假设我们现在做一个简单的文件缓存服务,由于文件数过多,我们先使用3台机器用来存储文件。
为了由文件名(假设文件名称不重复)能得到存储的机器,考虑先对文件名做hash运算,接着对3取余,得到的余数即为所在机器的编号。
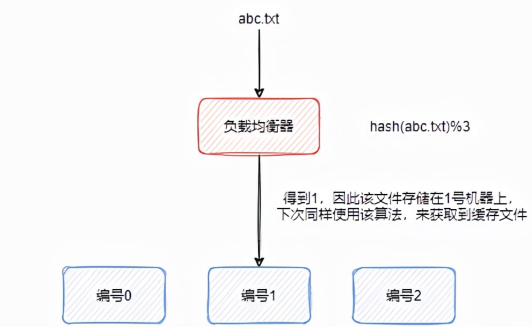
这套系统运行了很久,后来文件数量慢慢增多,3台机器存不下了,现在我们考虑扩充到4台。
这个时候,我们的算法更新为hash(文件名)%5。
那么使用该算法获取abc.txt文件所在的缓存机器时,在其hash值为10的时候,将会映射到0号机器上,而之前是存储在1号机器上的,这个时候就会重新将文件存储到0号机器上,或者将1号机器上的文件迁移到0号机器上。
因此,增加了两台机器后,导致了缓存失效。
我们使用代码来大致确定一下缓存失效的比例:
- public static void main(String[] args) {
- //缓存失效计数
- int count = 0;
- //假设一共有10000份文件
- for (int i = 0; i < 10000; i++) {
- //文件名称
- String fileName = "file#" + i;
- int hashCode = fileName.hashCode();
- //原来的存储位置
- int oldSite = hashCode % 3;
- //增加两台机器后,现在的存储位置
- int newSite = hashCode % 5;
- if (oldSite != newSite) {
- count++;
- }
- }
- System.out.println(count);
- }
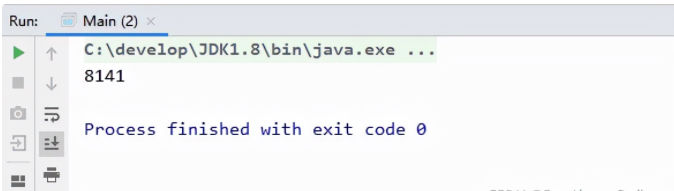
运行后发现,超过80%的缓存都会失效。
也就是说,无论是增加机器还是减少机器,都会使得缓存大面积的失效,这是我们不愿意见到的结果,那么有没有一种新的算法呢?
一致性哈希算法,就应运而生了。该算法可以使得增减机器时,大幅度减少失效的缓存数量。
首先这里有个圆,你可以看做是从0到2^32-1头尾相连的环。
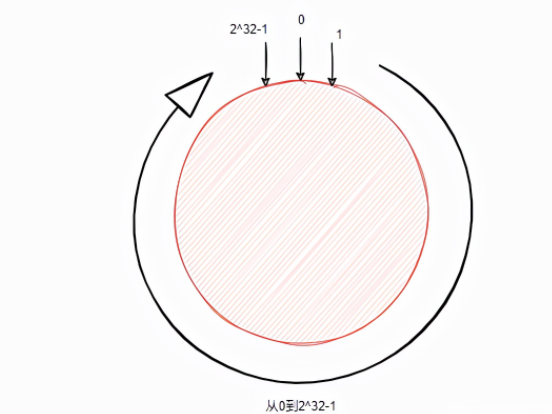
我们先对一台机器的ip做哈希运算,再对2^32取模,即hash(ip)%2^32,得到了数字肯定在环上。
假设我们使用的哈希算法得到的哈希值返回值是int类型,则本身相当于已经取过模。
因此我们标记出三台机器在环上的位置

这个时候,需要将文件映射到环上,使用一样的哈希函数,即hash(文件名)。假设这里有4个文件,我们在环上标记出文件的位置。
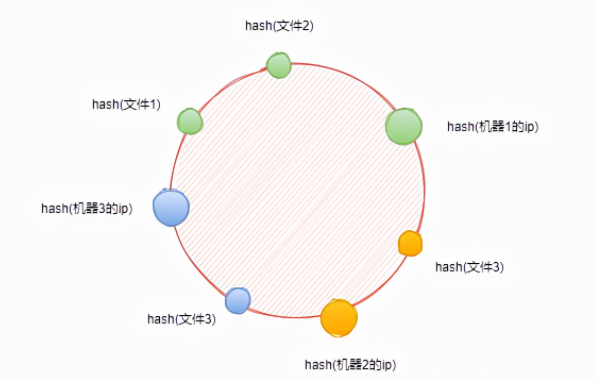
那现在怎么确定文件在哪台机器上存储呢?
