工程架构方向的程序员,看到推荐/搜索/广告等和算法相关的技术,心中或多或少有一丝胆怯。但认真研究之后,发现其实没有这么难。
今天给大家介绍下推荐系统中的“协同过滤”,绝无任何公式,保证大伙弄懂。
什么是协同过滤(Collaborative Filtering)?
答:通过找到兴趣相投,或者有共同经验的群体,来向用户推荐感兴趣的信息。
举例,如何协同过滤,来对用户A进行电影推荐?
答:简要步骤如下:
(1)找到用户A(user_id_1)的兴趣爱好;
(2)找到与用户A(user_id_1)具有相同电影兴趣爱好的用户群体集合Set
(3)找到该群体喜欢的电影集合Set
(4)将这些电影Set
具体实施步骤如何?
答:简要步骤如下:
(1)画一个大表格,横坐标是所有的movie_id,纵坐标所有的user_id,交叉处代表这个用户喜爱这部电影;
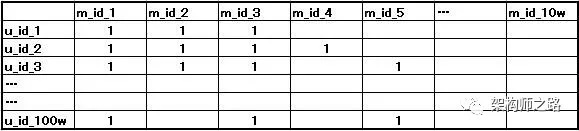
如上表:
- 横坐标,假设有10w部电影,所以横坐标有10w个movie_id,数据来源自数据库
- 纵坐标,假设有100w个用户,所以纵坐标有100w个user_id,数据也来自数据库
- 交叉处,“1”代表用户喜爱这部电影,数据来自日志
画外音:什么是“喜欢”,需要人为定义,例如浏览过,查找过,点赞过,反正日志里有这些数据。
(2)找到用户A(user_id_1)的兴趣爱好;
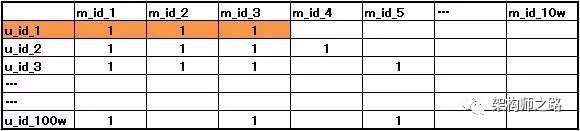
如上表,可以看到,用户A喜欢电影{m1, m2, m3}
(3)找到与用户A(user_id_1)具有相同电影兴趣爱好的用户群体集合Set<user_id>
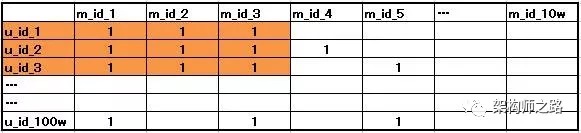
如上表,可以看到,喜欢{m1, m2, m3}的用户,除了u1,还有{u2, u3}
(4)找到该群体喜欢的电影集合Set<user_id>
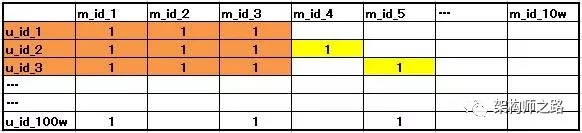
如上表,具备相同喜好的用户群里{u2, u3},还喜好的电影集合是{m4, m5}
画外音:“协同”就体现在这里。
(5)未来用户A(use_id_1)来访问网站时,要推荐电影{m4, m5}给ta。
协同过滤大致原理如上,希望大家有收获。
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】