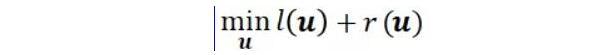近期,来自清华大学的研究者们提出了一种简单高效的 NLP 学习框架。不同于当下 NLP 社区主流的大规模预训练 + 下游任务微调(pretraining-finetuning)的范式,这一框架无需进行大规模预训练。相较于传统的预训练语言模型,该框架将训练效率 (Training FLOPs) 提升了两个数量级,并且在多个 NLP 任务上实现了比肩甚至超出预训练模型的性能。这一研究结果对大规模预训练语言模型的必要性提出了质疑:大规模预训练对下游任务的贡献究竟有多大?我们真的需要大规模预训练来达到最好的效果吗?

- 论文地址:https://arxiv.org/pdf/2111.04130.pdf
- 项目地址:https://github.com/yaoxingcheng/TLM
预训练语言模型因其强大的性能被广泛关注,基于预训练 - 微调(pretraining-finetuning)的范式也已经成为许多 NLP 任务的标准方法。然而,当前通用语言模型的预训练成本极其高昂,这使得只有少数资源充足的研究机构或者组织能够对其展开探索。这种 「昂贵而集权」的研究模式限制了平民研究者们为 NLP 社区做出贡献的边界,甚至为该领域的长期发展带来了障碍。
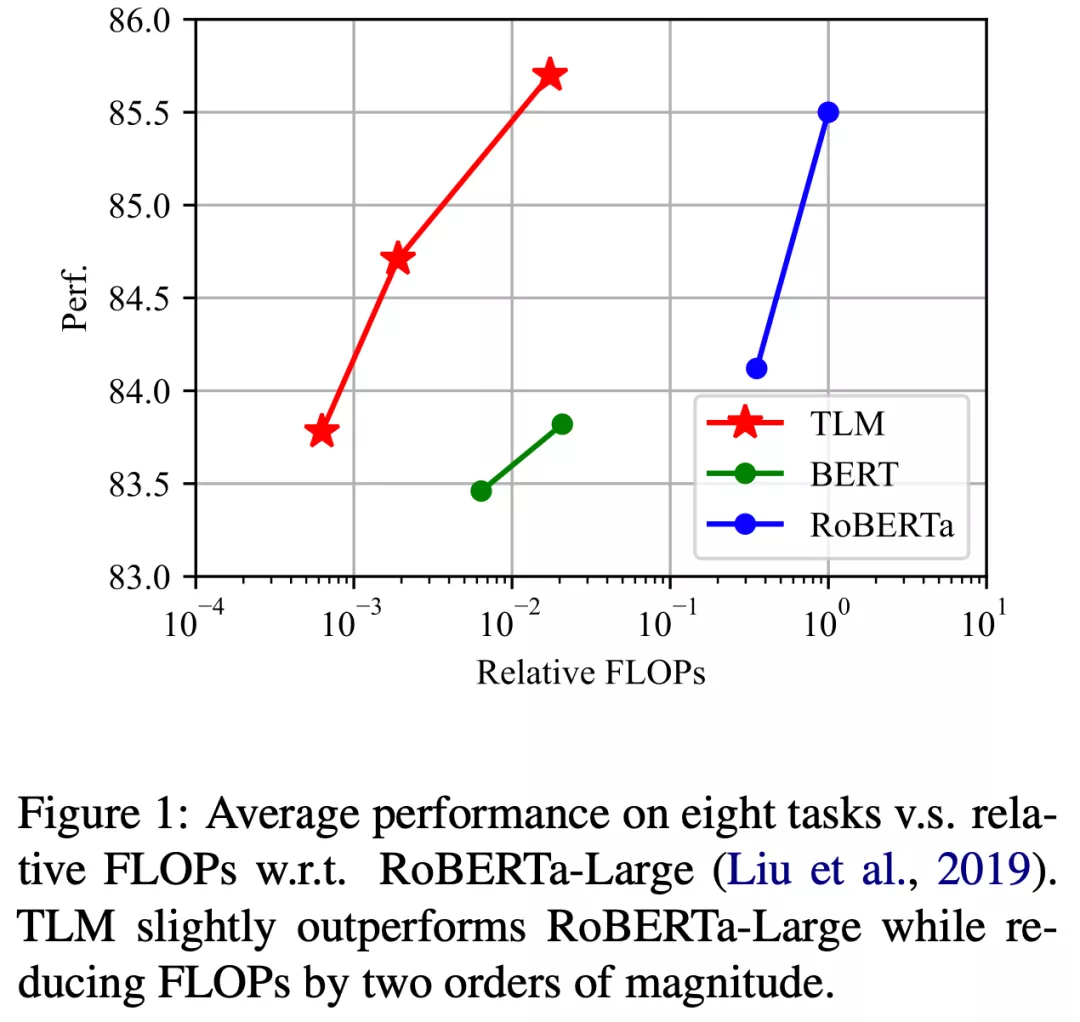
近期,为了缓解这一现状,来自清华大学的研究者们提出的一种完全不需要预训练语言模型的高效学习框架。这一框架从通用语料中筛选出与下游任务相关的子集,并将语言建模任务与下游任务进行联合训练。研究者们称之为 TLM (Task-driven Language Modeling)。