很简单,从当前文件开始,顺时针找到第一个机器,即为文件的存储位置。

假设这个时候机器2宕机,我们将机器2从环上移除,观察一下文件3的变化
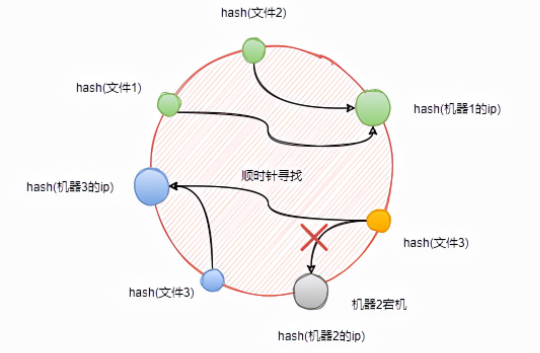
当机器2宕机时,文件3将重新指向机器3。
也就是说,当机器2宕机时,原本映射到机器1与机器2之间位置的文件,将会被重新映射到机器3。
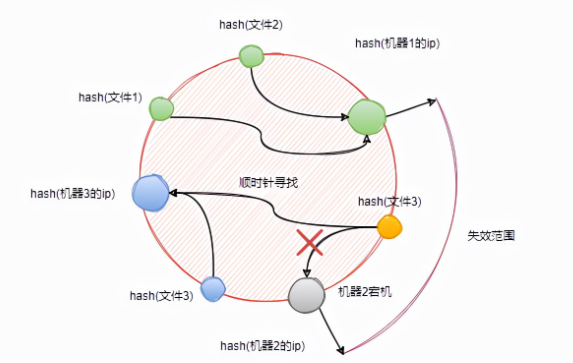
因此,一致性哈希能够大幅度降低缓存失败的范围,不至于“牵一发而动全身”。
不知道大家有没有看出来,在上图中,几台机器在环上的分布比较均匀,这是一种非常理想的情况。
然而现实可能并不是这样,假设3台机器经过映射后,彼此之间非常靠近。
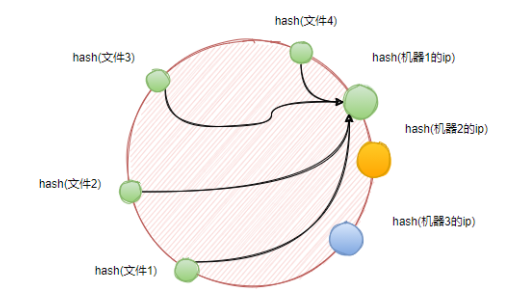
当机器数量特别少的时候,经过映射后,节点在环上分布不均匀,导致大部分文件全部落在同一台机器上,也就是存在数据倾斜问题。
如图所示,4个文件全部存储在了机器1上。倘若有一天,机器1承载不住大量的文件访问挂了,这些文件将会立即转移到机器2上。机器2同样也会承载不住,最后就会造成整个系统的连锁崩溃。
既然问题的根本在于机器数量少,那我们可以增加机器啊!
但机器是一种实际存在的物理资源,不可能说增加就增加,老板也不让啊!
