1.前言
本文主要是分享目前博主理解的流批一体产生的背景,想解决的问题,以及后续可能实现的思路,并以几个案例进行介绍。抛砖引玉,让大家不止停留在做流批一体这件事,而是能更深入思考背后的原因。
2.背景
在介绍流批一体之前,首先看看目前流和批领域常用的引擎:
批任务:常用 Hive、Spark。
流任务:常用 Flink。Spark Streaming 与 Storm 使用率目前在流式场景会小于 Flink。
3.什么问题导致产生了流批一体的概念呢?
一个前提:在生产场景中,当同一个口径的指标分别用流任务产出了实时数据,用批任务产出了离线数据,才会去考虑是否需要做流批一体。如果一个指标只需要产出离线,何谈流批一体呢?
一个角度:博主认为,流批一体更应该站在流的角度思考,去将流任务产出的结果在批领域(或者以批数据的形式)进行复用,而不仅仅是在引擎侧面,API 接口层面的统一。这点思考与下图阿里(From FFA 2020)所说的问题的观点类似,博主理解实时复用在离线领域 可能
是对于阿里列举的问题的一个抽象。因为如果能够复用的话,下图中的三个问题也就不存在了!
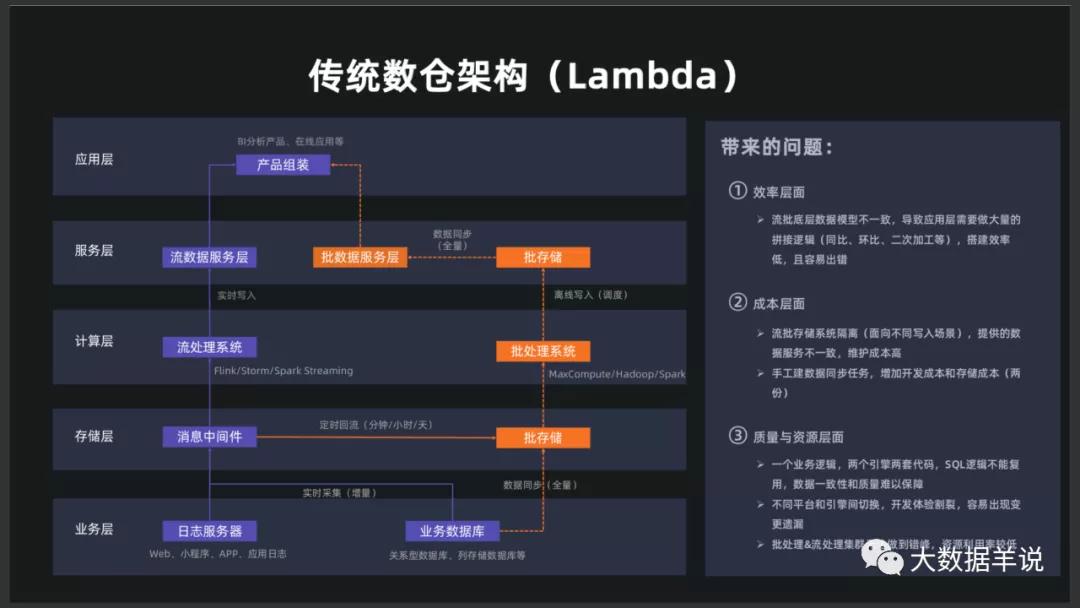
解决的问题:在上述前提和思考角度的基础上,博主认为,流批一体目前需要解决的最重要的就是解决流任务产出数据的质量问题,这也是流数据能在批场景复用的前提。用过 Flink 做实时数据开发的同学应该都碰到过 Flink 产出数据的时候,总会由于一些异常(比如使用了窗口可能会导致丢数)导致和离线 Hive、Spark 产出的数据有一些微小的差别,这样就没法做到实时数据在离线领域的复用。博主理解,流批一体的重点就是要解决这个问题,其他的在资源节约、人效提高方面的优势都是基于此的附加价值。
4.那么导致流任务产生数据质量问题的原因是什么,有哪些常见场景?
博主认为,目前最重要的一个原因就是数据乱序导致的数据质量问题。
在实时领域最常用和常见的场景有以下两种:
第一种是 Flink 任务开窗口的场景。举例,一个开了 TUMBLE WINDOW 的 Flink 任务,遇到严重的数据乱序的情况(用户配置的最大乱序、允许延迟等参数都解决不了),那么任务就会把数据给丢掉,这种场景下就会导致实时数据与离线数据产生差异。
第二种是实时维表关联的场景。如果事实表的数据先到,就有关联不到维表中的数据。从而产生与离线的差异。
当然还有其他场景,这里就不一一列举了。
5.想要解决上述数据质量问题,可行的思路有哪些?
