













背景
最近也许是我们公司给的活动太给力,业务数据量剧增,于是要考虑优化数据库,作为程序猿的我们都知道数据是我们的命脉,我们做的工作就是处理数据,优化数据是我们一直要面临的问题。
MySQL优化维度
一般优化数据库都需要从以下四个维度进行:
- 硬件
- 系统配置
- 数据库表结构
- SQL 及索引
对于写业务的我们的最直接就是SQL及索引优化,效果最显著性、价比最高的是索引优化。
认识索引
索引是帮助数据库(Mysql)高效获取数据的排好顺序的数据结构。
原理
通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是我们总是通过同一种查找方式来锁定数据。
MySQL索引的数据结构有以下几种:
- Hash表
- B+树
使用Hash算法作为索引,有以下问题,所以大部分我们选择的是BTREE。
- 存在Hash碰撞。
- 只能精确查找,无法用于局部查找和范围查找。
MySQL的B+树
我们先来回顾下大学数据结构里面的B+树,长这个样子。
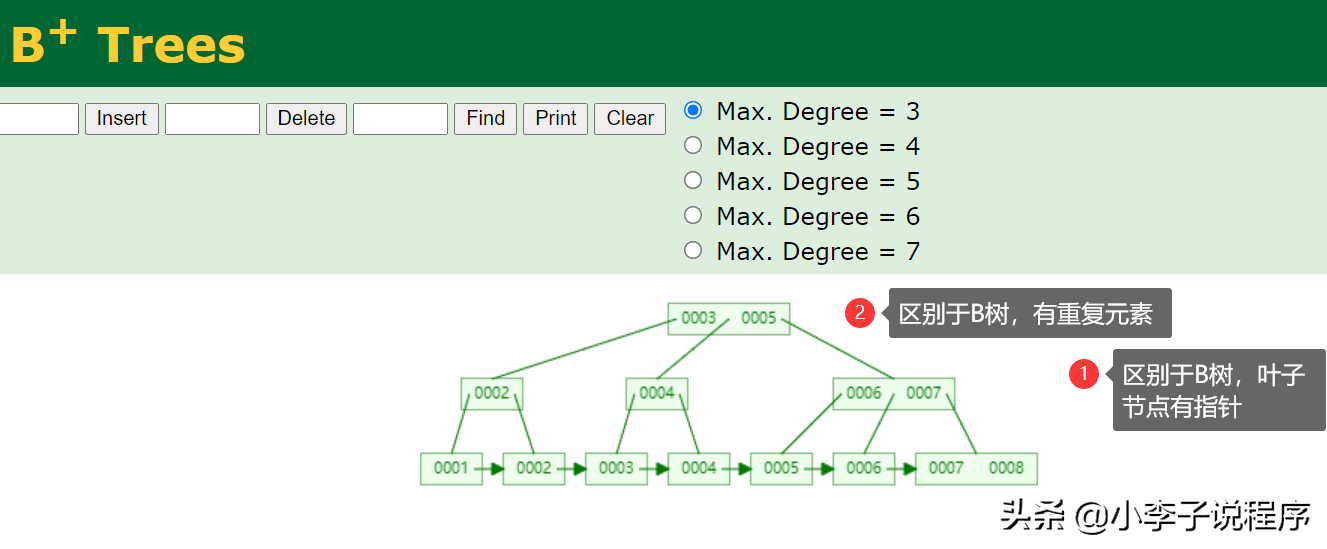
MySQL中的B+数其实是对传统的B+树做了改进。
将叶子节点的数据单向指针变成双向指针,树高为2。
MySQL每次查1条数据都会查出1页数据(16K),然后在内存里面遍历,减少IO,大大提高查询效率。
Mysql 在插入数据后,会自动给我们排序。为什么要这样做呢?