这个时候,我们可以复制现有的物理机器,形成一些虚拟节点,通过以物理节点的ip加上后缀序号来实现。
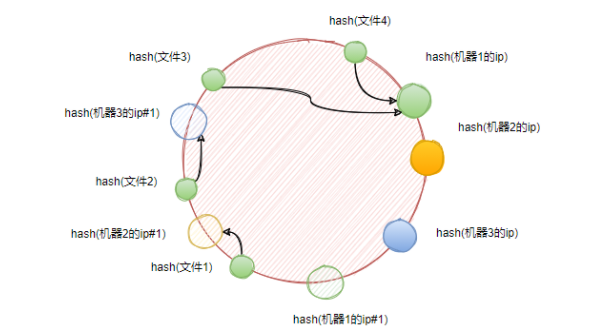
当虚拟节点以同样的算法映射到环上之后,文件1最终将会落到机器2上。
理论上,虚拟节点越多,越能做到相对的均匀分布。
下面以代码的形式,来验证一下。
- public class Main {
- //真实节点
- private static final String[] ipArray = new String[]{"192.168.1.1", "192.168.1.2", "192.168.1.3", "192.168.1.4"};
- //哈希环(哈希值->真实节点ip)
- private static final TreeMap<Long, String> circle = new TreeMap<>();
- //指定倍数初始化哈希环
- private static void initCircle(int mul) {
- //映射真实节点
- for (String ip : ipArray) {
- circle.put(hash(ip), ip);
- //按照倍数映射虚拟节点
- for (int i = 1; i <= mul; i++) {
- String virtual = ip + "#" + i;
- circle.put(hash(virtual), ip);
- }
- }
- }
- //获取指定文件存储的机器ip
- private static String getIpByFileName(String fileName) {
- long hash = hash(fileName);
- Long higherKey = circle.higherKey(hash);
- if (higherKey == null) {
- //返回哈希环中的第一个ip
- return circle.get(circle.firstKey());
- }
- //返回比文件名称的哈希值大的最小ip
- return circle.get(higherKey);
- }
- //统计落在每个节点上的文件总数(ip->文件总数)
- private static Map<String, Long> count(long fileCount) {
- //(ip,文件总数)
- Map<String, Long> map = new HashMap<>();
- for (long i = 1; i <= fileCount; i++) {
- String ip = getIpByFileName("file#" + i);
- Long ipCount = map.get(ip);
- map.put(ip, (ipCount == null ? 0 : ipCount) + 1);
- }
- return map;
- }
- //打印各个ip存储的文件数占总数的百分比
- private static void print(int fileCount) {
- Map<String, Long> map = count(fileCount);
- for (String ip : ipArray) {
- Long ipCountL = map.get(ip);
- long ipCount = ipCountL == null ? 0 : ipCountL;
- double result = ipCount * 100 / (double) fileCount;
- //保留一位小数
- String format = String.format("%.1f", result);
- System.out.println(ip + ":" + format + "%");
- }
- }
- // 32位的 Fowler-Noll-Vo 哈希算法
- // https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function
- private static Long hash(String key) {
- final int p = 16777619;
- long hash = 2166136261L;
- for (int idx = 0, num = key.length(); idx < num; ++idx) {
- hash = (hash ^ key.charAt(idx)) * p;
- }
- hash += hash << 13;
- hash ^= hash >> 7;
- hash += hash << 3;
- hash ^= hash >> 17;
- hash += hash << 5;
- if (hash < 0) {
- hash = Math.abs(hash);
- }
- return hash;
- }
- public static void main(String[] args) {
- //初始化哈希环
- initCircle(1000000);
- //文件总数10000个
- print(10000);
- }
- }
当倍数为0时:
- 192.168.1.1:0.0%
- 192.168.1.2:0.0%
- 192.168.1.3:100.0%
- 192.168.1.4:0.0%
相当于没有虚拟节点,可以看到极度不均匀,倾斜严重。
当倍数为100时:
- 192.168.1.1:28.4%
- 192.168.1.2:22.4%
- 192.168.1.3:34.6%
- 192.168.1.4:14.6%
倾斜改善了!但仍然不满足
当倍数为10000时:
- 192.168.1.1:24.6%
- 192.168.1.2:25.9%
- 192.168.1.3:23.3%
- 192.168.1.4:26.3%
基本上算是比较均匀了
大胆点,我们把倍数调到1百万,文件数也调到1百万
- 192.168.1.1:25.0%
- 192.168.1.2:24.9%
- 192.168.1.3:25.0%
- 192.168.1.4:25.1%
可见所有ip下存储的文件总数非常均匀!