













大家好,我是yes。
之前在写 FastThreadLocal 的时候,挖了个坑。
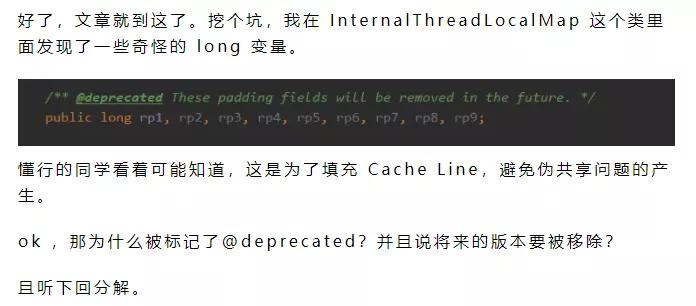
咳咳,时间过得有点久了,但是影响不大今天就来补上。
来谈谈什么是伪共享,并且为什么 Netty 要在这里移除这个优化?
话不多说,发车!
什么是伪共享?
这个名词听着有点高级的感觉,实际上很好理解。
我们都知道 CPU 的执行速度远大于从内存获取数据的速度,为了减少这个差距科研人员们就不断的研究,产出了高速缓存,但这个高速缓存由于工艺集成度问题,无法作为主存的介质,所以常见的 CPU 缓存结构如下图所示:
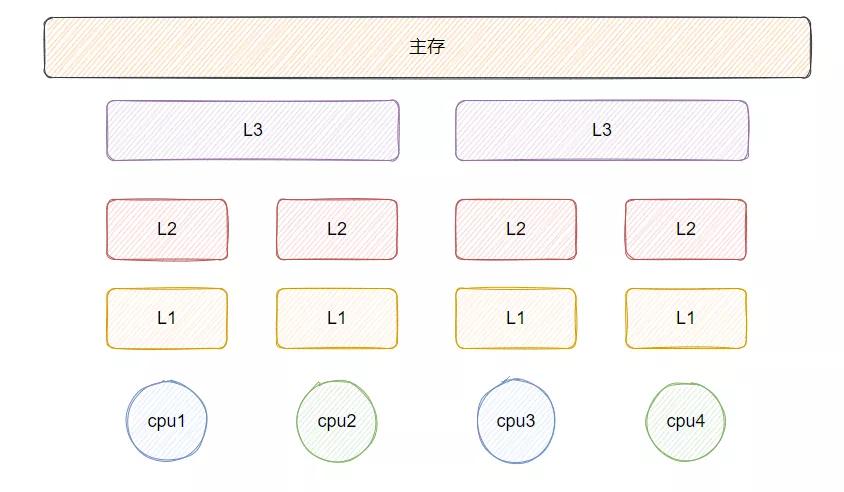
L1、L2、L3则为 CPU 和主存之间的高速缓冲区,距离 CPU 越近的缓存访问速度越快,且容量越小。
比如我笔记本的 CPU上:
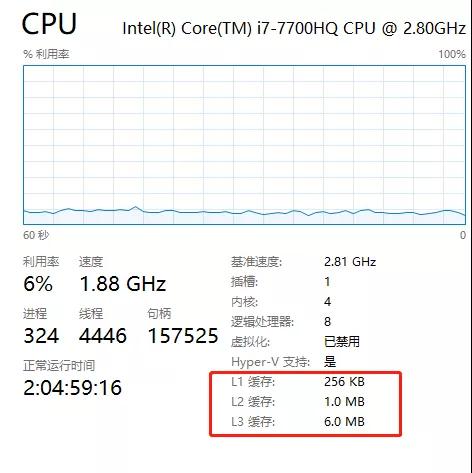
访问速度:L1>L2>L3>主存。
L1 和 L2 是单核 CPU 独享的,当 CPU 访问数据的时候会先去 L1 上面找,找不到再去 L2,然后是 L3,最后是主存。所以当对一个数据重复计算的时候,应该尽量保证数据在 L1 中,这样效率才高。
从上面的结构来看,有经验的同学肯定会发现上面的结构有共享内存多线程的问题。这里就引入了一致性协议 MESI。具体协议内容这里不作展开,这里简单举例理解下:
