当前,强化学习(包括深度强化学习DRL和多智能体强化学习MARL)在游戏、机器⼈等领域有⾮常出⾊的表现,但尽管如此,在达到相同⽔平的情况下,强化学习所需的样本量(交互次数)还是远远超过⼈类的。这种对⼤量交互样本的需求,严重阻碍了强化学习在现实场景下的应⽤。为了提升对样本的利⽤效率,智能体需要⾼效率地探索未知的环境,然后收集⼀些有利于智能体达到最优策略的交互数据,以便促进智能体的学习。近年来,研究⼈员从不同的⻆度研究RL中的探索策略,取得了许多进展,但尚⽆⼀个全⾯的,对RL中的探索策略进⾏深度分析的综述。
 最新综述,近200篇文献揭示挑战和未来方向">
最新综述,近200篇文献揭示挑战和未来方向">论文地址:https://arxiv.org/pdf/2109.06668.pdf
本⽂介绍深度强化学习领域第⼀篇系统性的综述⽂章Exploration in Deep Reinforcement Learning: A Comprehensive Survey。该综述⼀共调研了将近200篇⽂献,涵盖了深度强化学习和多智能体深度强化学习两⼤领域近100种探索算法。总的来说,该综述的贡献主要可以总结为以下四⽅⾯:
- 三类探索算法。该综述⾸次提出基于⽅法性质的分类⽅法,根据⽅法性质把探索算法主要分为基于不确定性的探索、基于内在激励的探索和其他三⼤类,并从单智能体深度强化学习和多智能体深度强化学习两⽅⾯系统性地梳理了探索策略。
- 四⼤挑战。除了对探索算法的总结,综述的另⼀⼤特点是对探索挑战的分析。综述中⾸先分析了探索过程中主要的挑战,同时,针对各类⽅法,综述中也详细分析了其解决各类挑战的能⼒。
- 三个典型benchmark。该综述在三个典型的探索benchmark中提供了具有代表性的DRL探索⽅法的全⾯统⼀的性能⽐较。
- 五点开放问题。该综述分析了现在尚存的亟需解决和进⼀步提升的挑战,揭⽰了强化学习探索领域的未来研究⽅向。
接下来,本⽂从综述的四⼤贡献⽅⾯展开介绍。
三类探索算法
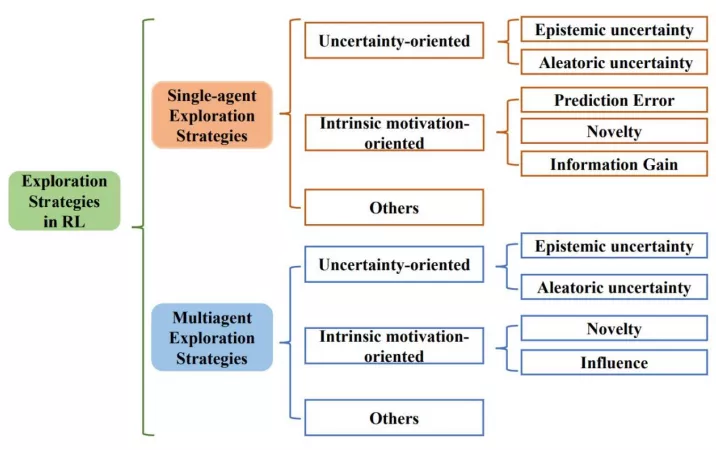 最新综述,近200篇文献揭示挑战和未来方向">
最新综述,近200篇文献揭示挑战和未来方向">上图展⽰了综述所遵循的分类⽅法。综述从单智能体深度强化学习算法中的探索策略、多智能体深度强化学习算法中的探索策略两⼤⽅向系统性地梳理了相关⼯作,并分别分成三个⼦类:⾯向不确定性的(Uncertainty-oriented)探索策略、⾯向内在激励的(Intrinsic motivation oriented)探索策略、以及其他策略。
