












本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
马斯克旗下的SpaceX可以说带火了“火箭回收”这一话题。
这不,连粉丝们都已经开始摩拳擦掌,用自己的方式挑战起了这个技术难题。
例如一位来自密歇根大学的华人博士,就用强化学习试了一把回收火箭!
他根据现实中的星舰10号一通进行模拟,还真在虚拟环境中稳稳地完成了悬停和着陆!

这个项目迅速在Reddit上引发了大批网友们的关注:

那么,他是如何实现的呢?
给火箭回收设立“奖励机制”
要在模拟环境中回收火箭,那么大一只构造复杂的火箭肯定是不能直接抱来用的。
于是,这位SpaceX的铁杆粉丝首先基于气缸动力学,将火箭简化为一个二维平面上的刚体:
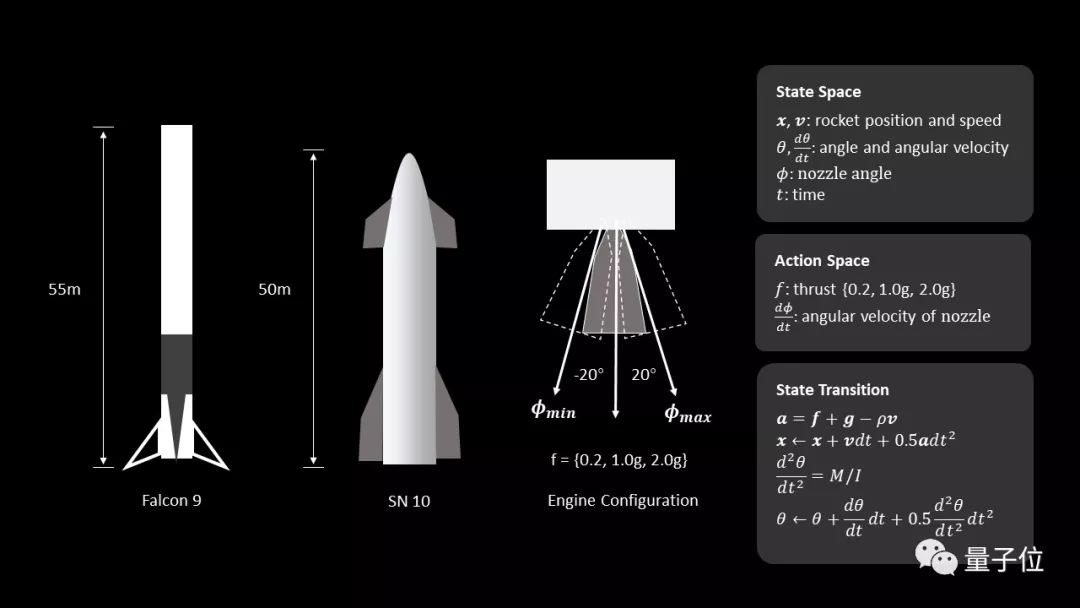
这个火箭的底部安装有推力矢量发动机,能够提供不同方向的可调的推力值(0.2g,1.0g和2.0g);同时,火箭喷嘴上还增加了一个角速度约束,最大转速为30°/秒。
火箭模型所受到的空气阻力则设定为与速度成正比。
现在,这个模型的一些基本属性就能够以下面两个集合来表示:
- 动作空间:发动机离散控制信号的集合,包括推力加速度和喷嘴角速度
- 状态空间:由火箭位置、速度、角度、角速度、喷管角度和仿真时间组成的集合
而“火箭回收”这一流程,则被分为了悬停和着陆两个任务。
在悬停任务中,火箭模型需要遵循这样一种奖励机制:
- 火箭与预定目标点的距离:距离越近,奖励越大;
- 火箭体的角度:火箭应该尽可能保持竖直
着陆任务则基于星舰10号的基本参数,将火箭模型的初始速度设置为-50米/秒,方向设置为90°(水平方向),着陆燃烧高度设置为离地面500米。