当 cpu1 和 cpu3 共同访问主存里面的一个数据时,会分别获取放置到自己高速缓冲区中,当 cpu1 修改了这个数据之后,cpu3 的高速缓冲区中这个数据就失效了,它会让 cpu1 把这个改动刷新到主存中,然后自己再去主存加载这个数据,这样数据才会正确。
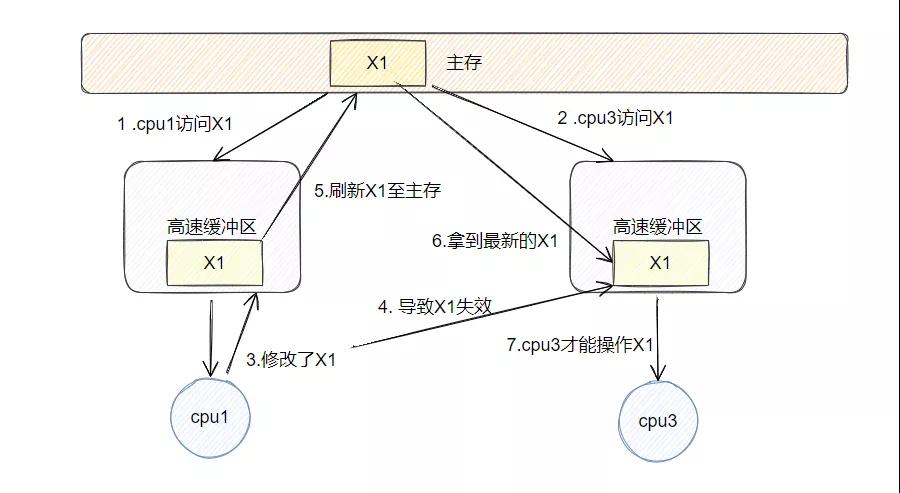
图中按序号顺序来阅读,应该不难理解。
然后重点来了,CPU 缓存的单位是缓存行,也就是说 CPU 从主存拿数据不是一个一个拿,是一行一行的拿,这一行的大小一般是 64 字节,那问题就来了。
比如,现在有个 long 数组,大小为 8 ,那刚好这个数组满足一行的大小。现在 cpu1 频繁更新long[0]的值,而 cpu3 频繁更新 long[5] 的值,这就有点麻了。
由于缓存行的机制,每次 cpu1 会把整个数组都加载到缓存中,每次仅修改 long[0] 也会使得这一行都变脏,此时 cpu3 访问的 long[5] 就失效了,因此 cpu3 需要让 cpu1 把修改刷新到主存中,然后它从主存重新获取 long[5] 再进行操作,假设此时 cpu1 又修改了 long[0],则上面的操作就又得来一遍!
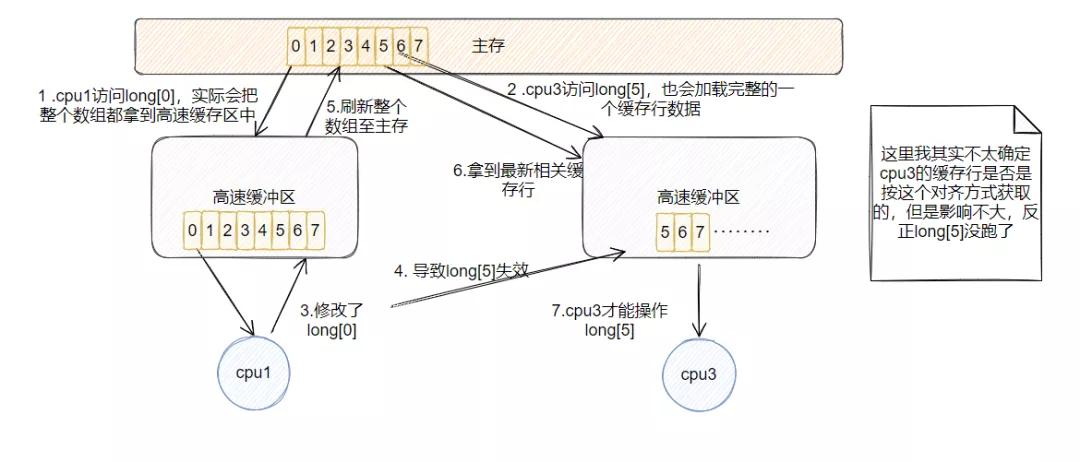
明明修改的是不同的变量,但是却相互影响了,这种情况,就称之为,伪共享!
