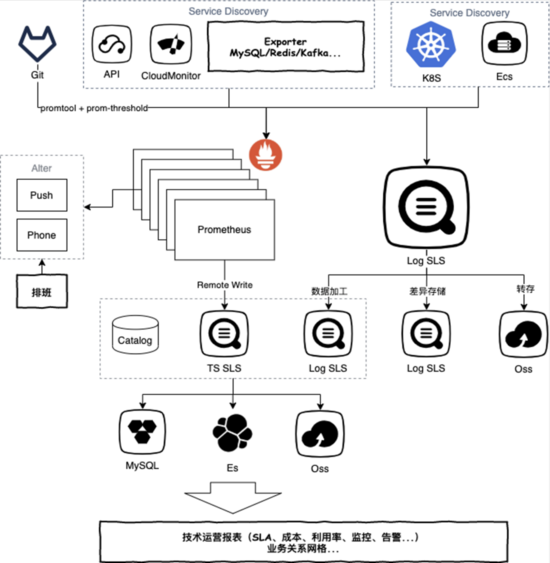
全链路的可观测性一直都是DevOps环节中的重要步骤,除了通常的监控、告警、问题排查外,还承担用户行为回放/分析、版本发布验证、A/B Test等功能,下图展示的是阿里内部某个产品内部的全链路可观测架构图:
- 数据源包括移动端、Web端、后端的各类数据,同时还包括一些监控系统的数据、第三方的数据等
- 采集通过SLS的Logtail和TLog实现
- 基于离在线混合的数据处理方式,对数据进行打标、过滤、关联、分发等预处理
- 各类数据全部存储在SLS可观测数据引擎中,主要利用SLS提供的索引、查询和聚合分析能力
- 上层基于SLS的接口构建全链路的数据展示和监控系统

2 成本可观测
商业公司的第一要务永远是营收、盈利,我们都知道盈利=营收-成本,IT部门的成本通常也会占据很大一个部分,尤其是互联网类型的公司。现在阿里全面云化后,包括阿里内部的团队也会在乎自己的IT支出,尽可能的压缩成本。下面的示例是我们阿里云上一家客户的监控系统架构,系统除了负责IT基础设施和业务的监控外,还会负责分析和优化整个公司的IT成本,主要收集的数据有:
- 收集云上每个产品(虚拟机、网络、存储、数据库、SaaS类等)的费用,包括详细的计费信息
- 收集每个产品的监控信息,包括用量、利用率等
- 建立起Catalog/CMDB,包括每个资源/实例所属的业务部门、团队、用途等
利用Catalog + 产品计费信息,就可以计算出每个部门的IT支出费用;再结合每个实例的用量、利用率信息,就可以计算出每个部门的IT资源利用率,例如每台ECS的CPU、内存使用率。最终计算出每个部门/团队整体上使用IT资源的合理度,将这些信息总结成运营报表,推动资源使用合理度低的部门/团队去优化。
3 Trace可观测
随着云原生、微服务逐渐在各个行业落地,分布式链路追踪(Trace)也开始被越来越多的公司采用。对于Trace而言,最基础的能力是能够记录请求在多个服务之间调用的传播、依赖关系并进行可视化。而从Trace本身的数据特点而言,它是规则化、标准化且带有依赖关系的访问日志,因此可以基于Trace去计算并挖掘更多的价值。
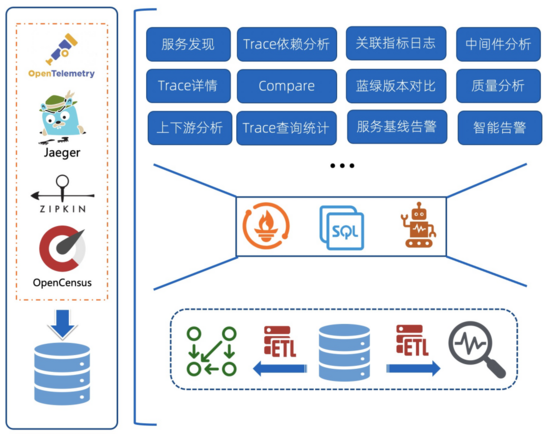
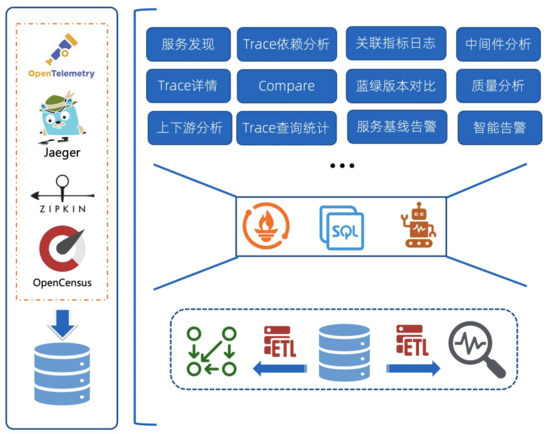
下面是SLS OpenTelemetry Trace的实现架构,核心是通过数据编排计算Trace原始数据并得到聚合数据,并基于SLS提供的接口实现各类Trace的附加功能。例如:
- 依赖关系:这是绝大部分的Trace系统都会附带的功能,基于Trace中的父子关系进行聚合计算,得到Trace Dependency
- 服务/接口黄金指标:Trace中记录了服务/接口的调用延迟、状态码等信息,基于这些数据可以计算出QPS、延迟、错误率等黄金指标。
- 上下游分析:基于计算的Dependency信息,按照某个Service进行聚合,统一Service依赖的上下游的指标
- 中间件分析:Trace中对于中间件(数据库/MQ等)的调用一般都会记录成一个个Span,基于这些Span的统计可以得到中间件的QPS、延迟、错误率。