相较于传统的预训练模型(例如 RoBERTa),TLM 仅需要约 1% 的训练时间与 1% 的语料,即可在众多 NLP 任务上比肩甚至超出预训练模型的性能(如图 1 所示)。研究者们希望 TLM 的提出能够引发更多对现有预训练微调范式的思考,并推动 NLP 民主化的进程。
语言模型会「抱佛脚」吗? 任务驱动的语言建模
TLM 提出的动机源于一个简单的观察:人类可以通过仅对关键信息的学习,以有限的时间和精力快速掌握某一任务技能。例如,在临考抱佛脚时,焦虑的学生仅需要根据考纲复习浏览若干相关章节即可应对考试,而不必学习所有可能的知识点。类似地,我们也可以推测:预训练语言模型在下游任务上的优良表现,绝大多数来源于语料中与下游任务相关的数据;仅利用下游任务相关数据,我们便可以取得与全量数据类似的结果。
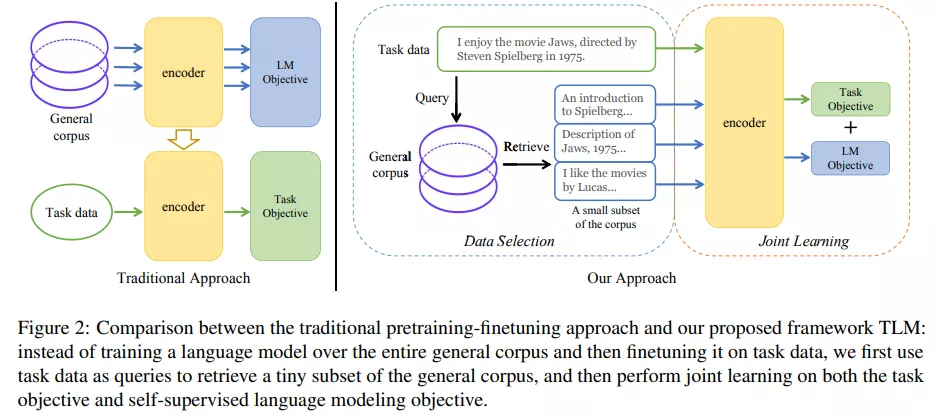
为了从大规模通用语料中抽取关键数据,TLM 首先以任务数据作为查询,对通用语料库进行相似数据的召回。这里作者选用基于稀疏特征的 BM25 算法[2] 作为召回算法。之后,TLM 基于任务数据和召回数据,同时优化任务目标和语言建模目标 (如下图公式所示),从零开始进行联合训练。
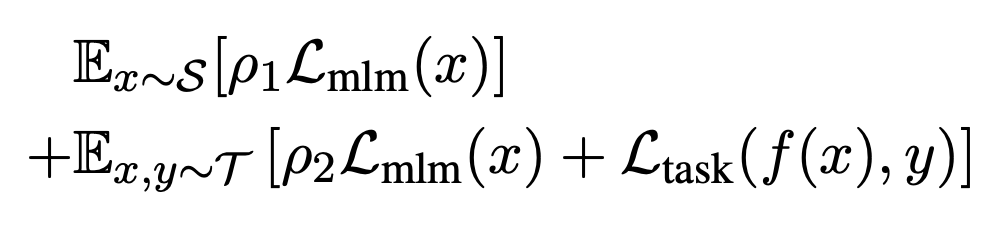
1% 的算力 + 1% 的语料即可比肩预训练语言模型
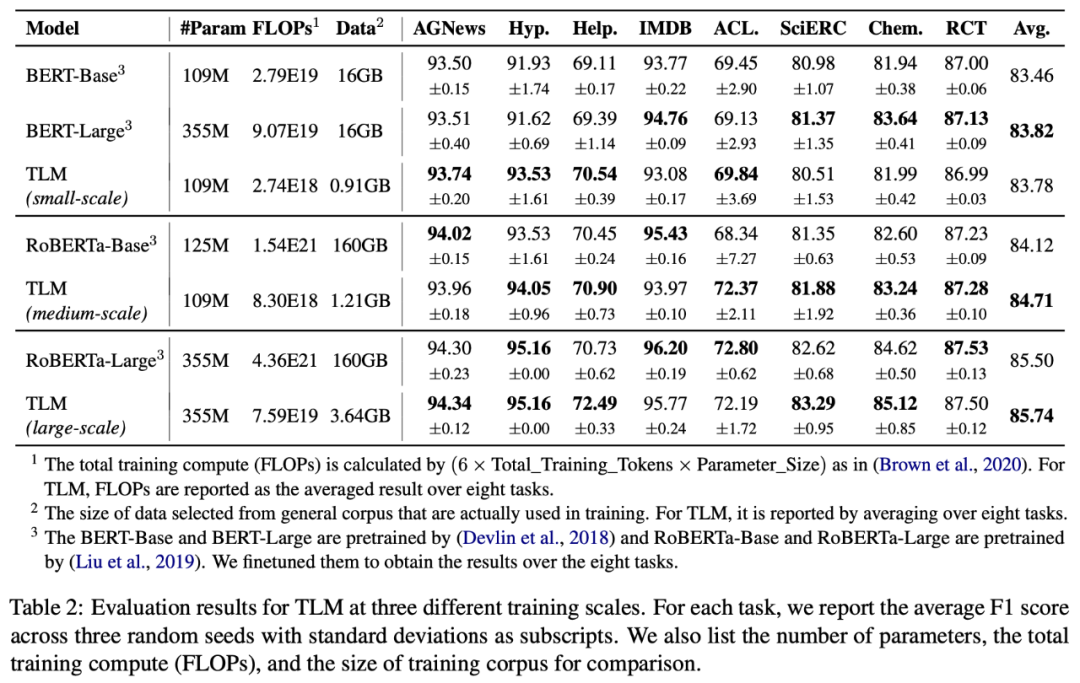
