













一、超时现象反馈
在发布卡点过程中,有同学反馈在发布过程中存在偶发性超时情况。集中在上下游服务较多节点的服务,几十个上百个节点的服务较多。不是必然出现,一批服务偶尔有一个节点出现。刚出现的前几例由于没有触发线程dump一直定位不到哪里的问题。
RPC框架中服务端线程池默认使用线程超过80%会触发线程dump,方便观察运行状态。直到有两个服务触发了dump才把这个谜底揭开。
二、超时现象跟踪
链路日志: 客户端AppXXXService调用服务Appxxx发生超时,长达50秒。
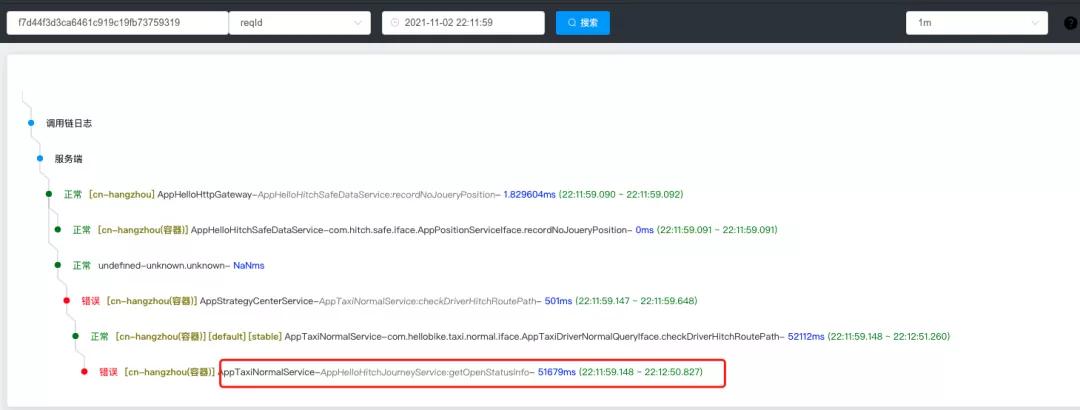
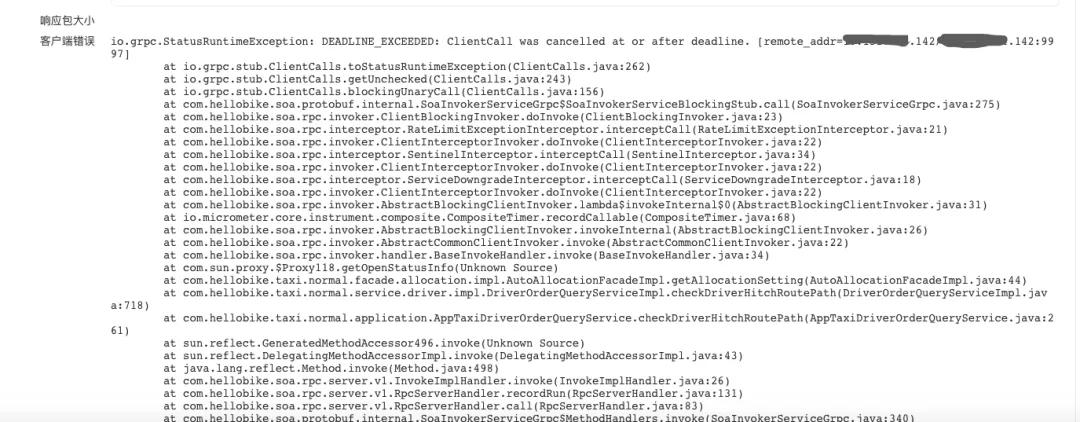