△星舰10号发射和着陆的合成图像
火箭模型在着陆时同样需要遵循这样一种“奖励机制”:
当着陆速度小于安全阈值,并且角度接近竖直0°时,就会受到最大的“奖励”,也会被认为是一次成功的着陆。
总体而言,这是一个基于策略的参与者-评判者的模型。
接下来就是进行训练:
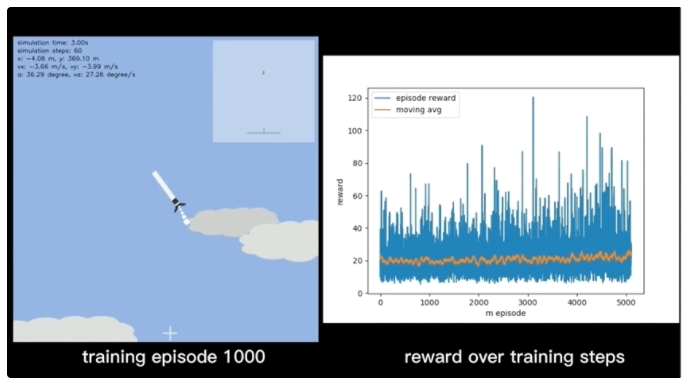
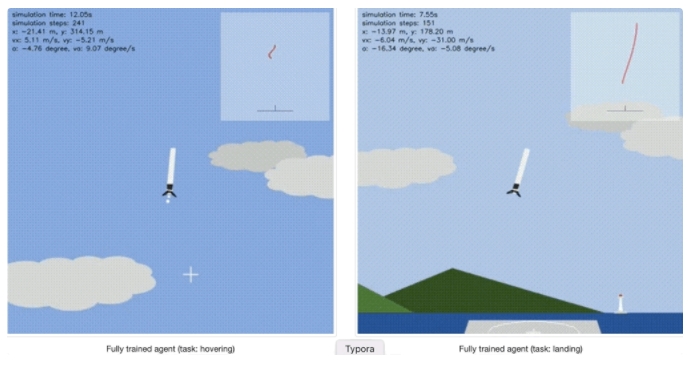
最终,在经历了20000次的训练后,火箭模型在悬停和着陆两个任务上都实现了较好的效果:
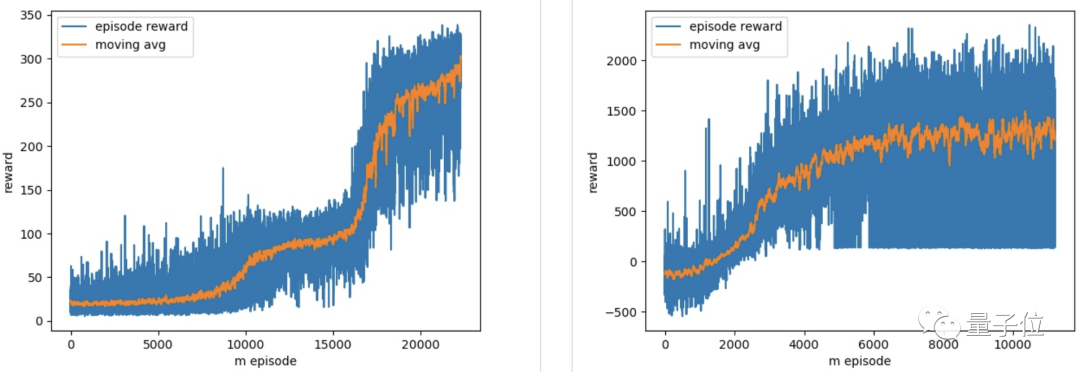
最终,模型得到了很好的收敛效果:
而这枚模拟环境中的伪·星舰10号,也就像开头展示的那张动图一样,学会了腹部着陆,稳稳地落地了。
下一步:增加燃料变量
这一项目一经发出,就引来了红迪众多网友的围观和称赞。
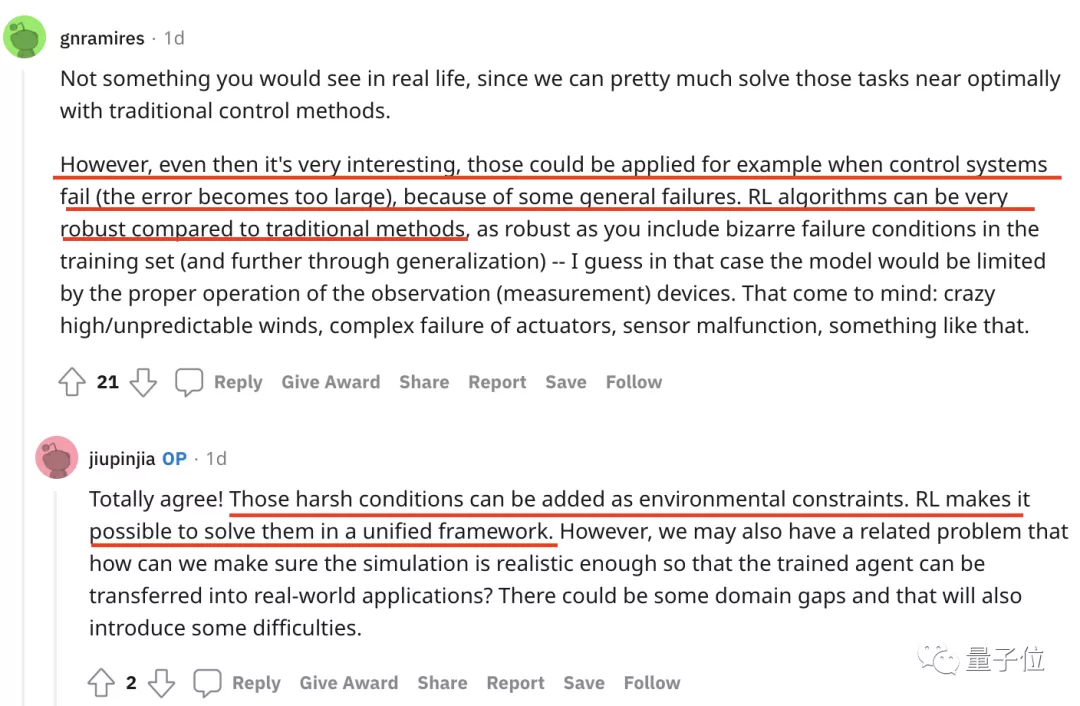
有人觉得用强化学习来解决传统任务非常有趣,因为它具有更好的鲁棒性。
作者也在下方回复表示:现实中恶劣的环境条件可以成为环境制约因素,而强化学习则能在一个统一的框架内解决这些问题。
不过在称赞之余,也有网友提出了最直接的这样一个问题:
既然我们已经可以使用经典控制方法找到这些任务的最优解,那为啥SpaceX之前没人做?

