













本文转自雷锋网,如需转载请至雷锋网官网申请授权。
2021年9月,美国网络安全和新兴技术局(Center for Security and Emerging Technology,简称CSET)发布了研究报告《小数据人工智能的巨大潜力》(Small Data’s Big AI Potential )。报告指明一点:长期被忽略的小数据(Small Data)人工智能潜力不可估量!

小数据方法是一种只需少量数据集就能进行训练的人工智能方法。它适用于数据量少或没有标记数据可用的情况,减少对人们收集大量现实数据集的依赖。
这里所说的“小数据”并不是明确类别,没有正式和一致认可的定义。学术文章讨论小数据与应用领域相关性时,常与样本大小相挂钩,例如千字节或兆字节与 TB 数据。对许多数据的引用最终走向都是作为通用资源。然而,数据是不可替代的,不同领域的人工智能系统需要不同类型的数据和方法,具体取决待解决的问题。
本文主要从决策者的角度讲述“小数据”。政府人员通常被看作是人工智能领域潜在的强力参与者,因为他们对社会运行规则更为了解并可以访问大量数据——例如气候监测数据、地质调查、边境控制、社会保障、 选民登记、车辆和司机记录等。人口众多、数据收集能力强被认为是国家人工智能竞争能力的重要因素。
一些美国人认为,政府只有可以数字化、清理和标记大量数据,才能从人工智能的革命中受益。虽有些道理,但将AI的进展都归功于这些条件是偏颇的。因为人工智能的未来不仅只与大数据有关联,即使政府部门没有对大数据基础设施多加投资,人工智能的创新依旧可以诞生。
二、”小数据“方法的分类
“小数据”方法大致可分为五种:a) 迁移学习,b) 数据标记,c) 人工数据生成,d) 贝叶斯方法,以及 e) 强化学习。
迁移学习(Transfer learning )的工作原理是先在数据丰富的环境中执行任务,然后将学到的知识“迁移”到可用数据匮乏的任务中。
比如,开发人员想做一款用于识别稀有鸟类物种应用程序,但每种鸟可能只有几张标有物种的照片。运用迁移学习,他们先用更大、更通用的图像数据库(例如ImageNet)训练基本图像分类器,该数据库具有数千个类别标记过的数百万张图像。当分类器能区分狗与猫、花与水果、麻雀与燕子后,他们就可以将更小的稀有鸟类数据集“喂养”给它。然后,该模型可以“转移”图像分类的知识,利用这些知识从更少的数据中学习新任务(识别稀有鸟类)。