服务消费方报错信息:
客户端等待中取消请求,发生调用时间为:2021-11-02 22:11:59.148
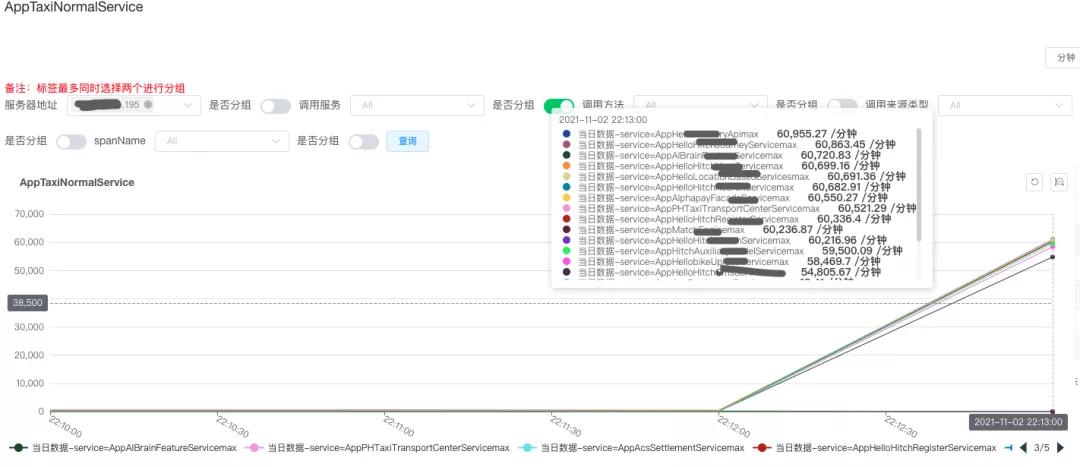
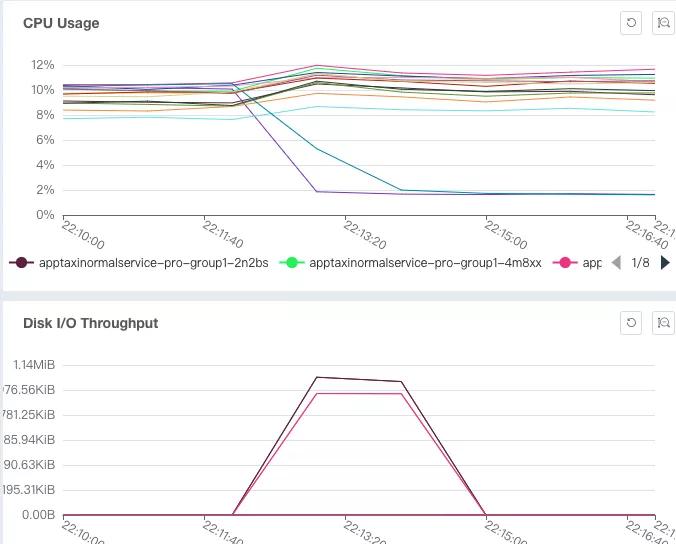
耗时监控曲线:该服务基本上在同一时间段发起向下游的服务均发生超时。
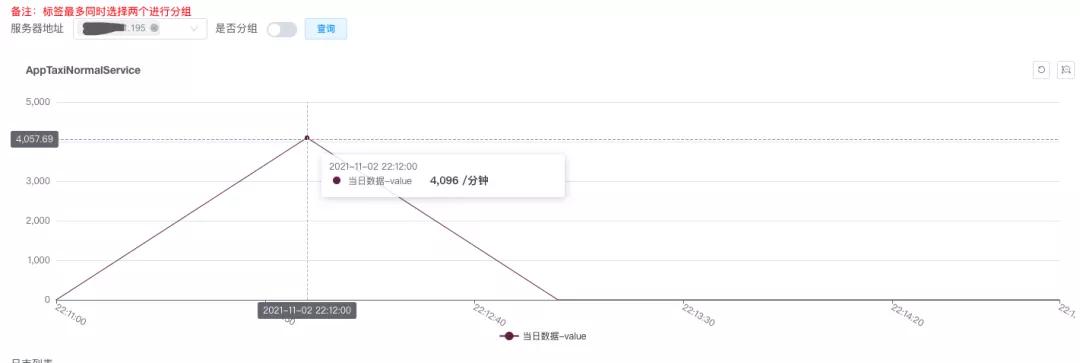
服务端队列监控:队列显示瞬间增加很多任务
磁盘IO和CPU都有上升
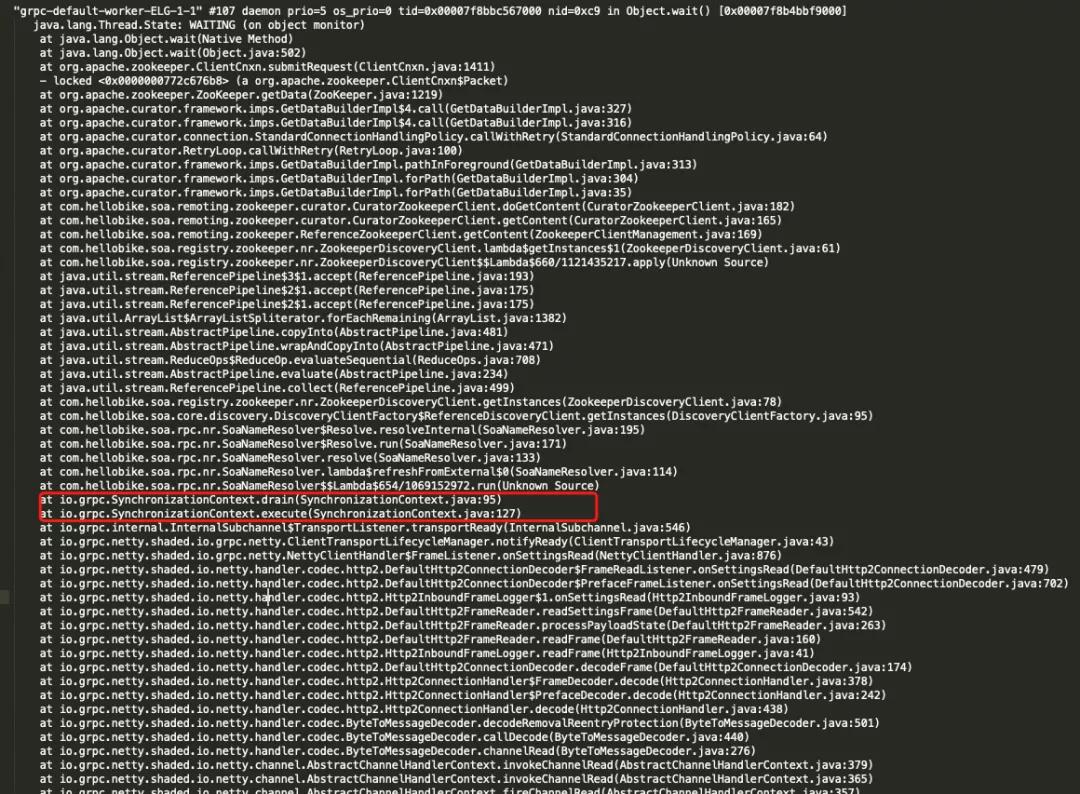
线程dump情况,通信线程调用到了SynchronizationContext,底层的work通信线程怎么调用到了获取节点的业务方法去了。