下方有人解答到:这或许是因为之前的数字控制系统、传感器等技术并不成熟,采用新方法就意味着要重新设计火箭的关键部分。
这也就是控制系统层面之外的“工程类的问题”,而SpaceX正是在这些相关领域中做了改进。
而那些较为传统保守的航天航空工业则会使用使用凸优化(Convexification)来解决火箭着陆问题。
也就是评论区有人贴出的这篇论文中提到的方法:

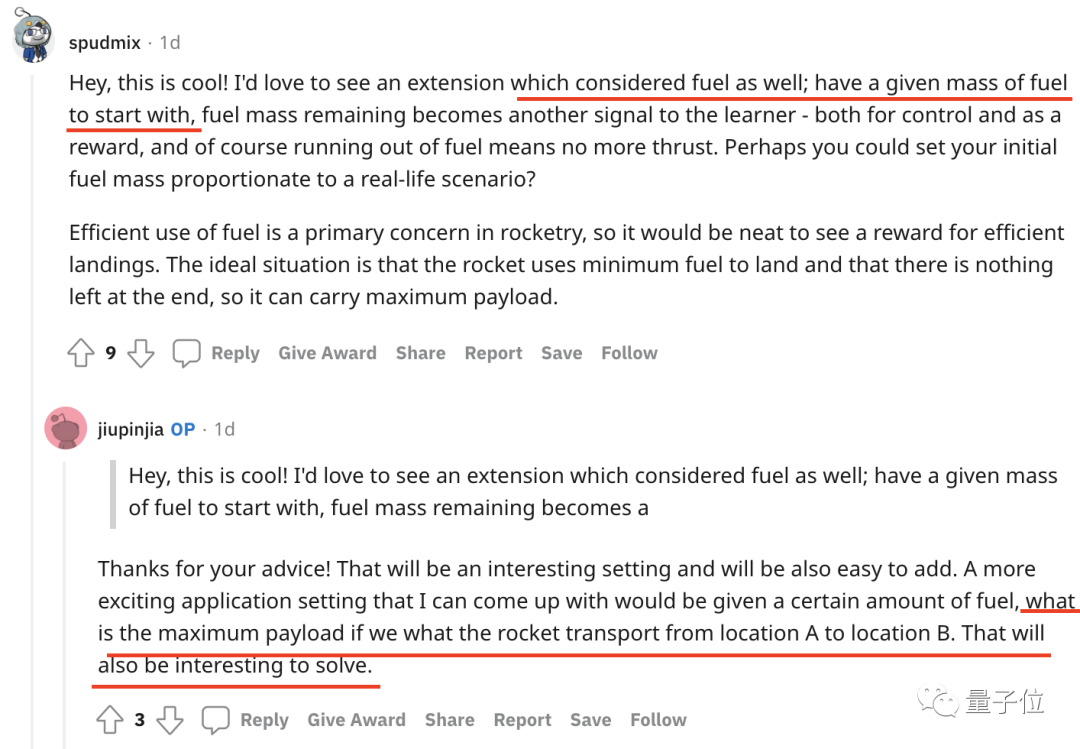
不少评论也为开发者提供了下一步开发的新思路,比如这条评论建议将“剩余燃料”也作为一个变量,模型燃料的减少或耗尽也是现实中的一个重要影响因素。
作者欣然接受了这一建议:是很容易添加的有趣设置,安排!
密歇根大学华人博士
开发者已经为这一项目建立了一个网站,在主页他这样介绍到:
这是我的第一个强化学习项目,所以,我希望通过这些“低水平代码”尽可能地从头实现包括环境、火箭动力学和强化学习agent在内的所有内容。

作者叫Zhengxia Zou,是一位来自密歇根大学博士,主要研究计算机视觉、遥感、自动驾驶等领域。
他的论文曾被 ICCV 2021、CVPR 2021等多个顶会收录:

下载链接:
https://github.com/jiupinjia/rocket-recycling
项目主页:
https://jiupinjia.github.io/rocket-recycling/

























