深度是深度神经网络的关键,但更多的深度意味着更多的序列计算和更多的延迟。这就引出了一个问题——是否有可能构建高性能的「非深度」神经网络?
近日,普林斯顿大学和英特尔实验室的一项研究证明了这一观点的可行性。该研究使用并行子网络而不是一层又一层地堆叠,这有助于在保持高性能的同时有效地减少深度。

论文地址:https://arxiv.org/abs/2110.07641
通过利用并行子结构,该研究首次表明深度仅为 12 的网络可在 ImageNet 上实现超过 80%、在 CIFAR10 上实现超过 96%、在 CIFAR100 上实现 81% 的 top-1 准确率。该研究还表明,具有低深度主干网络的模型可以在 MS-COCO 上达到 48% 的 AP 指标。研究者分析了该设计的扩展规则,并展示了如何在不改变网络深度的情况下提高性能。最后,研究者提供了关于如何使用非深度网络来构建低延迟识别系统的概念证明。
方法
该研究提出了一种深度较低但仍能在多项基准上实现高性能的网络架构 ParNet,ParNet 由处理不同分辨率特征的并行子结构组成。这些并行子结构称为流(stream),来自不同流的特征在网络的后期融合,融合的特征用于下游任务。图 2a 提供了 ParNet 的示意图。