- 告警相关:通常基于服务/接口的黄金指标设置监控和告警,也可以只关心整体服务入口的告警(一般对父Span为空的Span认为是服务入口调用)。
4 基于编排的根因分析
可观测性的前期阶段,很多工作都是需要人工来完成,我们最希望的还是能有一套自动化的系统,在出现问题的时候能够基于这些观测的数据自动进行异常的诊断、得到一个可靠的根因并能够根据诊断的根因进行自动的Fix。现阶段,自动异常恢复很难做到,但根因的定位通过一定的算法和编排手段还是可以实施的。
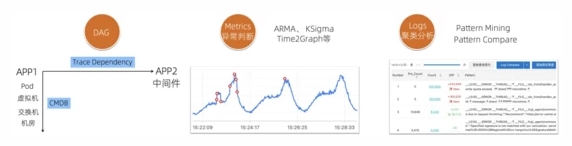
下图是一个典型的IT系统架构的观测抽象,每个APP都会有自己的黄金指标、业务的访问日志/错误日志、基础监控指标、调用中间件的指标、关联的中间件自身指标/日志,同时通过Trace还可以得到上下游APP/服务的依赖关系。通过这些数据再结合一些算法和编排手段就可以进行一定程度的自动化根因分析了。这里核心依赖的几点如下:
- 关联关系:通过Trace可以计算出APP/服务之间的依赖关系;通过CMDB信息可以得到APP和PaaS、IaaS之间的依赖关系。通过关联关系就可以“顺藤摸瓜”,找到出现问题的原因。
- 时序异常检测算法:自动检测某一条、某组曲线是否有异常,包括ARMA、KSigma、Time2Graph等,详细的算法可以参考: 异常检测算法 、 流式异常检测 。
- 日志聚类分析: 将相似度高的日志聚合,提取共同的日志模式(Pattern),快速掌握日志全貌,同时 利用Pattern的对比功能,对比正常/异常时间段的Pattern,快速找到日志中的异常。
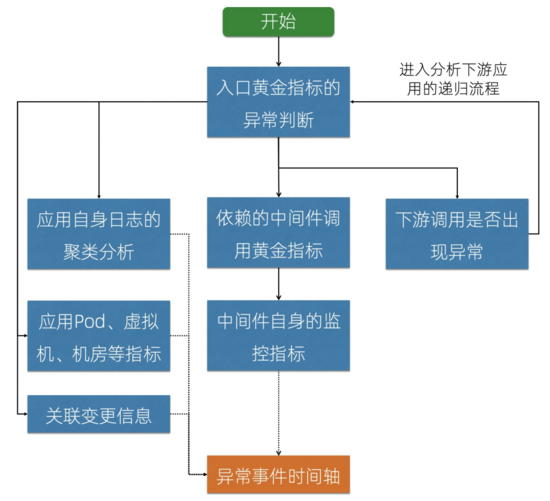
时序、日志的异常分析能够帮我们确定某个组件是否存在问题,而关联关系能够让我们进行“顺藤摸瓜”。通过这三个核心功能的组合就可以编排出一个异常的根因分析系统。下图就是一个简单的示例:首先从告警开始分析入口的黄金指标,随后分析服务本身的数据、依赖的中间件指标、应用Pod/虚拟机指标,通过Trace Dependency可以递归分析下游依赖是否出现问题,其中还可以关联一些变更信息,以便快速定位是否由于变更引起的异常。最终发现的异常事件集中到时间轴上进行推导,也可以由运维/开发来最终确定根因。
十三、写在最后
可观测性这一概念并不是直接发明的“黑科技”,而是我们从监控、问题排查、预防等工作中逐渐“演化”出来的词。同样我们一开始只是做日志引擎(阿里云上的产品: 日志服务 ),在随后才逐渐优化、升级为可观测性的引擎。对于“可观测性”我们要抛开概念/名词本身来发现它的本质,而这个本质往往是和商业(Business)相关,例如:
- 让系统更加稳定,用户体验更好
- 观察IT支出,消除不合理的使用,节省更多的成本
- 观察交易行为,找到刷单/作弊,即时止损
- 利用AIOps等自动化手段发现问题,节省更多的人力,运维提效
而我们对于可观测性引擎的研发,主要关注的也是如何服务更多的部门/公司进行可观测性方案的快速、有效实施。包括引擎中的传感器、数据、计算、算法等工作一直在不断进行演进和迭代,例如更加便捷的eBPF采集、更高压缩率的数据压缩算法、性能更高的并行计算、召回率更低的根因分析算法等。


