1、⾯向不确定性的探索策略
通常遵循“乐观对待不确定性”的指导原则(OFU Principle)「1」。这类做法认为智能体对某区域更⾼的不确定性(Uncertainty)往往是因为对该区域不充分的探索导致的,因此乐观地对待不确定性,也即引导智能体去探索不确定性⾼的地⽅,可以实现⾼效探索的⽬的。
强化学习中⼀般考虑两类不确定性,其中引导往认知不确定性⾼的区域探索可以促进智能体的学习,但访问环境不确定性⾼的区域不但不会促进智能体学习过程,反⽽由于环境不确定性的⼲扰会影响到正常学习过程。因此,更合理的做法是在乐观对待认知不确定性引导探索的同时,尽可能地避免访问环境不确定性更⾼的区域。基于此,根据是否在探索中考虑了环境不确定性,综述中将这类基于不确定性的探索策略分为两个⼩类。
第⼀类只考虑在认知不确定性的引导下乐观探索,典型⼯作有RLSVI「2」、Bootstrapped DQN「3」、OAC「4」、OB2I「5」等;第⼆类在乐观探索的同时考虑避免环境不确定性的影响,典型⼯作有IDS「6」、DLTV「7」等。
2、⾯向内在激励信号的探索策略
⼈类通常会通过不同⽅式的⾃我激励,积极主动地与世界交互并获得成就感。受此启发,内在激励信号导向的探索⽅法通常通过设计内在奖励来创造智能体的成就感。从设计内在激励信号所使⽤的技术,单智能体⽅法中⾯向内在激励信号的探索策略可分为三类,也即估计环境动⼒学预测误差的⽅法、状态新颖性估计⽅法和基于信息增益的⽅法。⽽在多智能体问题中,⽬前的探索策略主要通过状态新颖性和社会影响两个⻆度考虑设计内在激励信号。
估计环境动⼒学预测误差的⽅法主要是基于预测误差,⿎励智能体探索具有更⾼预测误差的状态,典型⼯作有ICM「8」、EMI「9」等。
状态新颖性⽅法不局限于预测误差,⽽是直接通过衡量状态的新颖性(Novelty),将其作为内在激励信号引导智能体探索更新颖的状态,典型⼯作有RND「10」、Novelty Search「11」、LIIR「12」等。
基于信息增益的⽅法则将信息获取作为内在奖励,旨在引导智能体探索未知领域,同时防⽌智能体过于关注随机领域,典型⼯作有VIME「13」等。
而在多智能体强化学习中,有⼀类特别的探索策略通过衡量“社会影响”,也即衡量智能体对其他智能体的影响作⽤,指导作为内在激励信号,典型⼯作有EITI和 EDTI「14」等。
3、其他
除了上述两⼤类主流的探索算法,综述⾥还调研了其他⼀些分⽀的⽅法,从其他⻆度进⾏有效的探索。这些⽅法为如何在DRL中实现通⽤和有效的探索提供了不同的见解。