为了测试 TLM 的性能,研究者们在 8 个 NLP 分类任务上从三个不同规模展开了对比实验。这 8 个任务涵盖了计算机科学、生物医药、新闻、评论等 4 个领域,包括了训练样本数量小于 5000 的低资源任务(Hyperpartisan News, ACL-ARC, SciERC, Chemprot)和训练样本数量大于 20000 的高资源任务(IMDB, AGNews, Helpfulness, RCT),覆盖了话题分类,情感分类,实体关系抽取等任务类型。从实验结果可以看出,和对应预训练 - 微调基准相比,TLM 实现了相当甚至更优的性能。平均而言,TLM 减少了两个数量级规模的训练计算量 (Training FLOPs) 以及训练语料的规模。
任务驱动的语言建模(TLM) vs 预训练语言模型(PLMs)
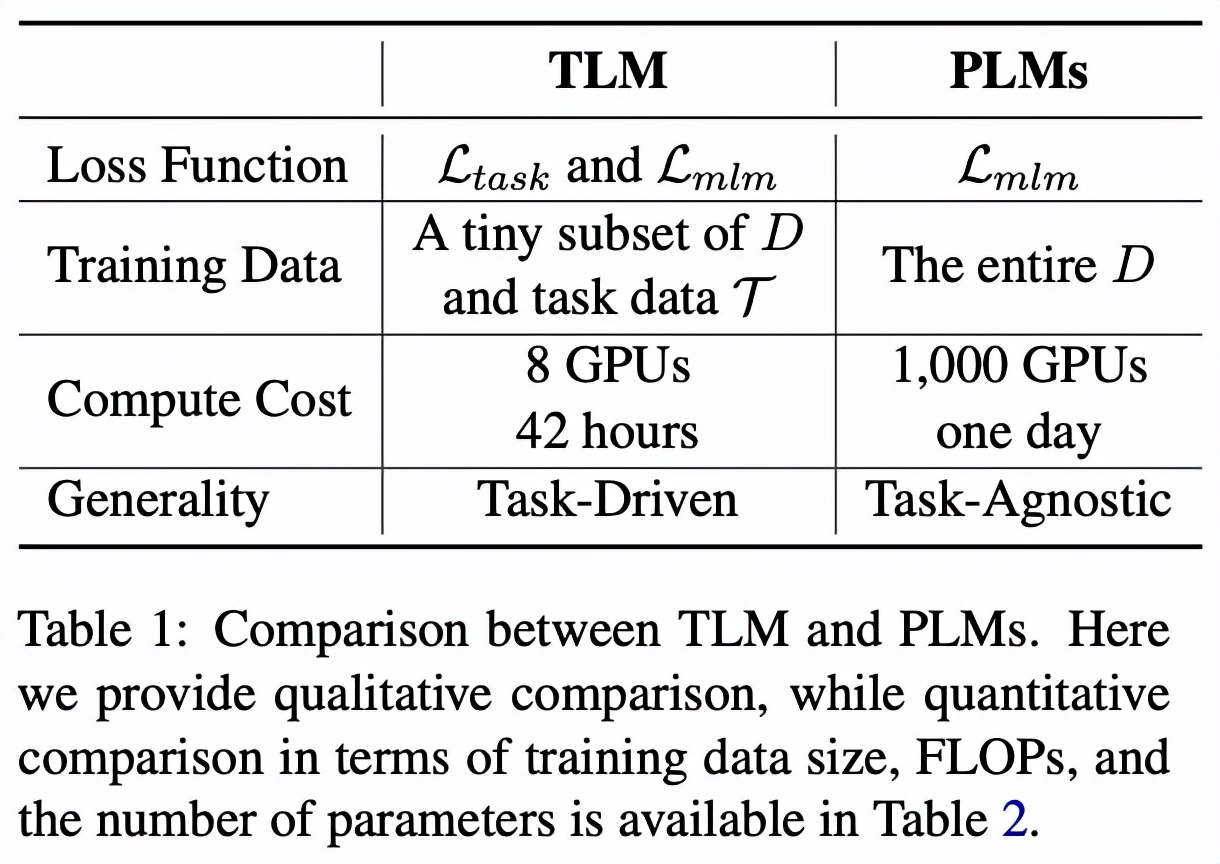
表格 1 直接对比了 TLM 和 PLM。整体来说,PLM 以极高的成本学习尽可能多的任务无关的知识,而 TLM 以非常低的成本针对每个任务学习相关知识。对比 TLM 和 PLM 有如下几个方面特点。
1.推动 NLP 研究公平化和民主化(Democratization)
预训练本身严重依赖大量的计算资源,这一限制使得大多数 NLP 研究者专项对微调算法的研究。然而微调性能上限很大程度上受预训练模型性能的约束。而 TLM 使得大多数研究人员可以以较低的代价和较高的效率,基于最先进的解决方案对模型架构、损失函数、算法等方面进一步自由探索。
2. 高效性(Efficiency)
TLM 在平均每个任务的 FLOPs 消耗方面显著优于 PLM。当我们有少数目标任务需要解决的时候(例如研究人员希望对少量几个数据集进行研究),TLM 会是非常高效的;然而当需要一次性解决大量任务时(例如工业界构建一个 NLP 平台为多方提供相似的服务),PLM 仍然具有优势。
3. 灵活性(Flexibility)