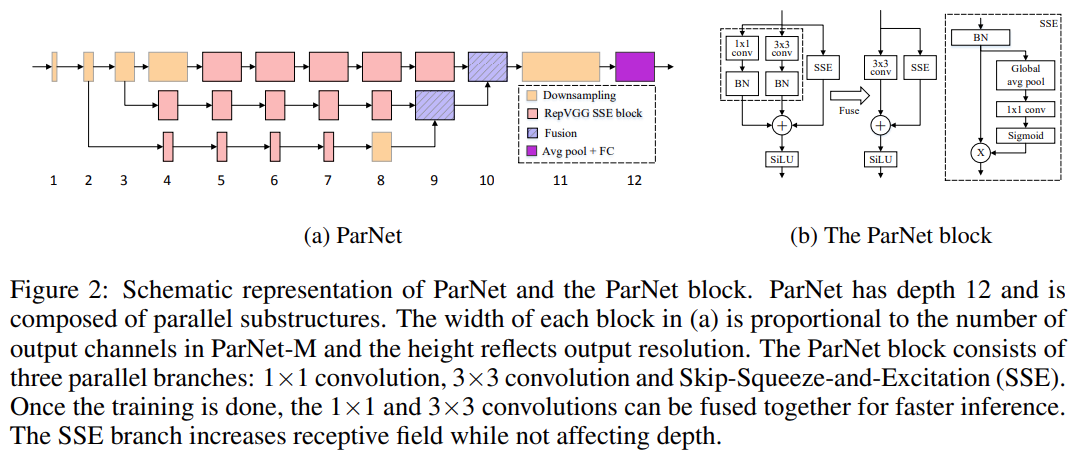
图 2
ParNet Block
ParNet 中使用了 VGG 风格的 block(Simonyan & Zisserman,2015)。为了探究非深度网络是否可以实现高性能,该研究通过实验发现 VGG 风格 block 比 ResNet 风格 block 更合适(如下表 8 所示)。一般来说,训练 VGG 风格的网络比 ResNet 更难(He 等,2016a)。但是最近的一些工作表明,使用「结构重参数化」方法(Ding 等,2021),会让 VGG 风格 block 更容易训练。
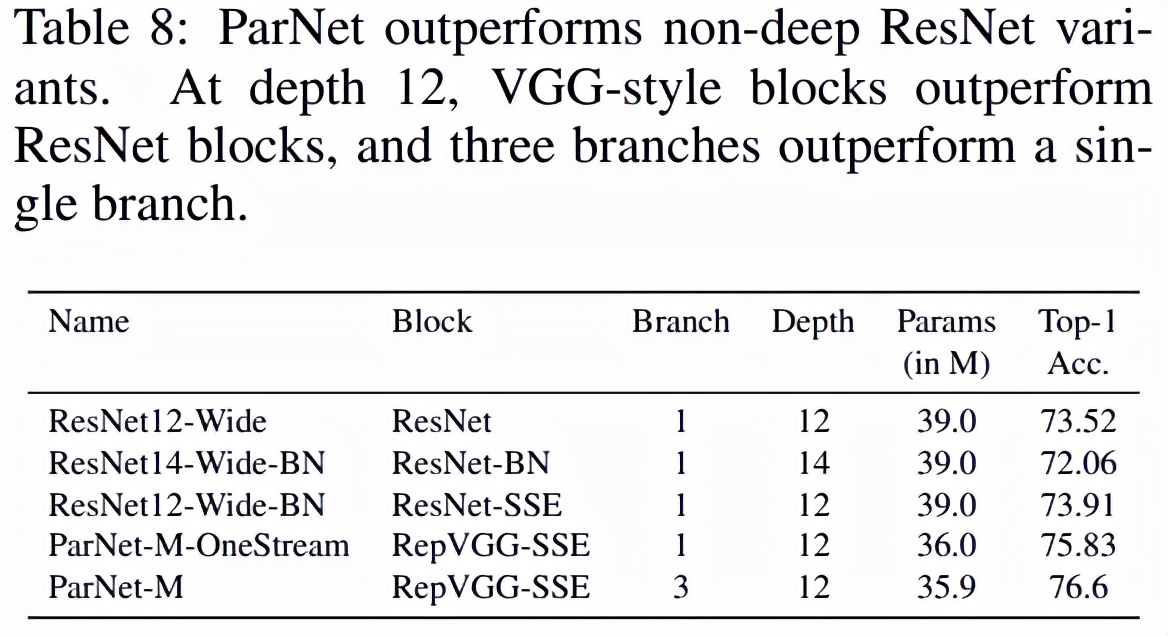
训练期间,该研究在 3×3 卷积 block 上使用多个分支。训练完成后,多个分支可以融合为一个 3×3 的卷积 block。因此,最终得到一个仅由 3×3 block 和非线性组成的简单网络。block 的这种重参数化或融合(fusion)有助于减少推理期间的延迟。
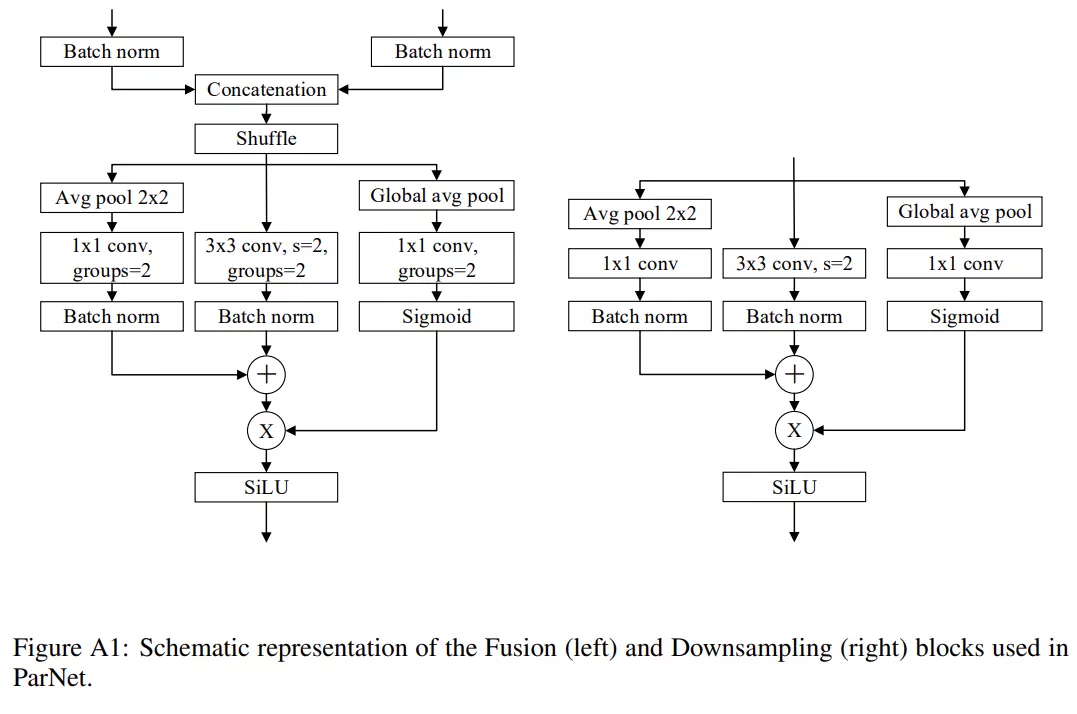
降采样和融合 block