数据标记(Data labeling)适用于有限标记数据和大量未标记数据的情况。使用自动生成标签(自动标记)或识别标签特别用途的数据点(主动学习)来处理未标记的数据。
例如,主动学习(active learning)已被用于皮肤癌诊断的研究。图像分类模型最初在100张照片上训练,根据它们的描述判定是癌症皮肤还是健康皮肤从,而进行标记。然后该模型会访问更大的潜在训练图像集,从中可以选择 100 张额外的照片标记并添加到它的训练数据中。
人工数据生成(Artificial data generation)是通过创建新的数据点或其他相关技术,最大限度地从少量数据中提取更多信息。
一个简单的例子,计算机视觉研究人员已经能用计算机辅助设计软件 (CAD) ——从造船到广告等行业广泛使用的工具——生成日常事物的拟真 3D 图像,然后用图像来增强现有的图像数据集。当感兴趣的数据存在单独信息源时,如本例中是众包CAD模型时,这样的方法可行性更高。
生成额外数据的能力不仅在处理小数据集时有用。任何独立数据的细节都可能是敏感的(比如个人的健康记录),但研究人员只对数据的整体分布感兴趣,这时人工合成数据的优势就显现出来了,它可对数据进行随机变化从而抹去私人痕迹,更好地保护了个人隐私。
贝叶斯方法(Bayesian methods)是通过统计学和机器学习,将有关问题的架构信息(“先验”信息)纳入解决问题的方法中,它与大多数机器学习方法产生了鲜明对比,倾向于对问题做出最小假设,更适用于数据有限的情况,但可以通过有效的数学形式写出关于问题的信息。贝叶斯方法则侧重对其预测的不确定性产生良好的校准估计。
作为贝叶斯推断运用小数据的一个例子:贝叶斯方法被用于监测全球地震活动,对检测地壳运动和核条约有着重大意义。通过开发结合地震学的先验知识模型,研究人员可以充分利用现有数据来改进模型。贝叶斯方法是一个庞大的族群,不是仅包含了擅长处理小数据集的方法。对其的一些研究也会使用大数据集。
强化学习(Reinforcement learning)是一个广义的术语,指的是机器学习方法,其中智能体(计算机系统)通过反复试验来学习与环境交互。强化学习通常用于训练游戏系统、机器人和自动驾驶汽车。
