摘要:解决深度学习对数据的依赖问题和减少数据标注成本成为了业界的研究热点。本文将介绍以下几个研究方向:半监督/弱监督学习、数据合成、主动学习、自监督。
01.引言
得益于深度学习的发展,许多计算机视觉任务在近几年取得了不错的效果。但是,现有的深度学习算法多是有监督学习算法,依赖大量人工标记的训练数据,而标注数据十分耗费人力成本。因此,解决深度学习对数据的依赖问题和减少数据标注成本成为了业界的研究热点。本文选取了相关领域的部分论文,将介绍以下几个方向:半监督/弱监督学习;数据合成;主动学习;自监督。
02.半监督/弱监督学习
半监督学习是监督学习和无监督学习相结合的一种学习方法。半监督/弱监督学习使用大量的未标注数据/弱标注数据,同时使用小部分已标注数据,来训练机器学习模型。它预期的结果是通过对大部分未标注数据/弱标注数据的利用,得到的模型优于单纯只用已标注数据训练的模型。弱标注数据的数据标签信息量较少且标注难度小,比如在目标检测任务中,通常需要标注目标的类别和坐标,弱标注数据则只标注出图像中的目标类别,没有坐标信息。
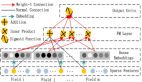
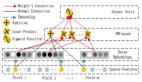
论文[1] 是半监督方向的图像分类论文,实验主要在手写体图像数据集上进行,包括MNIST、CIFAR等,图1是该论文方法的架构。如图所示,图中左上角和左下角分别是未标注数据集U和已标注L,中间的橘红色模块是论文的神经网络,右侧是数据的筛选模块。流程如下:先使用已标注数据集L训练得到初始模型M1,然后使用M1在未标注数据集U上进行推理,U中的每张图像都会得到一个分类结果和对应的置信度S。基于S对U中的样本进行筛选,将分类置信度较高的样本U1和对应的推理结果当作GT,加入已标注样本中L=L+U1,继续训练模型得到M2。之后重复上述流程,训练集数量不断增加,模型性能也逐渐变好。最终得到的模型M性能要远远优于只使用L训练得到的模型M1。
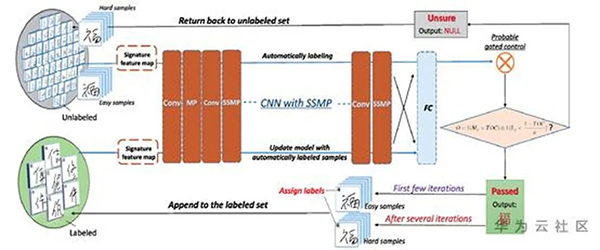
图1
论文[2]使半监督和弱监督学习在字符级别的文本检测领域的一篇论文,思想跟[1]类似,也是通过增量学习的方式来boost模型。如图2所示,使用预训练的字符集检测模型对左侧的未标注数据集U进行推理,得到检测结果D。图2中间上下模块分别表示半监督和弱监督筛选模块。半监督模块通过置信度阈值剔除掉D中检测不标准的检测框,弱监督模块带有“单词级”的标注框信息,所以将不在“单词级”标注框内的字符检测框剔除掉。之后用两个模块的输出结果重新训练模型。
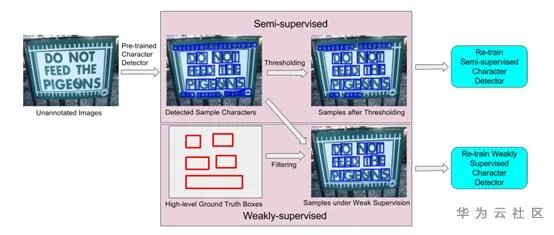
图2