这主要包括以下三类,⼀是基于分布式的探索算法,也即使⽤具有不同探索行为的异构actor,以不同的⽅式探索环境,典型⼯作包括Ape-x「15」、R2D2「16」等。⼆是基于参数空间噪声的探索,不同于对策略输出增加噪声,采⽤噪声对策略参数进⾏扰动,可以使得探索更加多样化,同时保持⼀致性,典型⼯作包括NoisyNet「17」等。除了以上两类,综述还介绍了其他⼏种不同思路的探索⽅法,包括Go-Explore「18」,MAVEN「19」等。
四大挑战
综述重点总结了⾼效的探索策略主要⾯临的四⼤挑战。
- ⼤规模状态动作空间。状态动作空间的增加意味着智能体需要探索的空间变⼤,就⽆疑导致了探索难度的增加。
- 稀疏、延迟奖励信号。稀疏、延迟的奖励信号会使得智能体的学习⾮常困难,⽽探索机制合理与否直接影响了学习效率。
- 观测中的⽩噪声。现实世界的环境通常具有很⾼的随机性,即状态或动作空间中通常会出现不可预测的内容,在探索过程中避免⽩噪声的影响也是提升效率的重要因素。
- 多智能体探索挑战。多智能体任务下,除了上述挑战,指数级增长的状态动作空间、智能体间协同探索、局部探索和全局探索的权衡都是影响多智能体探索效率的重要因素。
综述中总结了这些挑战产⽣的原因,及可能的解决⽅法,同时在详细介绍⽅法的部分,针对现有⽅法对这些挑战的应对能⼒进⾏了详细的分析。如下图就分析了单智能体强化学习中基于不确定性的探索⽅法解决这些挑战的能⼒。
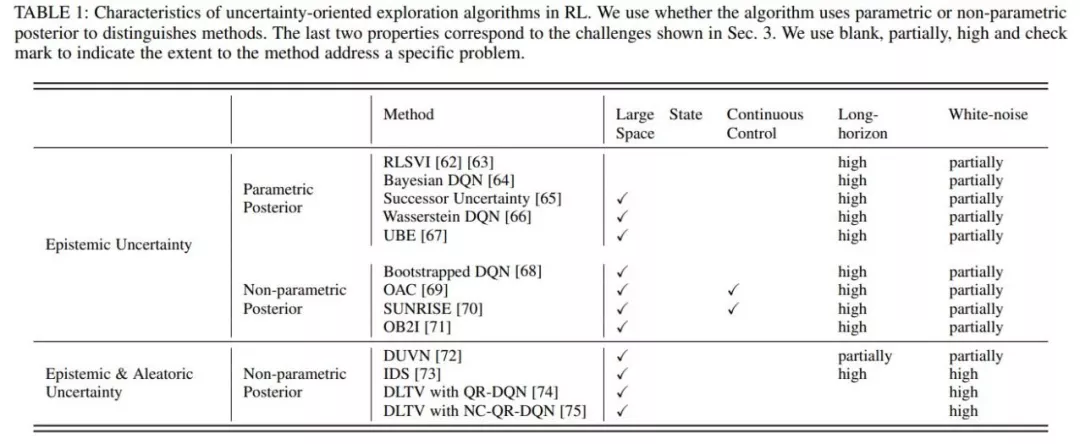 最新综述,近200篇文献揭示挑战和未来方向">
最新综述,近200篇文献揭示挑战和未来方向">三个经典的benchmark
为了对不同的探索⽅法进⾏统⼀的实验评价,综述总结了上述⼏种有代表性的⽅法在三个代表性 benchmark上的实验结果: 《蒙特祖玛的复仇》,雅达利和Vizdoom。
蒙特祖玛的复仇由于其稀疏、延迟的奖励成为⼀个较难解决的任务,需要RL智能体具有较强的探索能⼒才能获得正反馈;⽽穿越多个房间并获得⾼分则进⼀步需要⼈类⽔平的记忆和对环境中事件的控制。
整个雅达利系列侧重于对提⾼RL 智能体学习性能的探索⽅法进⾏更全⾯的评估。
Vizdoom是另⼀个具有多种奖励配置(从密集到⾮常稀疏)的代表性任务。与前两个任务不同的是,Vizdoom是⼀款带有第⼀⼈称视⻆的导航(和射击)游戏。这模拟了⼀个具有严重的局部可观测性和潜在空间结构的学习环境,更类似于⼈类⾯对的现实世界的学习环境。
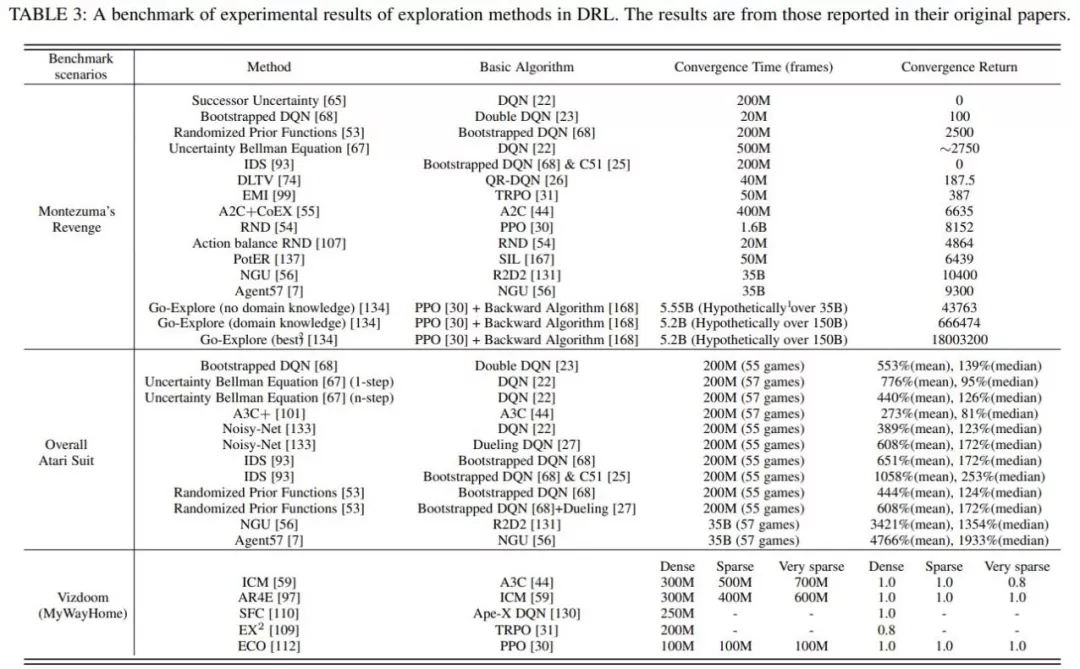 最新综述,近200篇文献揭示挑战和未来方向">