三、问题根因
RPC框架中代码中有使用SynchronizationContext,此处与gRPC共用。

SynchronizationContext使用的queue是ConcurrentLinkedQueue队列,被单线程串行执行。
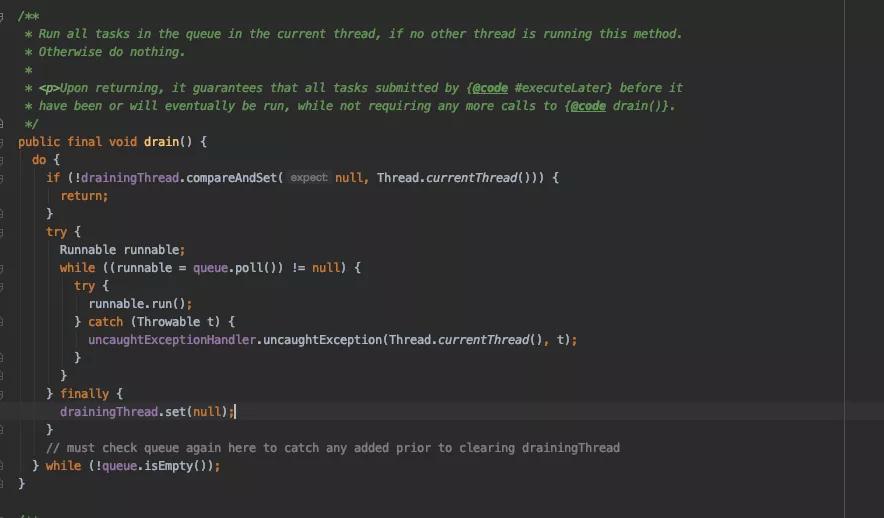
问题原因:再回到上面的线程栈,业务节点发现事件和gRPC底层通信共用了SynchronizationContext造成阻塞,和线程错乱执行。
问题解决:不再和gRPC共用SynchronizationContext,如果使用单独实例化一个即可。该问题通过测试同学通过故障注入的方式得以复现。




















