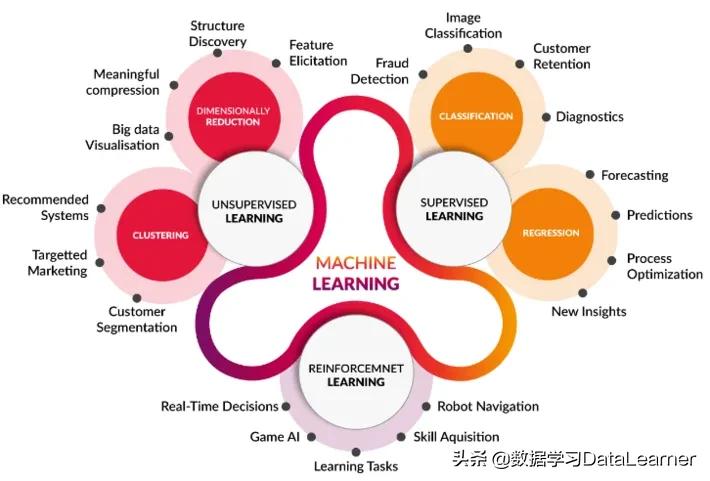
机器学习主要分成有监督学习、无监督学习和强化学习。但是各种方法的应用领域却有所不同,下面将简单介绍。
有监督学习
有监督学习是指根据带有标签的训练数据学习模型,并最终预测新数据集的标签。根据标签是否离散或者多值也可以细分成很多问题,包括回归问题、二元分类、多标签分类、多值分类等。这里仅分成回归和分类两类来描述其应用领域。
分类问题:
- 欺诈检测:比如银行里面信用卡贷款审批需要考虑客户的还款能力等,防止出现违约甚至故意欺骗银行贷款等行为,这就需要欺诈检测,即根据客户的信息和行为,判断其欺诈的概率。
- 图像分类:这很容易理解,比如人脸识别。给定一张图像,需要判断属于谁,或者你的认证图像是否与本人一致。
- 客户留存:客户流失会影响公司的业务,如何判断哪些用户即将离开是很重要的问题,客户留存的判断也是有监督学习的重要应用。
- 医疗诊断:比如给出患者的历史病历以及描述等,判断患者的疾病。甚至是根据病情给出医疗方法。
回归问题:
- Forecasting预测:这类预测,一般是指基于已有的历史数据来预测未来的情况。最典型的应用就是时序数据的预测。
- Prediction预测:这种预测更具有一般性,不仅仅是指对未来的预测,还包括基于现有的数据判断其输出的值。比如说基于面积和位置判断房屋价格。
- 流程优化:这个问题主要是追踪生产流程系统,预测其行为来提升性能。
- new insights:说实话这个应用我自己也没理解。洞察是一系列的分析行为,这里的含义可能是基于现有业务进行预测用以洞察未来。
无监督学习
无监督学习是基于没有标签的数据对进行学习,进而自动分类。无监督学习在理解数据,提升性能方面有很多不可替代的作用。这里无监督学习的应用主要分为两类,一种是聚类,另一种是维度约减。
聚类应用
- 客户分群:这是一个非常古老的话题了。主要是根据客户的购买和其他行为数据将客户分成不同的类别,进而做不同的营销策略。这个应用在实际情况中,非常常见也很多。
- 目标营销:目标营销是一种提高产品或服务在特定(目标)受众群体中的知名度的方法,这些受众是总的市场中的一个子集。
- 推荐系统:推荐系统是目前非常常见的应用,聚类在推荐系统的主要作用是对产品和用户进行划分,进而提高推荐系统的性能。
维度约减
- 大数据可视化:大数据场景下,维度很高,数据的可视化更加具有挑战性。聚类可以帮助我们压缩数据维度,保持数据特性,提升大数据可视化的效果。
- 数据压缩:数据压缩是另外一种非常常见的应用场景,在图像显示、数据传输等领域都有很多应用。
- 结构发现:在数据理解和洞察的时候,经常需要对数据的结构进行整理和划分,以帮助我们快速了解数据,发现规律。聚类可以有效提升结构发现的效率。
- 特征消减:在基于数据进行预测等场景中特征是很重要的输入参数,但是类似的特征既会降低运行的效率,也会影响准确性。使用聚类方法对特征进行约减,可以帮助我们提升预测效率,降低无效输入。
强化学习
强化学习,主要是根据特定的环境场景,寻找有效的措施和策略,以获取最大的收益。随着AlphaGo的名声大噪,基于强化学习的应用和发展,在这几年取得了显著的成就。
其主要应用场景包括:
- 实时决策:在实际生活和工作当中有很多问题都需要实时决策。比如说无人机在飞行的过程中需要根据环境的条件调整自己的姿态和速度以保证飞行安全等。基于强化学习的实时决策可以帮助我们更好的实现自动控制等问题。
- 游戏AI:王者荣耀中的机器人就是基于强化学习的结果。AI在数以万计的比赛中根据策略获得的奖惩获取优化的策略。
- 机器人导航:基于机器人识别到的环境和道路,决定导航路线。强化学习可以根据学习到的场景从多种导航策略中选择最优的内容。