最新综述,近200篇文献揭示挑战和未来方向">基于上表所⽰的统⼀的实验结果,结合所提出的探索中的主要挑战,综述中详细分析了各类探索策略在这些任务上的优劣。
关于探索策略的开放问题和未来方向
尽管探索策略的研究取得了⾮常前沿的进展,但是仍然存在⼀些问题没有被完全解决。综述主要从以下五个⻆度讨论了尚未解决的问题。
- 在⼤规模动作空间的探索。在⼤规模动作空间上,融合表征学习、动作语义等⽅法,降低探索算法的计算复杂度仍然是⼀个急需解决的问题。
- 在复杂任务(时间步较长、极度稀疏、延迟的奖励设置)上的探索,虽然取得了一定的进展,⽐如蒙特祖玛的复仇,但这些解决办法代价通常较⼤,甚⾄要借助⼤量⼈类先验知识。这其中还存在较多普遍性的问题值得探索。
- ⽩噪声问题。现有的⼀些解决⽅案都需要额外估计动态模型或状态表征,这⽆疑增加了计算消耗。除此之外,针对⽩噪声问题,利⽤对抗训练等⽅式增加探索的鲁棒性也是值得研究的问题。
- 收敛性。在⾯向不确定性的探索中,线性MDP下认知不确定性是可以收敛到0的,但在深度神经⽹络下维度爆炸使得收敛困难。对于⾯向内在激励的探索,内在激励往往是启发式设计的,缺乏理论上合理性论证。
- 多智能体探索。多智能体探索的研究还处于起步阶段,尚未很好地解决上述问题,如局部观测、不稳定、协同探索等。
主要作者介绍
杨天培博⼠,现任University of Alberta博⼠后研究员。杨博⼠在2021年从天津⼤学取得博⼠学位,她的研究兴趣主要包括迁移强化学习和多智能体强化学习。杨博⼠致⼒于利⽤迁移学习、层次强化学习、对⼿建模等技术提升强化学习和多智能体强化学习的学习效率和性能。⽬前已在IJCAI、AAAI、ICLR、NeurIPS等顶级会议发表论⽂⼗余篇,担任多个会议期刊的审稿⼈。
汤宏垚博⼠,天津⼤学博⼠在读。汤博⼠的研究兴趣主要包括强化学习、表征学习,其学术成果发表在AAAI、IJCAI、NeurIPS、ICML等顶级会议期刊上。
⽩⾠甲博⼠,哈尔滨⼯业⼤学博⼠在读,研究兴趣包括探索与利⽤、离线强化学习,学术成果发表在ICML、NeurIPS等。
刘⾦毅,天津⼤学智能与计算学部硕⼠在读,研究兴趣主要包括强化学习、离线强化学习等。
郝建业博⼠,天津⼤学智能与计算学部副教授。主要研究⽅向为深度强化学习、多智能体系统。发表⼈⼯智能领域国际会议和期刊论⽂100余篇,专著2部。主持参与国家基⾦委、科技部、天津市⼈⼯智能重⼤等科研项⽬10余项,研究成果荣获ASE2019、DAI2019、CoRL2020最佳论⽂奖等,同时在游戏AI、⼴告及推荐、⾃动驾驶、⽹络优化等领域落地应⽤。