如何避免伪共享问题?
解决的方案非常简单粗暴,填充。
把可能会冲突的数据在内存上隔开来,用什么隔?用无用的数据隔开。
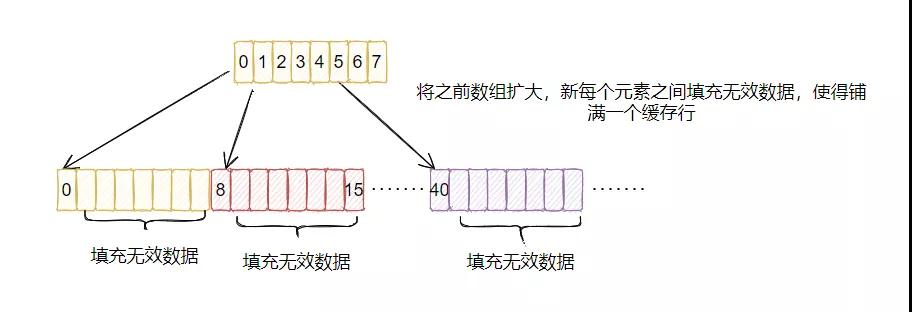
在关键数据前后(上图仅填充了后)填充无用的数据,让一个缓存行中,仅会存在一个有效的数据,其它都是无效的数据,就避免了一个缓存行里面出现多个有效的数据。这样一来不同的 CPU 核心修改不同的数据就不会造成其它数据缓存失效,避免了伪共享的问题。
所以 Netty 里 InternalThreadLocalMap 中奇怪的代码就是起这个作用的。

但恕我直言,可能是我等级太低,我没看出来这玩意到底是为了哪个变量而填充的。
果然,最新的版本有个大佬把它标注为废弃。

我从 github 上看了看,大佬将其废弃的理由如下:
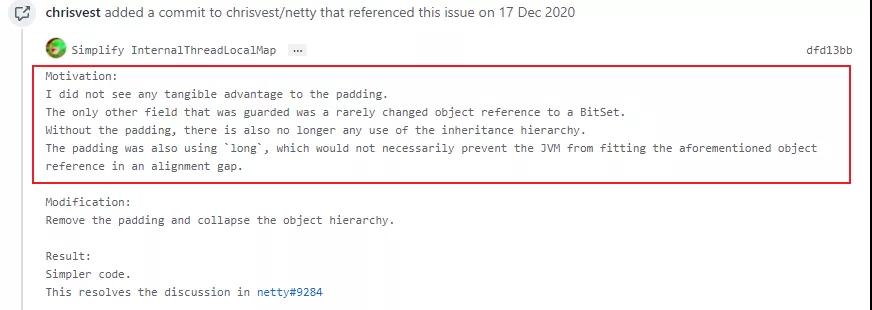
简单直白的翻译下:
我看不出填充有什么切实的好处。
唯一保护的对象可能是 BitSet,但是它的修改并不频繁
填充用了 long,这并不一定会阻止 JVM 在对齐间隙中匹配上述的对象引用。
简单来讲就是没发现这填充有啥好用,所以废弃了,将来版本要咔嚓了它。
所以拿 Netty 来展示伪共享的例子不行(我只是把之前写 FastThreadLocal 的坑填了)。
现在填完了,我们换个好的例子。
用代码跑跑看
我写了个例子,咱们来看看填充和不填充的真实差距。
