












理解聚合
聚合是一组始终需要保持一致的业务对象。因此,我们作为一个整体保存和更新聚合,以确保业务逻辑的一致性。
聚合是 DDD 中最为重要的概念,即使你不使用 DDD 编写代码也需要理解这一重要的概念 —— 部分对象的生命周期可以看做一个整体,从而简化编程。
一般来说,我们需要对聚合内的对象使用 ACID 特性的事务。
最简单的例子就是订单和订单项目,订单项目更新必须伴随订单的更新,否则就会有总价不一致之类的问题。订单项目需要跟随订单的生命周期,我们把订单叫做聚合根,它就像一个导航员一样。
- class Order {
- private Collection<OrderItem> orderItems;
- private int totalPrice;
- }
- class OrderItem {
- private String productId;
- private int price;
- private int count;
- }
Order 的 totalPrice 必须是 OrderItem 的 price 之和,还要考虑折扣等其他问题,总之对象的改变都需要整体更新。
理想中最好的方式就是把聚合根整体持久化,不过问题并没那么简单。
聚合持久化问题
如果你使用 MySQL 等关系型数据库,集合的持久化是一个比较麻烦的事情:
- 关系的映射不好处理,层级比较深的对象不好转换。
- 将数据转换为聚合时会有 n+1 的问题,不好使用关系数据库的联表特性。
- 全量的数据更新数据库的事务较大,性能低下。
- 其他问题
聚合的持久化是 DDD 美好愿景落地的最大拦路虎,这些问题有部分可以被解决而有部分必须取舍。
聚合的持久化到关系数据库的问题,本质是计算机科学的模型问题。
聚合持久化是面向对象模型和关系模型的转换,这也是为什么 MongoDB 没有这个问题,但也用不了关系数据库的特性和能力。
面向对象模型关心的是业务能力承载,关系模型关心的是数据的一致性、低冗余。描述关系模型的理论基础是范式理论,越低的范式就越容易转换到对象模型。
理论指导实践,再来分析这几个问题:
“关系的映射不好处理” 如果我们不使用多对多关系,数据设计到第三范式,可以将关系网退化到一颗树。
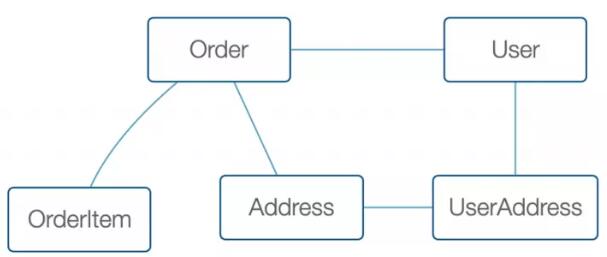
△ 网状的关系
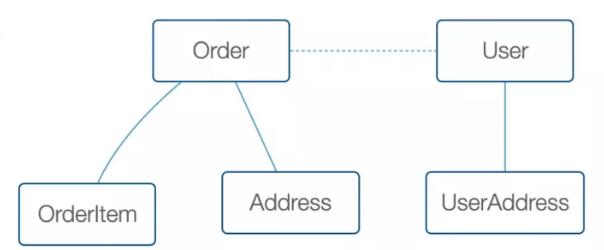
△ 树状的关系
"将数据转换为聚合时会有 n+1 的问题" 使用了聚合就不好使用集合的能力,列表查询可以使用读模型,直接获取结果集,也可以利用聚合对缓存的优势使用缓存减轻 n+1 问题。
"全量的数据更新数据库的事务较大" 设计小聚合,这是业务一致性的代价,基本无法避免,但是对于一般应用来说,写和更新对数据库的频率并不高。使用读写分离即可解决这个问题。
自己实现一个 Repository 层
如果你在使用 Mybatis 或者使用原生的 SQL 来编写程序,你可以自己抽象一个 Repository 层,这层只提供给聚合根使用,所有的对象都需要使用聚合根来完成持久化。
一种方式是,使用 Mybatis Mapper,对 Mapper 再次封装。
- class OrderRepository {
- private OrderMapper orderMapper;
- private OrderItemMapper orderItemMapper;
- public Order get(String orderId) {
- Order order = orderMapper.findById(orderId);
- order.setOrderItems(orderItemMapper.findAllByOrderId(orderId))
- return order;
- }
- }
这种做法有一个小点问题,领域对象 Order 中有 orderItems 这个属性,但是数据库中不可能有 Items,一些开发者会认为这里的 Order 和通常数据库使用的 OrderEntity 不是一类对象,于是进行繁琐的类型转换。
类型转换和多余的一层抽象,加大了工作量。
如果使用 Mybatis,其实更好的方式是直接使用 Mapper 作为 Repository 层,并在 XML 中使用动态 SQL 实现上述代码。
还有一个问题是,一对多的关系,发生了移除操作怎么处理呢?