理想化的思路:以 TUMBLE WINDOW 为例, TUMBLE WINDOW 的初衷就是为了产出不变的结果(即 append 流),因此遇到延迟很大的数据才无法处理,那么我们可以将 TUMBLE WINDOW 使用 GROUP AGG(retract 流、或者叫做 CDC 模式)替换去计算。当有迟到的数据时,GROUP AGG 会正常的处理及将上次的结果给撤回,将重新计算的新结果下发下去。但是这种方式存在的问题是如果我们想用 CDC 的模式去运行任务,我们需要全链路都是以 CDC 的模式去运行,包括计算引擎、消息队列、OLAP 引擎等,而且还要保障 Exactly-once。(但是说到 CDC 是不是想到了数据湖?这可能也是后续的一个发展方向)。再以阿里(From FFA 2020)提到的一个分钟\小时累计指标举例,我们看看阿里是怎么做的。实际阿里就是使用 GROUP AGG 做的计算(但是对于后续的链路不知道是否是使用 CDC 的方式运行的)。
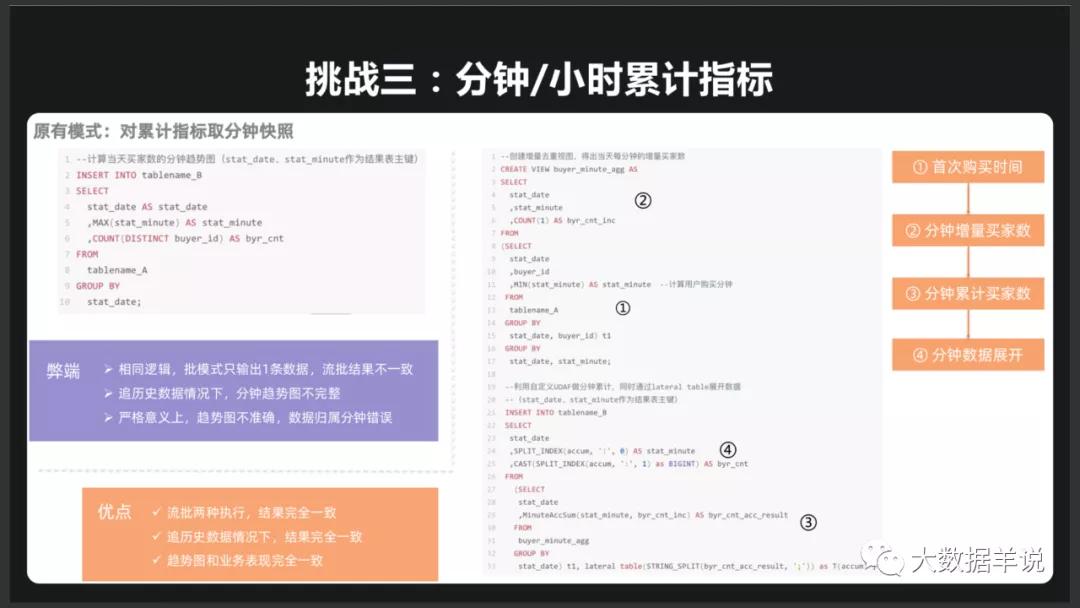
分钟/小时累计指标
阿里的思路(From FFA 2020):如下图阿里所示,场景一是如果流批一体输入源不同,需要批任务调度订正结果,场景二是如果流批结果相同,就不跑批任务了。第一种情况没有啥可说的;但是如果是第二种情况,这里简单分析下:我们知道验证流批结果相同的前提是,跑了批任务产出了结果主动去和流任务的结果去做对比,但是在场景二中实际是批任务并没有运行!!!所以这里能想到的就是需要在事前、事中、事后做很多的监控来保障流任务产出的整体流程没有任何问题,从而保障能达到和预期批任务产出的结果相同。
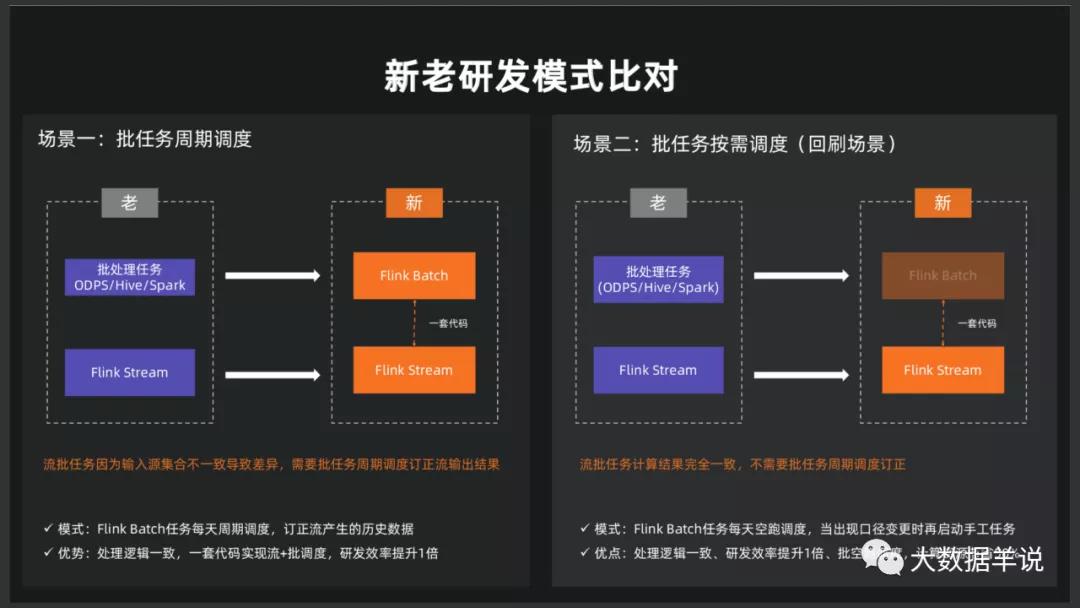
新老研发模式对比
总结:上述的第一种思路相对比较理想化,基本是站在流任务产出的数据可以以批的模式进行复用角度去思考的,撇开了批任务执行这一个过程。第二种阿里 FFA 2020 的思路相比来说对于链路软硬件条件没那么高,博主认为是更具可行性的。
6.总结
本文主要介绍了以下三部分内容:
- 流批一体的诞生是为了解决同一个指标在离线、实时任务产出数据差异问题(数据质量)
- 导致数据差异的根本原因就是数据乱序
- 如果想解决这个问题,理想化就是全链路 CDC,更具操作性的思路可以参考阿里 FFA 2020