论文[3]是使用检测框标注信息做分割任务的GAN(generative adversarial network)文章。如图[3]所示,左侧为带有检测框信息的图像,中间为生成器generator,右侧为鉴别器discriminator。图3中间的上支路在原始图像标注框外裁剪出背景区域,下支路从原始图像裁剪出标注框的目标区域,中间的生成器在原图标注框内生成mask,之后将mask和上下支路的两张图像结合成fake image,鉴别器需要鉴别图像是真实的还是合成的。通过生成对抗的方式,最后训练出一个良好的生成器分割网络,而全过程只使用了检测框标注信息监督,没有分割标注信息参与。
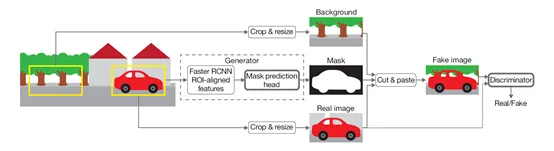
图3
03.数据合成
既然有监督学习无法避免模型对标注数据的依赖,那么自动生成数据也是减少人工成本的一个方式。数据合成的方式很多,包括人工设计规则,使用GAN网络生成等。论文[4]针对文本识别任务提出了基于人工设计规则的合成数据方法。合成的图像样本由前景图像层、背景图像层、边缘/阴影层组成,合成步骤分为六步:
font rendering:随机选择字体并将文本呈现入前景层;
border/shadow rendering:从前景层的文字中产生边缘阴影等;
base coloring:给三个图层填色;
projective distortion:对前景和阴影进行随机扭曲变换;
natural data blending:将图像跟真实场景图像进行混合;
noise:加入高斯噪声等。
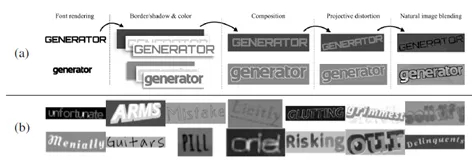
图4
利用GAN进行domain adaptation,合成数据也是一个研究方向。主要关注点包括source domain和target domain的appearance和geometry的相似程度。论文[5]则同时考虑两种相似来做生成对抗。
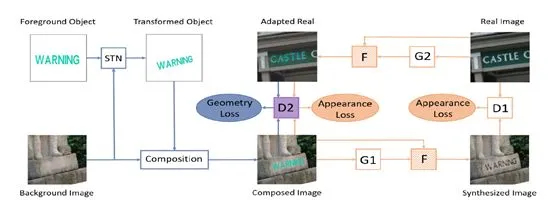
图5
04.主动学习
不同样本对现有模型的提升帮助是不同的,正如人类的学习过程一样,只学习小学知识的人很难突破初中知识的瓶颈。主动学习的出发点与此类似,就是希望从未标注数据集中挑选对模型提升帮助最大的子集交给人工标注。因此在标注同样数据量的样本的情况下(同样的标注成本),采用主动学习策略挑选样本训练的模型是接近最优的。主动学习的流程如图6所示,左侧的已标注数据集训练得到模型,模型在未标注数据集上推理,并将标注意义较大的样本推给人工标注,再将新标注的数据集重新训练和提升模型。
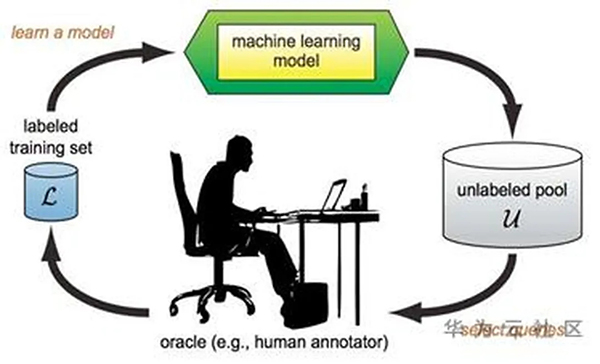
图6