除了输入和输出大小相同的 RepVGG-SSE block 之外,ParNet 还包含降采样(downsampling)和融合 block。降采样 block 降低了分辨率并增加了宽度以实现多尺度(multi-scale)处理,而融合 block 将来自多个分辨率的信息组合。在降采样 block 中,没有残差连接(skip connection);相反,该研究添加了一个与卷积层并行的单层 SE 模块。
此外,该研究在 1×1 卷积分支中添加了 2D 平均池化。融合 block 和降采样 block 类似,但还包含一个额外的串联(concatenation)层。由于串联,融合 block 的输入通道数是降采样 block 的两倍。为了减少参数量,该研究的降采样和融合 block 的设计如下图所示。
网络架构
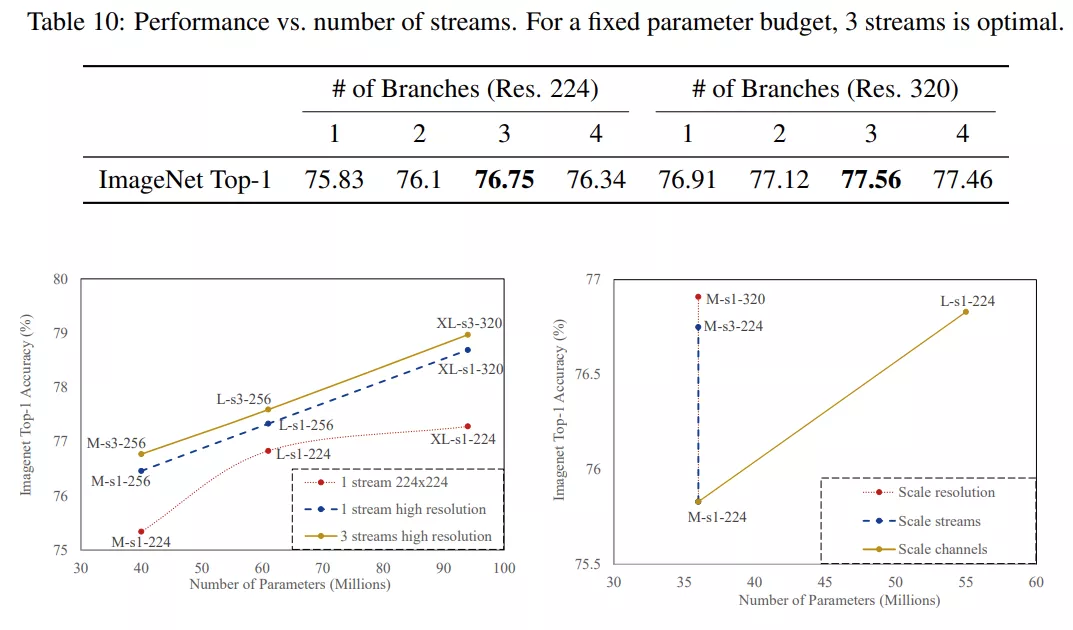
图 2a 展示了用于 ImageNet 数据集的 ParNet 模型示意图。初始层由一系列降采样块组成,降采样 block 2、3 和 4 的输出分别馈送到流 1、2 和 3。研究者发现 3 是给定参数预算的最佳流数(如表 10 所示)。每个流由一系列不同分辨率处理特征的 RepVGG-SSE block 组成。