例如,强化学习已被用于训练学习如何操作视频游戏的AI系统——从简单的街机游戏(如 Pong)到战略游戏(如星际争霸)。系统开始时对玩游戏知之甚少或一无所知,但通过尝试和观察摸索奖励信号出现的原因,从而不断学习。(在视频游戏的例子中,奖励信号常以玩家得分的形式呈现。)
强化学习系统通常从大量数据中学习,需要海量计算资源,因而它们被列入其中似乎是一个非直观类别。强化学习被襄括进来,是因为它们使用的数据通常是在系统训练时生成的——多在模拟的环境中——而不是预先收集和标记。在强化学习问题中,智能体与环境交互的能力至关重要。
图 1 展示了这些不同区域是如何相互连接的。每个点代表一个研究集群(一组论文),将其确定为属于上述类别之一。连接两个研究集群线的粗细代表它们之间引文链接的关联度。没有线则表示没有引文链接。如图所示,集群与同类别集群联系最多,但不同类集群之间的联系也不少。还可以从该图看到,“强化学习”识别的集群形成了特别连贯的分组,而“人工数据”集群则更加分散。
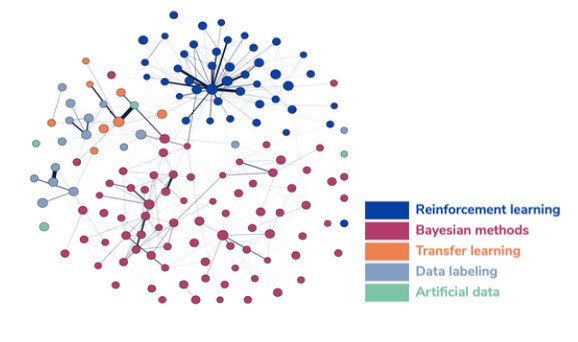
图1所示,小数据研究集群网络图
资料来源:CSET 合并学术文献语料库,截至 2021 年 2 月 12 日。
三、“小数据“方法重要在哪里?
1. 缩短大小实体间AI能力差距
AI 应用程序的大型数据集价值在不断增长,不同机构收集、存储和处理数据的能力差异缺令人担忧。人工智能的“富人”(如大型科技公司)和“穷人”之间也因此拉开差距。如果迁移学习、自动标记、贝叶斯方法等能够在少量数据的情况下应用于人工智能,那么小型实体进入数据方面的壁垒会大幅降低,这可以缩减大、小实体之间的能力差距。
2. 减少个人数据的收集
大多数美国人认为人工智能会吞并个人隐私空间。比如大型科技公司愈多收集与个人身份相关的消费者数据来训练它们的AI算法。某些小数据方法能够减少收集个人数据的行为,人工生成新数据(如合成数据生成)或使用模拟训练算法的方法,一个不依赖于个人生成的数据,另一个则具有合成数据去除敏感的个人身份属性的能力。虽然不能将所有隐私担忧都解决,但通过减少收集大规模真实数据的需要,让使用机器学习变得更简单,从而让人们对大规模收集、使用或披露消费者数据不再担忧。
