












2021年11月5日arXiv上载论文“Towards Learning Generalizable Driving Policies from Restricted Latent Representations“,作者来自Florida的UCF和加州UCSB。

目标是寻求可推广到新和未知环境的决策方案和驾驶策略。这项工作用了一个思想,即人类驾驶员学习周围环境的抽象表征,因为其在各种驾驶场景和环境中非常相似。通过这些表征,人类驾驶员能够快速适应新环境并在未见过的场景条件下驾驶。通过施加信息瓶颈,其提取一个潜表示,通过最小化驾驶场景之间的距离,一种衡量不同驾驶配置之间相似性的量化。然后,该潜空间用作 Q-learning 模块的输入,学习可推广的驾驶策略。
将驾驶场景转换为与场景无关的潜空间表征可以实现自动驾驶智体的多任务学习,因为只接收对驾驶任务必不可少的信息,不知道其特定的驾驶场景。
这项工作探索把学习的潜空间作为训练强化学习 (RL) 智体状态表征的可能性,所提出的解决方案显示所得策略泛化性的改进。
随机环境中智体的决策过程可以正式描述为 马尔可夫决策过程(MDP) 。如果 MDP 完全已知,则价值和策略迭代等动态规划算法可递归求解最优状态-动作价值函数 Q*。
然而,在现实世界的问题,环境的动态和奖励函数通常未知,智体只能访问与底层状态相关的局部观测,即 部分可观测马尔可夫决策过程 (POMDP) 。
强化学习 (RL) 提供了一种可能性,通过与环境的持续交互来解决具有未知奖励和状态转换函数的 POMDP。在数学上,诸如 时域差 (TD) 学习之类的 RL 算法使智体从环境之间交互中更新价值函数,无需明确已知的完整MDP。
对状态-动作价值函数近似,比如深度神经网络( 深度Q-网络,DQN ),这样有可能做到:学习更加泛化的策略,规模化一个较大型状态-空间。
DQN 建立在两个思想之上,即:经验回放缓存生成训练样本,在训练期间用两个独立的网络。关键思想是每次训练的迭代更新贪婪网络,计算最佳 Q 值,并用另一个更新频率较低的目标网络来稳定训练过程。
本文串行地训练两个Autoencoder,训练第二个Autoencoder来学习第一个Autoencoder的隐表征,而第二个Autoencoder本质上是学习第一个Autoencoder权重的概率分布。
作者引入一个相似性度量来衡量不同场景之间的距离,并寻找一个潜空间最大化不同驾驶场景之间的相似性。然后用这个潜空间来表示自车对环境的观察。
作者旨在用这种潜表征为强化学习模块提供输入巩固规划和预测,最终学习驾驶策略。特别是选择了一组 5 种不同的道路拓扑,即环岛、交叉路口、高速公路合并、高速公路出口和高速公路巡航。根据车辆速度和位置,进一步随机化每个场景,以衡量方法的泛化能力。
如图为例,遵循MDP定义,所有车辆在时间 t 采取行动,使环境状态从初始状态演变为目标状态。 尽管这种转变具有随机性,但潜概率分布定义了其动态性,包括人类和智体的行为。 这个概率分布 Pr取决于所有车辆的动作以及世界本身的动态。
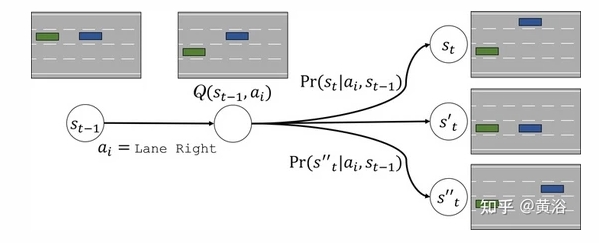
首先,最有效和最有用的状态表征不是靠手工设计,而是从数据中学习。 其次,假设在自动驾驶汽车中,整合用于决策的规划-预测模块可以提高处理新和未见过的拓扑结构和配置的泛化能力。
如图所示:整个架构包括,一个瓶颈编码器-解码器结构,以及一个 3 维卷积神经网络 (CNN),该网络作函数逼近器来估计Q函数;该系统输入是一个含噪的时空状态表示,输出是给定状态下动作的概率分布。
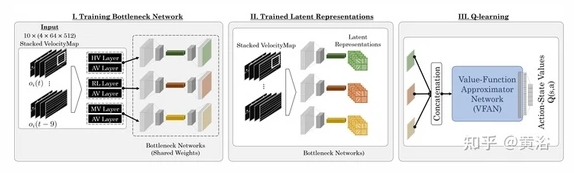
注: HV-人类驾驶车 , AV-自动驾驶车 , MV-任务车/自车 , RL-道路布局 。
定义了一个离散动作空间 A,其中第 i 个智体动作可以是 ai ∈ Ai = [Left, Idle, Right, Accelerate, Decelerate] 。 这些离散动作呈现为平滑且合理的轨迹,并利用 PID 控制器生成低级转向和油门信号,使汽车能够遵循所需的轨迹。
其中 瓶颈网络 (BNN) 确保最关键的信息通过数据管道,最大化不同驾驶场景之间的相似性。 学习的潜表征通过 Q-learning 学习驾驶策略。引入一种直观而丰富的状态表示,带有关场景的时空信息,并且受到传感器噪声的污染。如图所示:
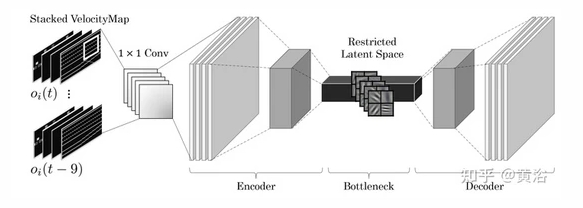
上面图中Stacked Multi-channel VelocityMap 显示了自动驾驶车辆(AV)和人类驾驶车辆(HV)的位置,相对 Frenet 的纵向速度嵌入在像素值中。 为了更好地控制 VelocityMaps 中像素值的动态范围,我们采用了裁剪对数函数,与线性映射相比,该函数实现增强的性能。
VelocityMaps 中的其他通道嵌入了 道路布局(RL) 以及 自车(MV ) 的位置和绝对速度。
从自动编码器瓶颈结构开始,通过混合的恶批处理观测值训练一个3D 卷积架构。在典型的深度强化学习架构中添加一个中间模块,消除对驾驶场景的依赖,通过专用的泛化潜表征进行泛化。 为此,依赖于从特征提取到价值函数近似的流水线的信息瓶颈,提出一种方法,即 3D Convolutional Value Function Approximator Net- work (VFAN) ,如图所示:

在数据流施加这样的瓶颈,训练编码器-解码器,激励网络只传递最重要信息到价值函数网络,其解释驾驶场景、对车辆定位、协调智体之间的交互。
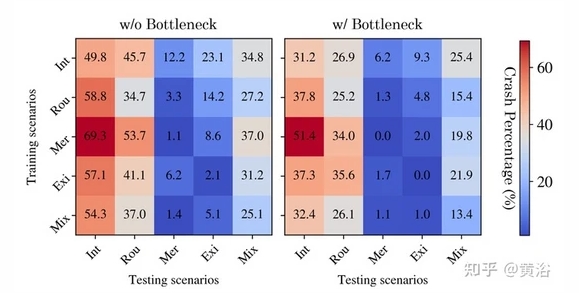
如图显示的是,自动编码器在环岛路口、交叉路口、高速公路出口和高速公路合并等驾驶实例的混合数据集训练了 100 个epoch。 在 epoch 50 之后,损失的变化在视觉上并不明显。

如图所示是潜表征的例子:两个对比鲜明的环岛路口和交叉路口的拓扑结构。

为模拟和生成用于训练自动编码器以及 Q -学习过程的训练数据集,采用基于OpenAI Gym 环境的抽象 2D 驾驶模拟器。 模拟器对给定的道路拓扑和车辆设置生成不同的驾驶场景。 由于目标是学习可泛化的策略,而不是通过 VFAN 记住一系列动作,因此每个模拟事件的初始状态都是随机的。 车辆的初始 Frenet 纬度(latitude)来自均匀随机化的均匀分布,模拟车辆的初始 Frenet 经度(longitude)和 Frenet 纵向速度来自裁剪高斯分布。
采用闭环 PID 控制器,每辆车的元动作渲染为低级转向和加速信号。 然后,运动学自行车模型根据转向角和其他参数确定车辆的偏航率。
模拟包括自动驾驶车和人工驾驶车,创建逼真的混合自动驾驶场景。 采用两种广泛使用的人类驾驶员模型,HV的横向动作及其换道的决定,遵循 最小化换道引起的整体制动 (Minimizing Overall Braking Induced by Lane changes,MOBIL) 策略。 MOBIL 模型仅在后面跟车产生的加速度满足安全标准时才允许换道。 HV 的纵向加速度遵循 智能驾驶员模型 (Intelligent Driver Model,IDM) 。
实验结果如下为例:

瓶颈网络的性能提升作用
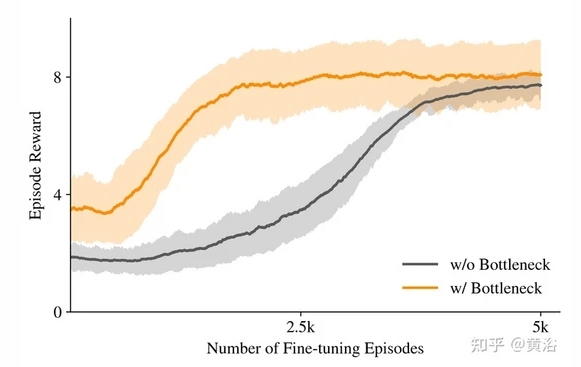
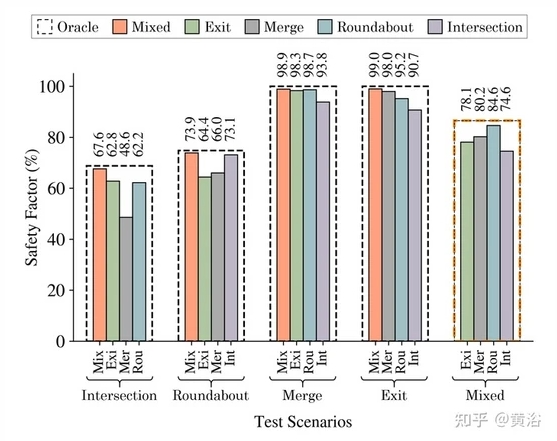
加速迁移学习

不同潜空间大小的瓶颈网络,不同的重建特性
不同迁移学习方法比较
域适应
这项工作采用驾驶模拟器从各种道路拓扑(例如环岛路口、十字路口和高速公路)生成一个大型混合驾驶事件数据集。 但是,可以对较长时间的驾驶进行更复杂的研究。 此外,必须做更多的工作来解释学习的潜表征。


