比较简单的方式是直接删除,再存入新的数组即可,也可以实现对象的对比,有选择的实现删除和增加。
完成了这些,恭喜你,得到了一个完整的 ORM,例如 Hibernate 。
使用 Spring Data JPA
所以我们可以使用 JPA 的级联更新实现聚合根的持久化。
大家在实际操作中发现,JPA 并不好用。
其实这不是 JPA 的问题,是因为 JPA 做的太多了,JPA 不仅有各种状态转换,还有多对多关系。
如果保持克制就可以使用 JPA 实现 DDD,尝试遵守下面的规则:
- 不要使用 @ManyToMany 特性
- 只给聚合根配置 Repository 对象。
- 避免造成网状的关系
- 读写分离。关联等复杂查询,读写分离查询不要给 JPA 做,JPA 只做单个对象的查询
在这些基本的规则下可以使用 @OneToMany 的 cascade 属性来自动保存、更新聚合。
- class Order {
- @Id
- @GeneratedValue(strategy = GenerationType.AUTO)
- private String id;
- @OneToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
- @JoinColumn(name = "order_id")
- private Collection<OrderItem> orderItems;
- private int totalPrice;
- }
- class OrderItem {
- @Id
- @GeneratedValue(strategy = GenerationType.AUTO)
- private String id;
- private String productId;
- private int price;
- private int count;
- }
OneToMany 中的 cascade 有不同的属性,如果需要让更新、删除都有效可以设置为 ALL。
使用 Spring Dat JDBC
Mybatis 就是一个 SQL 模板引擎,而 JPA 做的太多,有没有一个适中的 ORM 来持久化聚合呢?
Spring Data JDBC 就是人们设计出来持久化聚合,从名字来看他不是 JDBC,而是使用 JDBC 实现了部分 JPA 的规范,让你可以继续使用 Spring Data 的编程习惯。
Spring Dat JDBC 的一些特点:
- 没有 Hibernate 中 session 的概念,没有对象的各种状态
- 没有懒加载,保持对象的完整性
- 除了 SPring Data 的基本功能,保持简单,只有保存方法、事务、审计注解、简单的查询方法等。
- 可以搭配 JOOQ 或 Mybatis 实现复杂的查询能力。
Spring Dat JDBC 的使用方式和 JPA 几乎没有区别,就不浪费时间贴代码了。
如果你使用 Spring Boot,可以直接使用 spring-boot-starter-data-jdbc 完成配置:
- spring-boot-starter-data-jdbc
不过需要注意的是,Spring Data JDBC 的逻辑:
- 如果聚合根是一个新的对象,Spring Data JDBC 会递归保存所有的关联对象。
- 如果聚合根是一个旧的对象,Spring Data JDBC 会删除除了聚合根之外旧的对象再插入,聚合根会被更新。因为没有之前对象的状态,这是一种不得不做的事情。也可以按照自己策略覆盖相关方法。
使用 Domain Service 变通处理
正是因为和 ORM 一起时候会有各种限制,而抽象一个 Repository 层会带来大的成本,所以有一种变通的方法。
这种方法不使用充血模型、也不让 Repository 来保证聚合的一致性,而是使用领域服务来实现相关逻辑,但会被批评为 DDD lite 或不是 “纯正的 DDD”。
这种编程范式有如下规则:
- 按照 DDD 四层模型,Application Service 和 Domain Service 分开,Application Service 负责业务编排,不是必须的一层,可以由 UI 层兼任。
- 一个聚合使用 DomainService 来保持业务的一致性,一个聚合只有一个 Domain Service。Domain Service 内使用 ORM 的各种持久化技术。
- 除了 Domain Service 不允许其他地方之间使用 ORM 更新数据。
当不被充血模型困住的时候,问题变得更清晰。
DDD 只是手段不是目的,对一般业务系统而言,充血模型不是必要的,我们的目的是让编码和业务清晰。
这里引入两个概念:
- 业务主体。操作领域模型的拟人化对象,用来承载业务规则,也就是 Domain Service,比如订单聚合可以由一个服务来管理,保证业务的一致性。我们可以命名为:OrderManager.
- 业务客体。聚合和领域对象,用来承载业务属性和数据。这些对象需要有状态和自己的生命周期,比如 Order、OrderItem。
回归到原始的编程哲学:
程序 = 数据结构 + 算法
业务主体负责业务规则(算法),业务客体负责业务属性和数据(数据结构),那么用不用 DDD 都能让代码清晰、明白和容易处理了。
【本文是51CTO专栏作者“ThoughtWorks”的原创稿件,微信公众号:思特沃克,转载请联系原作者】