3. 促进数据匮乏领域的发展
可用数据的爆炸式增长推动了人工智能的新发展。但对于许多亟待解决的问题,可以输入人工智能系统的数据却很少或者根本不存在。比如,为没有电子健康记录的人构建预测疾病风险的算法,或者预测活火山突然喷发的可能性。小数据方法以提供原则性的方式来处理数据缺失或匮乏。它可以利用标记数据和未标记数据,从相关问题迁移知识。小数据也可以用少量数据点创建更多数据点,凭借关联领域的先验知识,或通过构建模拟或编码结构假设去开始新领域的冒险。
4. 避免脏数据问题
小数据方法能让对“脏数据”烦不胜烦的大型机构受益。数据是一直存在的,但想要它干净、结构整齐且便于分析就还有很长的路要走。比如由于孤立的数据基础设施和遗留系统,美国国防部拥有不可计数的“脏数据”,需要耗费大量人力物力进行数据清理、标记和整理才能够“净化”它们。小数据方法中数据标记法可以通过自动生成标签更轻松地处理大量未标记的数据。迁移学习、贝叶斯方法或人工数据方法可以通过减少需要清理的数据量,分别依据相关数据集、结构化模型和合成数据来显着降低脏数据问题的规模。
对于从事人工智能工作的决策者而言,清楚地了解数据在人工智能发展中所扮演的角色和无法胜任的工作都至关重要。上述因素不适用于所有方法。例如,强化学习一般需要大量数据,但这些数据是在训练过程中生成的(例如,当 AI 系统移动机器人手臂或在虚拟环境中导航时),并不是预先收集的。
四、研究进展
在研究量方面,过去十年中五种“小数据”方法的曲线变化有着非同寻常的轨迹。如图2所示,强化学习和贝叶斯方法是论文数量最大的两个类别。贝叶斯集群论文量在过去十年间稳步增长,强化学习相关集群的论文量从2015年才开始有所增长,2017—2019年期间的增长尤为迅速。因为深度强化学习一直处于瓶颈期,直到2015年经历了技术性变革。相比之下,过去十年间,每年以集群形式发表的人工数据生成和数据标记研究论文数量一直是凤毛麟角。最后,迁移学习类的论文在 2010 时的数量比较少,但到 2020 年已实现大幅增长。

图2. 2010-2020 年小数据出版物的趋势
资料来源:CSET 合并学术文献语料库,截至 2021 年 2 月 12 日。