TLM 是任务驱动的,所以可以给研究人员更大的自由度,从而自定义策略进行标记、序列长度、数据表示、超参数的调整等等,从而达到提高性能和效率的目的。
4. 通用性(Generality)
PLM 学习与任务无关的一般性表示,可用于小样本和零样本学习,而 TLM 通过学习任务相关的表示一定程度牺牲通用型换取效率。从这个意义上,TLM 需要在通用型方面进一步提升。此外也可以 PLM 和 TLM 结合从而在通用性和效率之间实现更好的权衡。
深入观察 TLM:让更多参数为下游任务服务

为了深入了解 TLM 的工作机制,研究人员对模型每个注意力头所输出的注意力分数进行了可视化。可以观察到,TLM 的注意力模式中包含了更多的「对角线」模式(图 3 红框),也即大多 token 都将注意力分数集中赋予了其邻近 token,这种模式已在前人的工作 [1] 中被证明对模型的最终预测有着重要贡献。而预训练模型(BERT, RoBERTa)中则包含了大量「垂直」模式的注意力头(图 3 灰色区域),也即大多 token 都将注意力分数集中赋予了 [CLS],[SEP] 或者句号这种毫无语义或者句法信息的词汇上。这一现象表明 TLM 中参数利用率要显著高于预训练语言模型,TLM 或许针对下游任务学习到了更加富有语义信息的表示。
总结
TLM 的提出让 NLP 研究跳脱出预训练微调范式成为了可能,这使得 NLP 研究者们可以更为自由地探索新兴的模型结构与训练框架,而不拘泥于大规模预训练模型。在未来,更多有趣的研究可以在 TLM 的基础上展开,例如:如何经济地达到更大规模预训练模型的表现效果;如何提升 TLM 的通用性与可迁移性;可否利用 TLM 进行小样本或零样本学习等等。