然后来自不同流的特征由融合 block 使用串联进行融合。最后,输出被传递到深度为 11 的降采样 block。与 RepVGG(Ding 等, 2021)类似,该研究对最后一个降采样层使用更大的宽度。
扩展 ParNet
据观察,神经网络可以通过扩大网络规模来获得更高的准确度。之前的研究 (Tan & Le, 2019) 扩展了宽度、分辨率和深度。由于本研究的目标是评估是否可以在深度较低的情况下实现高性能,因此研究者将模型的深度保持不变,通过增加宽度、分辨率和流数来扩展 ParNet。
对于 CIFAR10 和 CIFAR100,该研究增加了网络的宽度,同时将分辨率保持为 32,流数保持为 3。对于 ImageNet,该研究在三个不同的维度上进行了实验,如下图 3 所示。
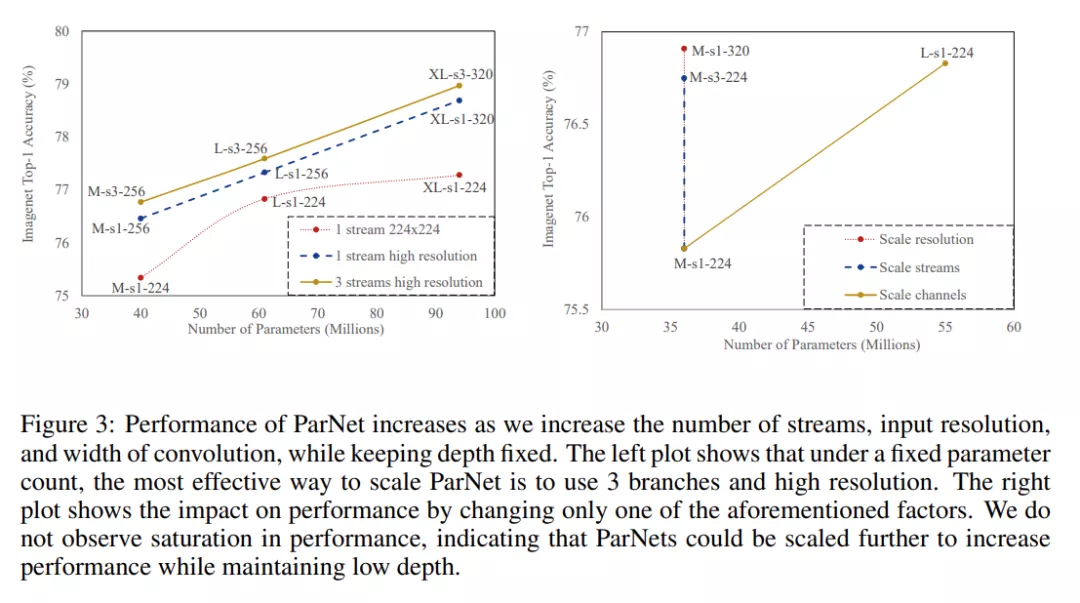
并行架构的实际优势
目前 5 纳米光刻工艺已接近 0.5 纳米晶硅尺寸,处理器频率进一步提升的空间有限。这意味着神经网络的更快推理必须依赖计算的并行化。单个单片 GPU 的性能增长也在放缓,预计传统光刻可实现的最大芯片尺寸将达到 800 平方毫米(Arunkumar 等,2017)。总体而言,未来在处理器频率、芯片尺寸以及每个处理器的晶体管数等方面都将维持一个平稳状态。