主动学习领域定义未标注数据对模型提升帮助的指标包括不确定性、差异性和多样性等。不确定性指现有模型对该样本的推理置信度不够高,差异性指新样本跟已标注数据集的样本差异,多样性则是强调新样本内部足够多样化。在分类问题中,论文[6]是分类任务中的主动学习过程,根据模型对输入图像的生成patch预测的差异性和不确定度来衡量。论文[7]则强调检测任务中检测框的置信度只代表分类置信度,不具有位置置信度,因此提出位置置信度补充评价检测框的优劣:二阶段检测器中RPN和最终输出框的差异(图7),数据扩充后的检测框与原图检测框的差异。
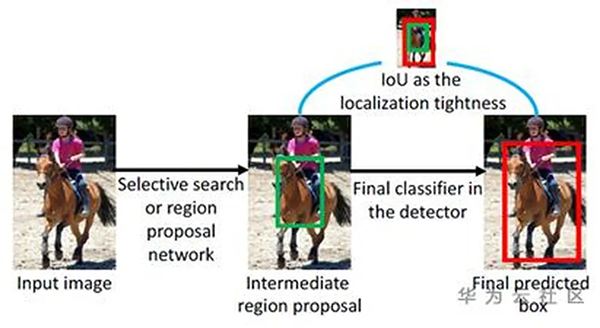
图7
论文[8]则指出现有主动学习模型大多是task-specific,因此提出了task-agnostic的挑选样本策略,并在分类、检测等任务中验证了实验。如图8所示,论文提出了可旁加在主干任务学习网络的loss预测分支,对未标注数据集进行loss预测,预测loss大的样本表面模型对它的不确定性高。Loss预测分支在训练阶段时的监督信息是主干任务学习网络的loss。
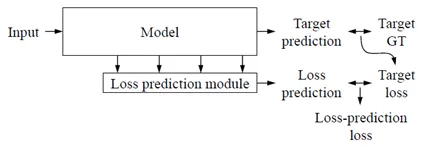
图8
05.自监督
自监督学习是无监督学习的一种,近期是学术界的研究热点。它通过利用无标签的数据本身的结构或者特性,人为构造标签出来监督网络学习。通常自监督学习的模型并不直接应用在目标任务上,而是作为下游任务的预训练模型。论文[9]是自监督学习的一个新进展,使用该论文方法得到的无监督模型,作为预训练模型在许多下游任务fine-tune后的效果优于使用有监督学习的预训练模型fine-tune的。图9(c)是MoCo的算法图,(a)(b)表示之前的相关方法。
Contrastive learning是MoCo的出发点,即对输入样本做数据扩充得到扩充集,之后在图中左侧encoder输入,右侧encoder输入或中的样本,其中是不同于的其他样本,通过contrastive loss优化网络对相同样本源的输入编码出相似特征,对不同样本源的输入编码出差异特征。在该过程中,有两个关键点:计算量不能太大,否则计算资源不允许;右侧的encoder提取的特征k应尽可能是由最新的encoder得到的。图9(a)分别是使用mini-batch中的一个样本作为,剩余样本作为,好处是每个mini-batch中的k都是最新的,坏处是k的数量太少,受mini-batch限制。图9(b)则是对所有样本进行编码存入memory bank中,并定期更新,好处是k的数量可以不受限制,坏处是的特征不一定是最新的。MoCo则使用了队列存储的特征,将最新的样本特征送入队列,队尾的特征剔除,队列大小可控,且k基本是最近时期的encoder提取的。
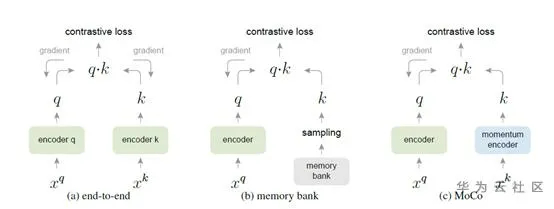
图9
06.总结
减少数据标注成本已经成为深度学习领域一个不可回避的研究课题,一方面,合成数据,让机器自动标注数据是值得深挖的方向,另一方面,减少神经网络的数据依赖或者能模型认识数据本身的内在结构也尤为重要。更有业界权威人士认为,数据提炼或是人工智能的下一个突破口。