我用两个线程分别循环五千万次修改一个对象里面的两个变量 a 和 b,这两个变量大概率会在同一个缓存行中,这样就制造了伪共享的现场。
在未填充的情况下,耗费的毫秒数是1400。
然后我们再用变量p1-p7填充一下,隔开 a 和 b。
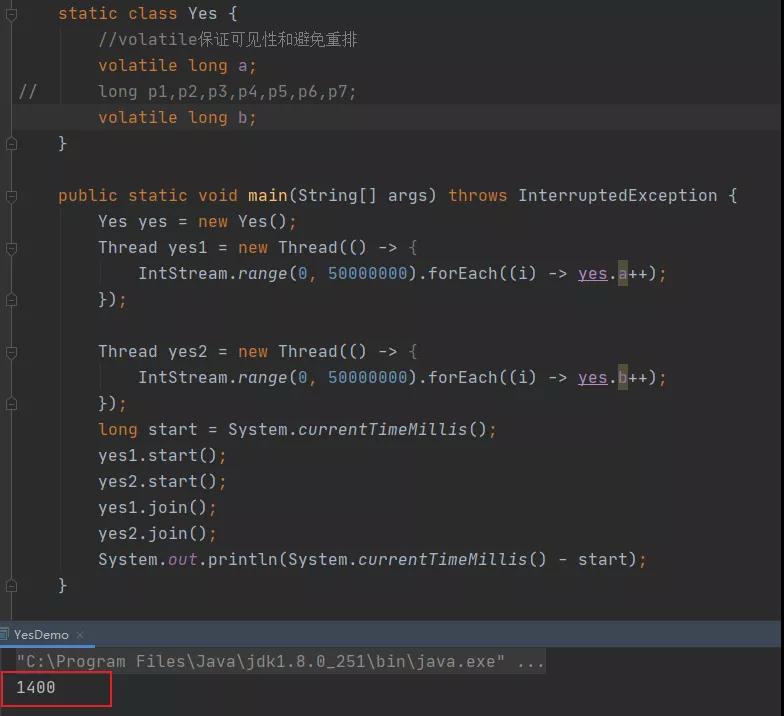
可以看到,结果变成了380毫秒,这么一看,确实生效了!说明填充确实有效!
其实 Java 提供了一个注解 @Contended,可以标记到指定的字段上,减少伪共享的发生,你可以认为这个注解会让 JVM 自动帮我们填充,而不需要我们手写填充的变量。不过要注意一点,这个注解需要启动时添加-XX:-RestrictContended 参数,才会生效。

我们跑一下看下结果:
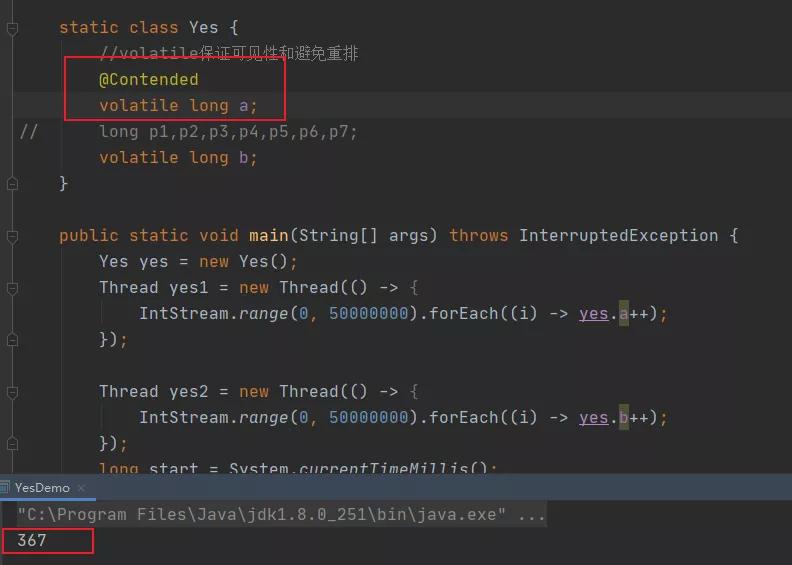
果然,也提高了效率!
这个注解其实在别的地方也有应用,比如 ConcurrentHashMap 里的 CounterCell

还有 Striped64 里的 Cell
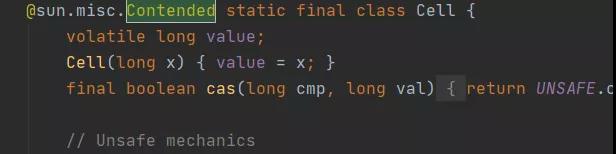
不过要注意,没有-XX:-RestrictContended 不会生效的!
最后
至此,想必你已经明白了什么是伪共享,并且可以利用填充来避免伪共享的问题。
但填充就代表着空间的浪费,也不是什么情况下都需要填充。
只有在频繁更新相邻字段的情况下,才可能需要考虑伪共享的情况,别的情况不需要下操心。
好了,今天就到这了。




