为了解决这个问题,最近的一些工作提出了多芯片模块 GPU (MCM-GPU),比最大的可实现单片 GPU 更快。用中型芯片取代大型芯片有望降低硅成本。这样的芯片设计有利于具有并行分支的分区算法,算法之间交换有限的数据并且尽可能地分别独立执行。基于这些因素,非深度并行结构将有利于实现快速推理,尤其是对于未来的硬件。
实验结果
表 1 展示了 ParNet 在 ImageNet 上的性能。该研究发现,深度仅为 12 的网络就可以实现惊人的高性能。为了与 ResNet 进行公平比较,研究者使用相同的训练协议和数据增强重新训练 ResNet,这将 ResNet 的性能提升到了超越官方结果的水平。值得注意的是,该研究发现 ParNet-S 在参数数量较少的情况下(19M vs 22M)在准确率上比 ResNet34 高出 1 个百分点以上。ParNet 还通过瓶颈设计实现了与 ResNet 相当的性能,同时深度减少到 1/4-1/8。
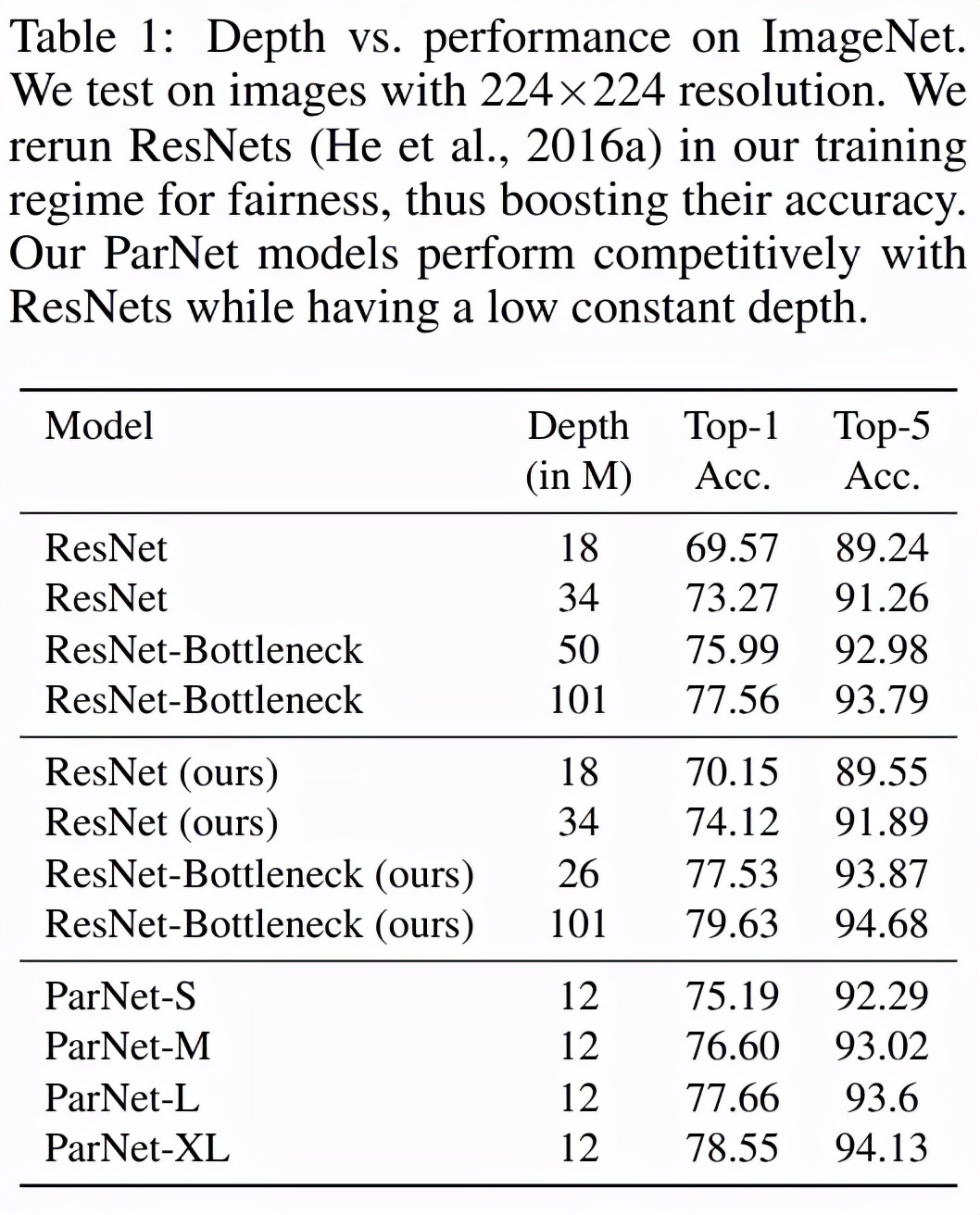