出版物的绝对数量并不能代表论文的质量。因此,研究人员利用两个指标来衡量每个类别集群中论文的质量:H指数和年限校正引用。H指数是常用的度量标准,表示论文的出版活动和总引用次数。H指数存在一个局限性是,没有考虑到论文出版时限(即较早的论文能够有更多的时间积累引用量的事实)。H指数低估了那些最有影响力且尚未收集引文的新发表论文集群。为调整上述问题,图3还描绘了经年限校正的引文。仅就 H指数而言,强化学习和贝叶斯方法大致相当,但考虑到论文的时限,强化学习脱颖而出。就五种“小数据”方法而论,贝叶斯方法的累积影响似乎更高,强化学习因其相对近期论文产量和引用影响的激增而一骑绝尘。
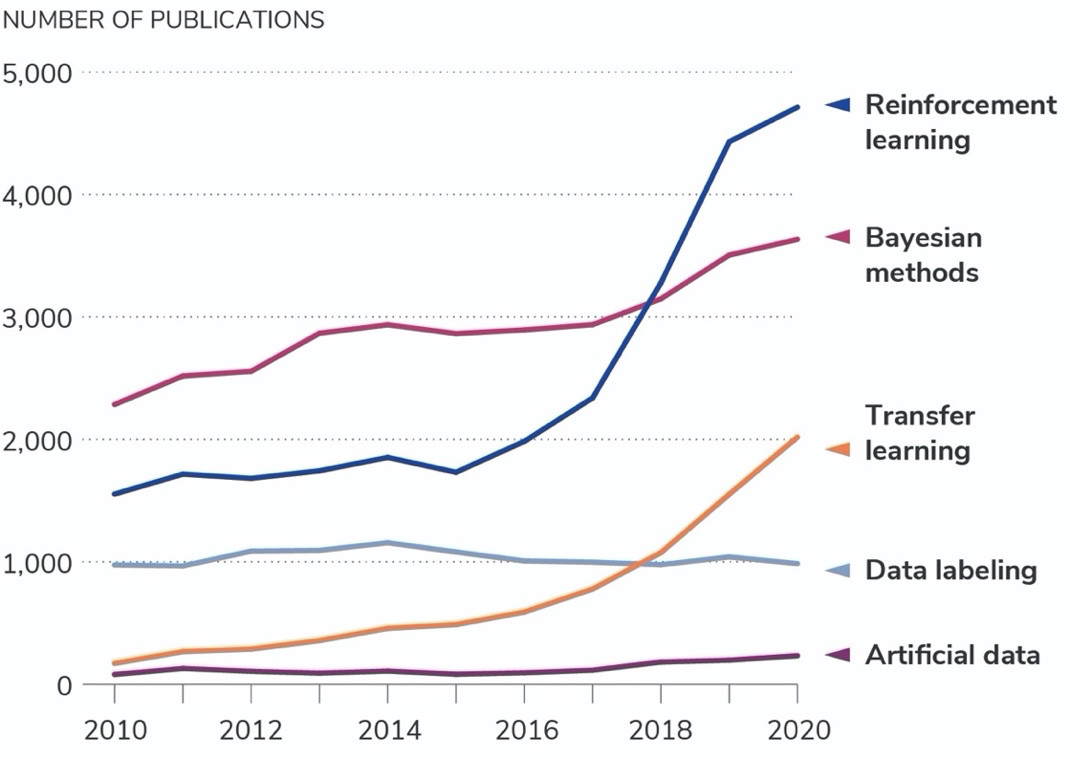
图3. 2010-2020 年按类别划分的 H 指数和年限校正引用
资料来源:CSET 合并学术文献语料库,截至 2021 年 2 月 1 日。
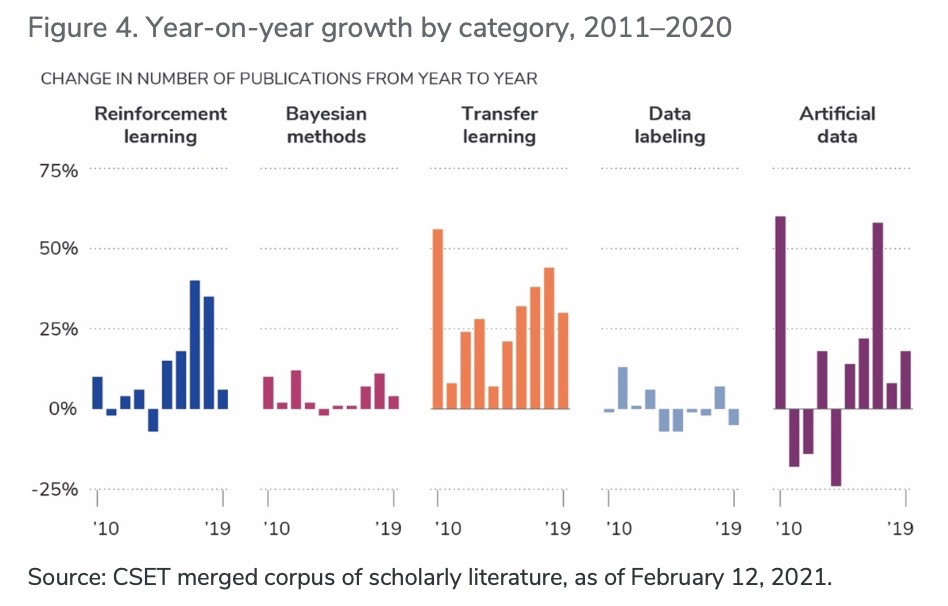
图4. 2011-2020 年按类别划分的同比增长
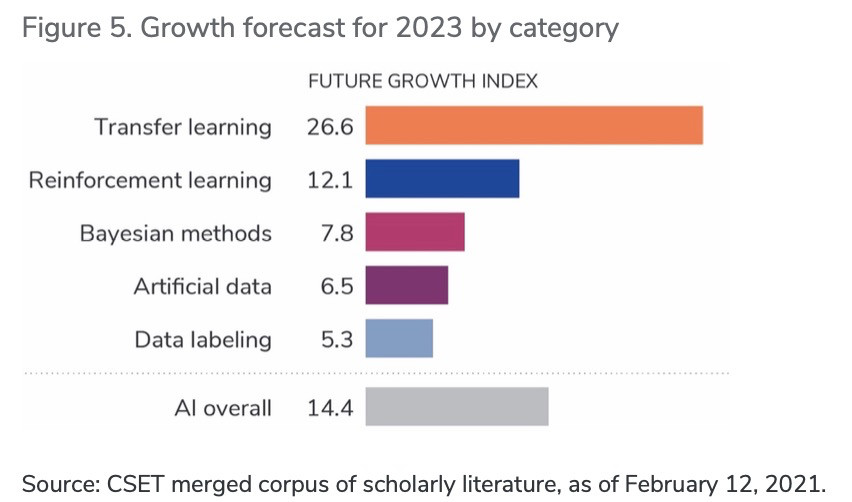
图5. 按类别划分的 2023 年增长预测
资料来源:CSET 合并学术文献语料库,截至 2021 年 2 月 12 日。
注:未来增长指数是根据 CSET 对研究集群增长的预测计算得出的。
五、国家竞争力
通过查看全球前10个国家在每种方法中取得的研究进展,可以推导出小数据方法的国家竞争力。以简单的衡量指标,如发表论文数量和按年限调整的引用次数,初步了解各国在五种“小数据”方法的相应地位。
与AI研究的总体结果一致,中国和美国是研究“小数据”集群论文量前两位,紧随其后的是英国。中国在数据标记和迁移学习方法领域的学术出版物总数遥遥领先,而美国在贝叶斯方法、强化学习和人工数据生成方面较有优势。除美国和中国外,其他小数据研究排名前10位的国家都是美国的盟友或合作伙伴,俄罗斯等国明显缺席榜单。当前学术界常用论文引用量经衡量研究质量和影响。中国在所有小数据类别中的按年限调整引用量排名第二,在贝叶斯方法中的排名降至第七。
图6显示的是按国家细分的三年增长预测情况。相对于美国和世界其他地区,中国在迁移学习方法方面的增长预计会大幅提升。这一测如果准确,意味着中国会在迁移学习方面发展得更快更远。