1.先看一个例子,查询一条不存在的数据。
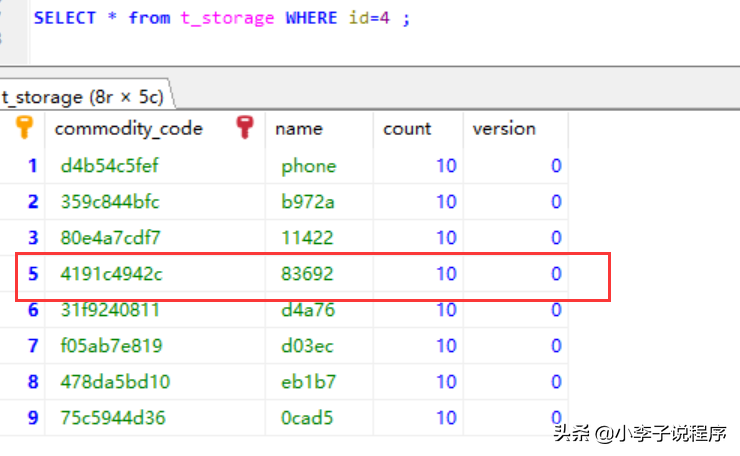
如果排序后,只用遍历到第4条记录,就可以不用查了,如果不排序,就要遍历所有的数据。
2.比较多的数据查询,还是一页数据。
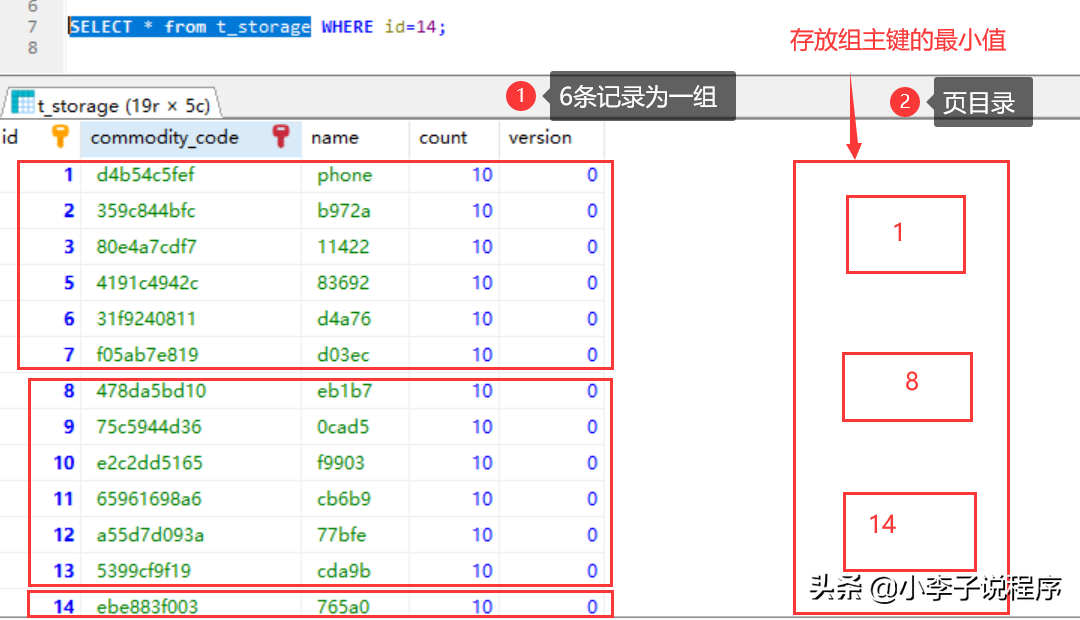
在页模式底部存储的数据,采用了链表的结构,插入比较快,但是查询比较慢,数据量比较大的时候就需要用空间换时间,给页面加个目录,先去查页目录(通过二分法查找)。不加目录则需要查13次,加了目录只需要3次就就可以找到数据。这是排序的最主要原因。
3.随着数据量的进一步增大,会出现很多页数据,然后再对多页数据进行索引,即采用了页目录的目录项,从而管理页,而页目录管理行。
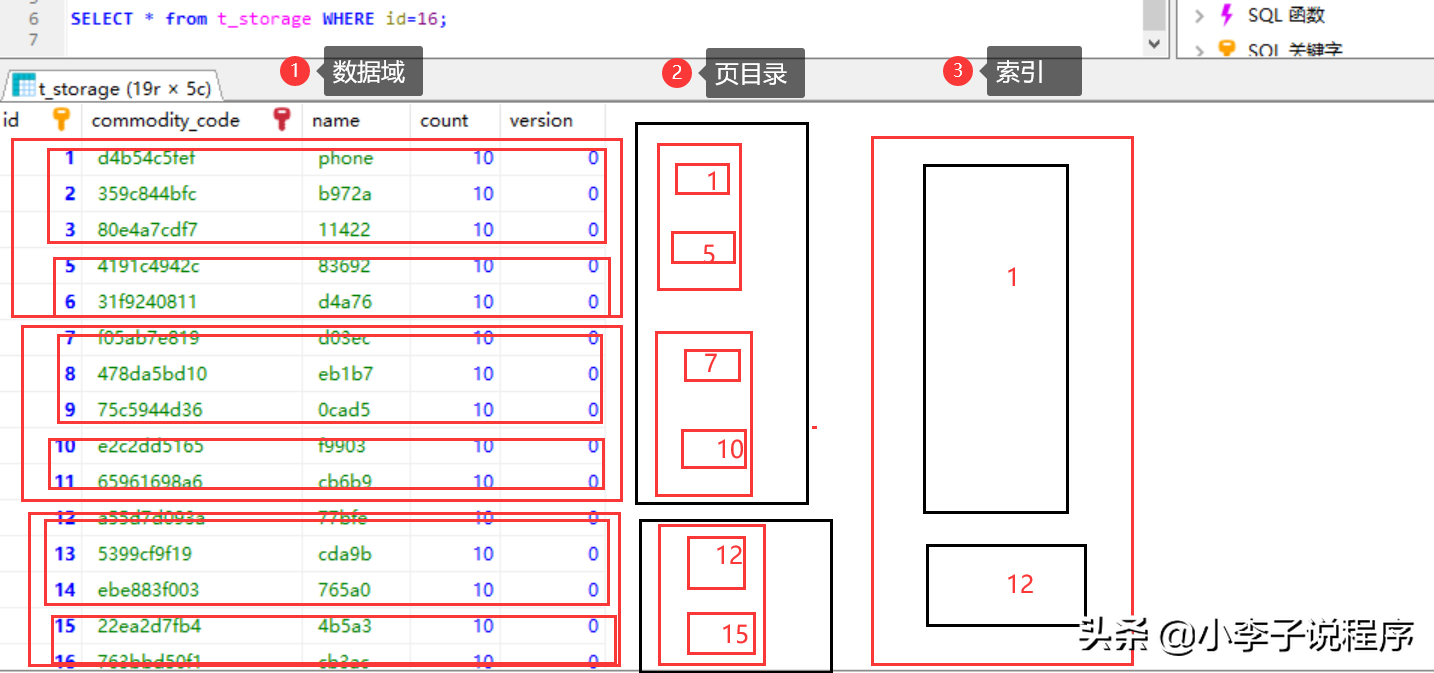
目录页的本质也是页,存的数据是普通页的地址。所以不管是目录页还是页目录,都和数据存放在一起。这就是聚簇索引的由来(即主键索引和数据放在一起)。这样就形成了B+树。
一棵树存放的数据量
一行存放数据大小按1k算,则一页存放16行数据。高度为3的b +树,主键为BigInt(占8个字节),innodb 指针占(6个字节),就可以存放(16*1024/(8+6)*(16*1024/(8+6)*16=2千多万行数据。这就是一般一个表的数据超过2千万就不建议走索引,要分库分表的原因了。这样的结构就可以使得2千万的数据,只需要3次IO.
双向指针的原因
范围查找时,如果查找小于某个值的记录,就需根据指针要反向查找,所以需要反向指针。
回表
当有多个字段组成组合索引时,此时的索引是非聚簇索引,叶子节点不存储数据,存储的是数据行地址,因为数据量比较大。这样查出后,通过记录主键反查完整记录。这就是回表。
注意
InnoDB中一定有主键索引,主键一定是聚簇索引,如果没有则会使用一个unique索引作为主键索引,如果没有unique索引,则会使用数据库内部的一个隐藏行id来当作主键索引。有且只有一个聚簇索引。非聚簇索引都需要回表。






