如下表 2 所示,ParNet 在准确率和速度上优于 ResNet,但参数和 flop 也更多。例如,ParNet-L 实现了比 ResNet34 和 ResNet50 更快的速度和更好的准确度。类似地,ParNet-XL 实现了比 ResNet50 更快的速度和更好的准确度,但具有更多的参数和 flop。这表明使用 ParNet 代替 ResNet 时存在速度与参数和 flop 之间的权衡。请注意,可以通过利用可以分布在 GPU 上的并行子结构来实现高速。
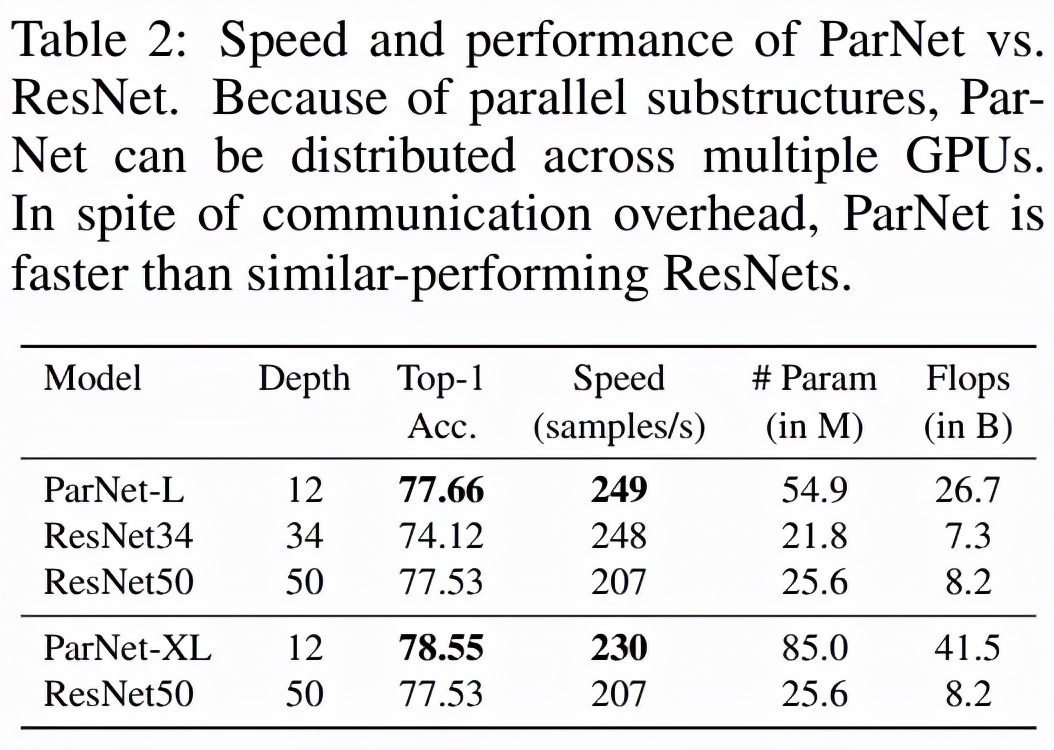
该研究测试了 ParNet 三种变体的速度:未融合、融合和多 GPU,结果如下表 3 所示。未融合的变体由 RepVGG-SSE 块中的 3×3 和 1×1 分支组成。在融合变体中,使用结构重参数化技巧将 3×3 和 1×1 分支合并为一个 3×3 分支。对于融合和未融合变体,该研究使用单个 GPU 进行推理,而对于多 GPU 变体,使用了 3 个 GPU。对于多 GPU 变体,每个流都在单独的 GPU 上启动。当一个流中的所有层都被处理时,来自两个相邻流的结果将在其中一个 GPU 上连接并进一步处理。为了跨 GPU 传输数据,该研究使用了 PyTorch 中的 NCCL 后端。