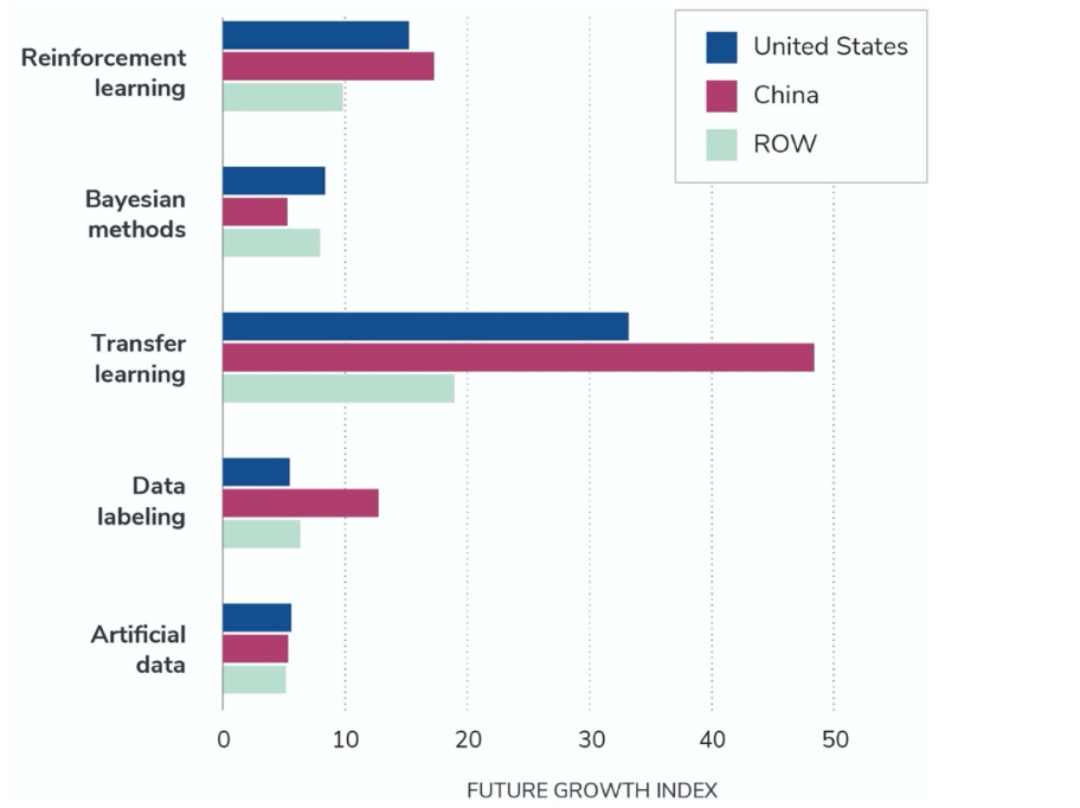
图6. 2023 年美国、中国和世界其他地区(ROW)按类别划分的增长预测
资料来源:CSET 合并学术文献语料库,截至 2021 年 2 月 12 日。
六、资金筹集
研究人员分析了可用于小数据方法的资助数据,以确定研究集群中资助论文实体类型的估量。对于上述调研结果,只有大约 20-30% 的论文的资助信息。
在各个领域中,在政府、公司、学术界和非营利组织中,政府人员一般是研究的重要资助者。在全球范围内,政府资助在“小数据”方法集群中所占的比例远高于人工智能整个领域。如图7所示,在所有5大类别中,与AI研究整体的经费分解相比,政府资助的份额非常高。非盈利组织在用于小数据研究的资金中所占的比例比通常用于人工智能的其余部分要小。贝叶斯方法的资助模式与AI总体上最为相似。
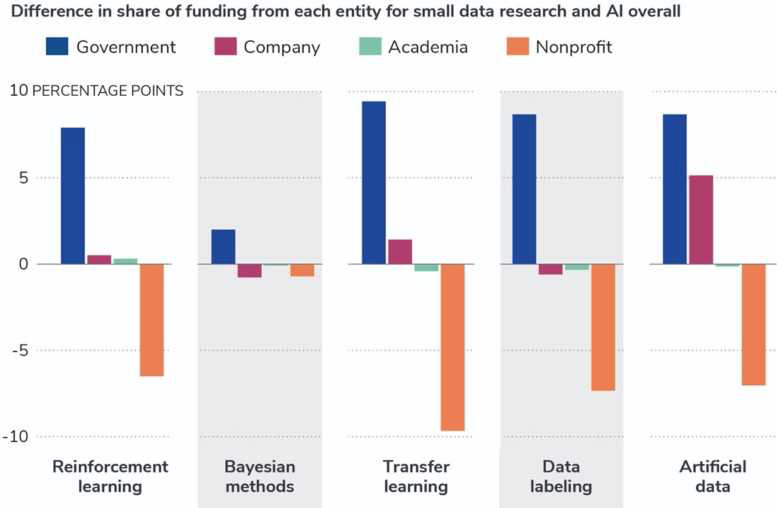
图7. 与 AI 整体相关的数据方法的资金来源
资料来源:CSET 合并学术文献语料库,截至 2021 年 2 月 12 日。
图 8 进一步按国家/地区细分了与政府相关的资金信息。研究结果表明,政府在小数据中投入资金所占比例总体呈上升趋势,但整体来看,美国政府对小数据研究的资金份额低于其在人工智能方面的份额。个体机构、企业倾向于为美国的小数据研究提供比整个Al研究更大的份额。
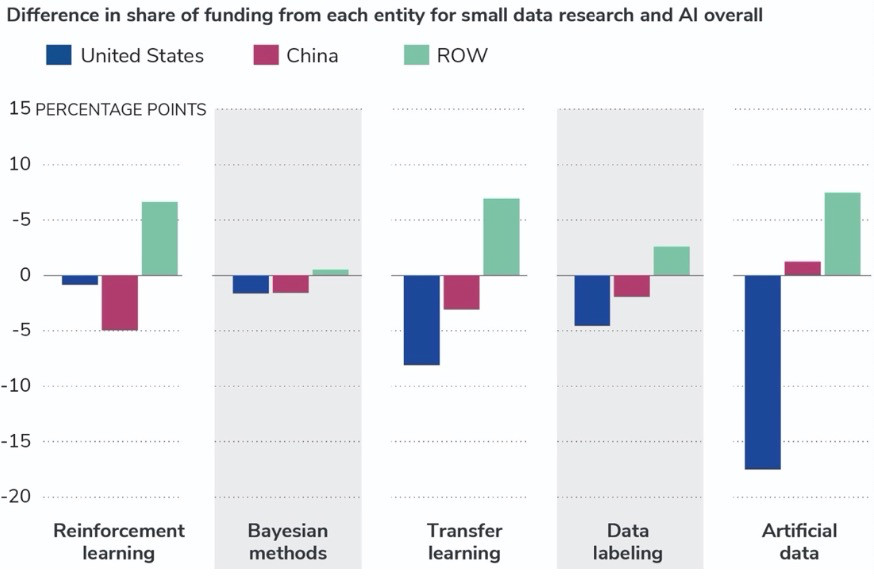
图8. 中国、美国和世界其他地区(ROW)对于人工智能相关的小数据方法的政府资助
资料来源:CSET 合并学术文献语料库,截至 2021 年 2 月 12 日。
七、总结
a) 人工智能不等于大数据。
b) 对迁移学习的研究进展飞快,在未来迁移学习会更有效地被更广泛应用。
c) 美国和中国在小数据方法方面的竞争非常激烈。美国在强化学习和贝叶斯方法这两个类别中处于优势,而中国在增长最快的迁移学习类别中一马当先,并且将差距在逐渐加大。
d) 目前相对于整个人工智能领域的投资模式而言,美国在小数据方法上的投资份额更小,因此迁移学习可能是美国政府加大资金投入的前景目标。






