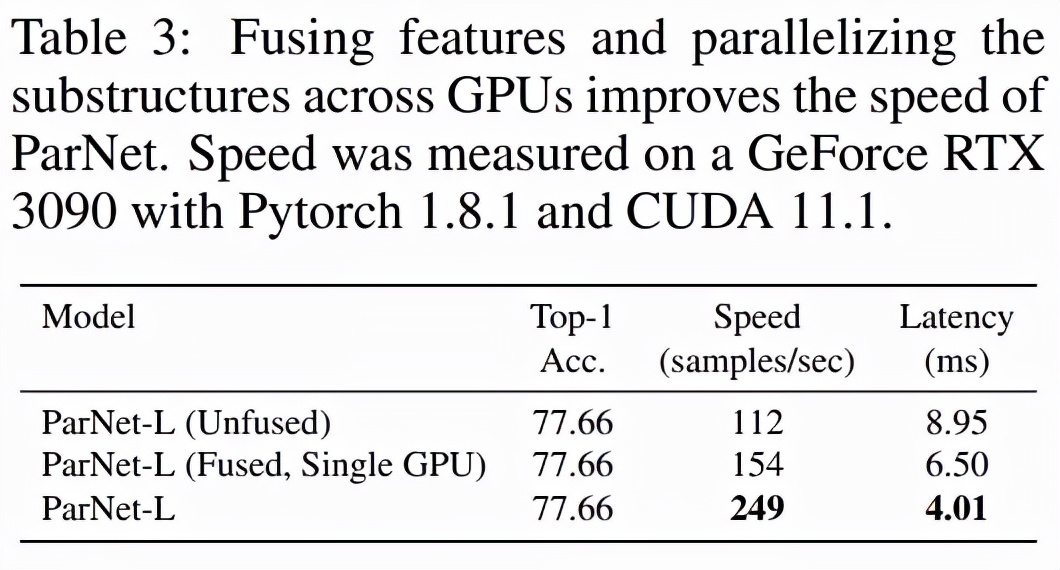
该研究发现尽管存在通信开销,但 ParNet 仍可以跨 GPU 有效并行化以进行快速推理。使用专门的硬件可以减少通信延迟,甚至可以实现更快的速度。
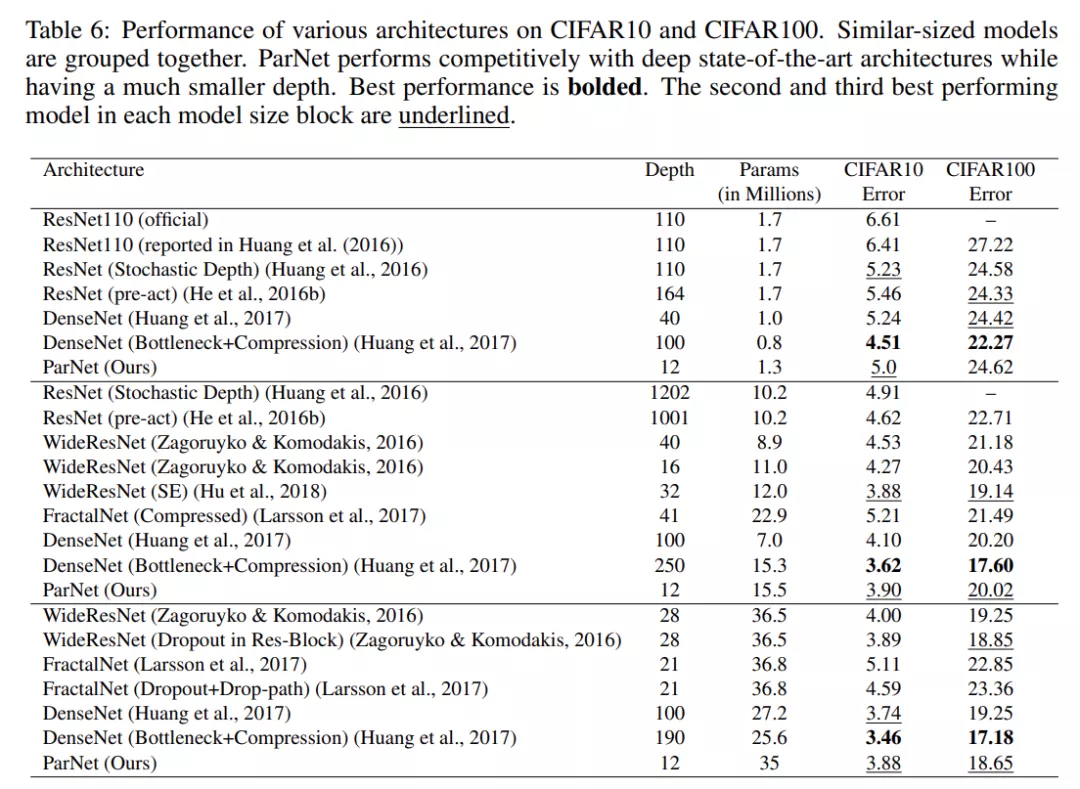
表 5 展示了提高 ParNet 性能的其他方法,例如使用更高分辨率的图像、更长的训练机制(200 个 epoch、余弦退火)和 10-crop 测试。这项研究有助于评估非深度模型在 ImageNet 等大规模数据集上可以实现的准确性。
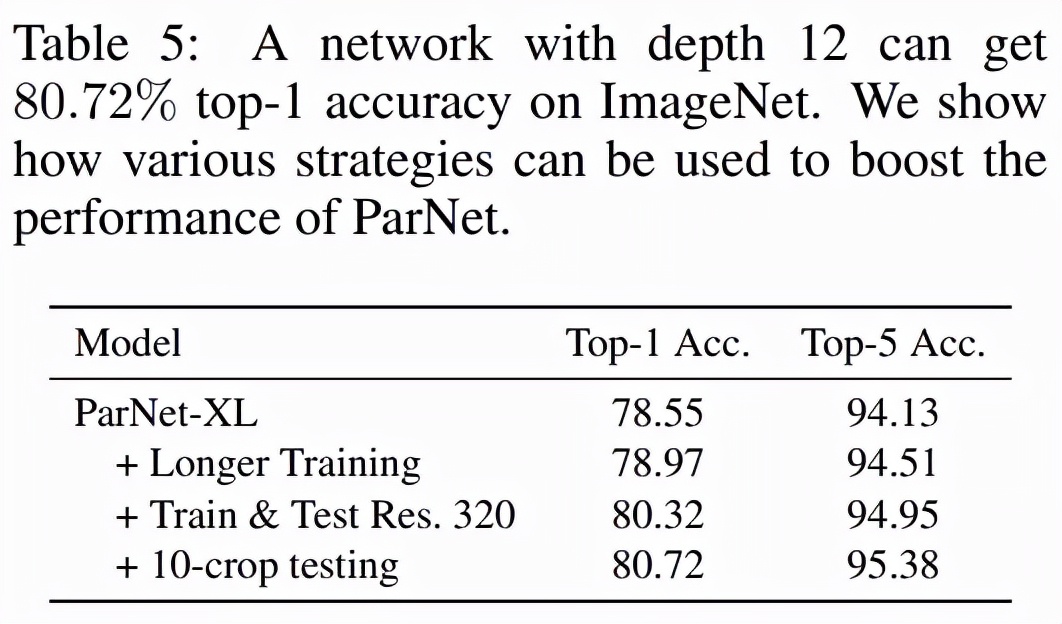
MS-COCO (Lin 等,2014) 是一个目标检测数据集,其中包含具有常见对象的日常场景图像。研究者用 COCO-2017 数据集进行了评估。如下表 4 所示,即使在单个 GPU 上,ParNet 也实现了比基线更高的速度。这阐明了如何使用非深度网络来制作快速目标检测系统。
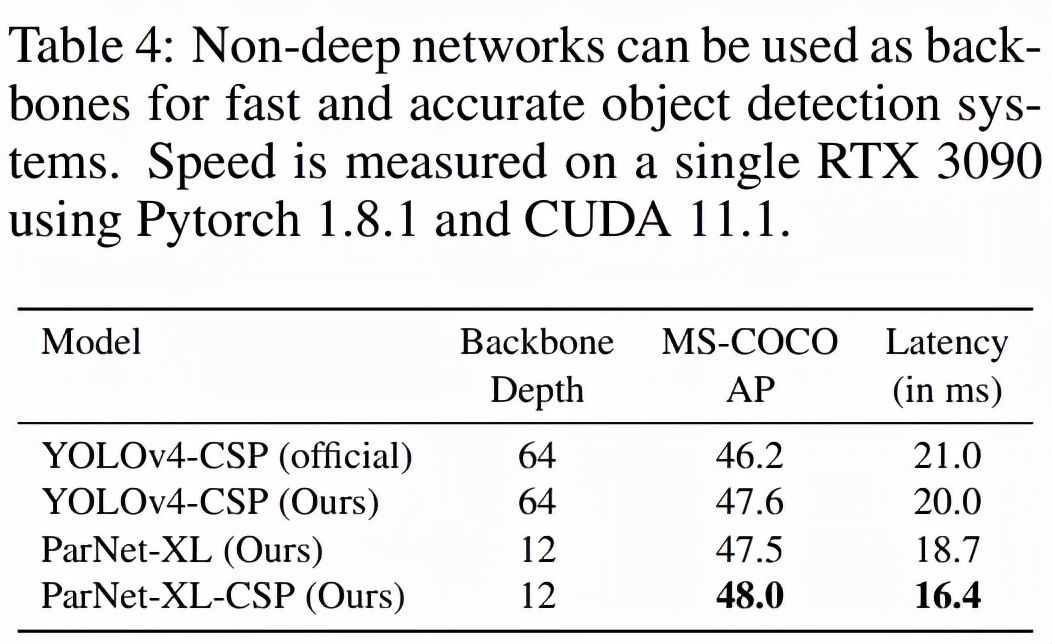
表 6 总结了各种网络在 CIFAR10 和 CIFAR100 上的性能。
消融实验
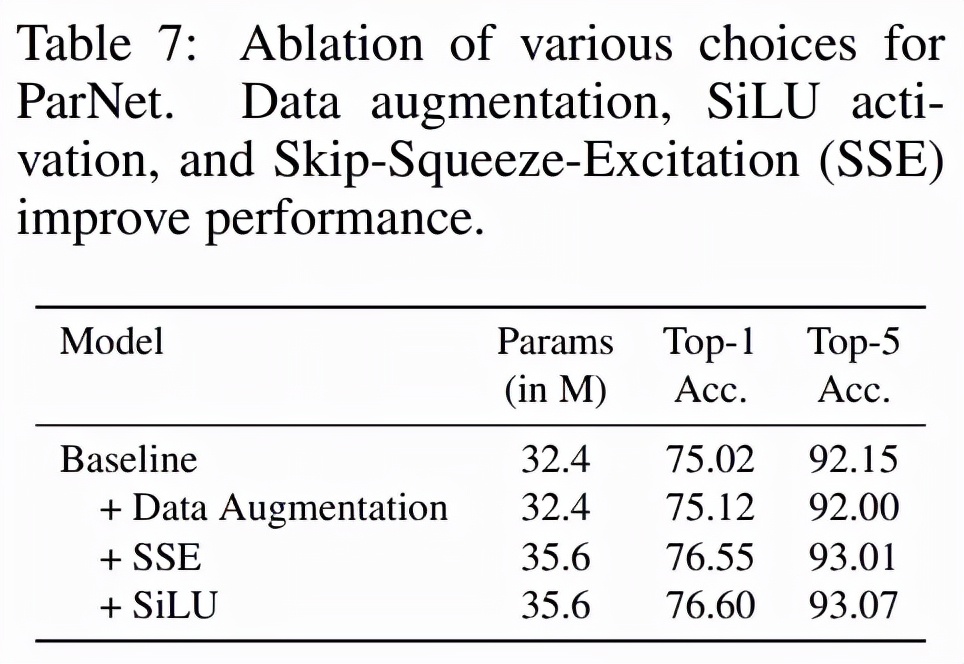
为了测试是否可以简单地减少 ResNet 的深度并使它们变宽,研究者测试了三个 ResNet 变体:ResNet12-Wide、ResNet14-Wide-BN 和 ResNet12-Wide-SSE。ResNet12-Wide 使用 ResNet 基础 block,深度为 12,而 ResNet14-Wide-BN 使用 ResNet 瓶颈 block,深度为 14。表 7 展示了对网络架构和训练协议的各种设计的消融研究结果,其中包括使用数据增强、SSE block 和 SiLU 激活函数的 3 种情况。
在表 10 中,研究者评估了参数总数相同但分支数不同( 1、2、3、4)的网络。实验表明,对于固定数量的参数,具有 3 个分支的网络具有最高的准确率,并且在网络分辨率分别为 224x224 和 320x320 这两种情况下都是最优的。
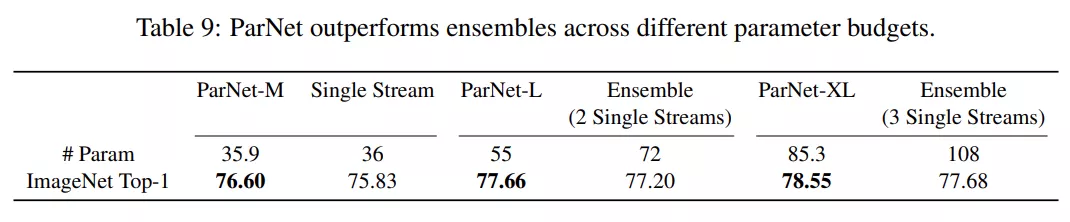
另一种网络并行化的方法是创建由多个网络组成的集合体。因此,该研究将 ParNet 和集成的网络进行对比。如下表 9 所示,当使用较少的参数时,ParNet 的性能优于集成的网络。