












【51CTO.com快译】本文将重点向您介绍如何使用Prometheus Operator和Helm Chart,以及如何以简单的方式在Kubernetes集群上安装和管理Prometheus。首先,让我们先了解一些与Prometheus Operator相关的基本概念。
CRD(Custom Resource Definition,定制资源定义)的方法是允许用户自定义Deployment和StatefulSet等资源类型的结构和有效性。其中,CR(Custom Resource,定制资源)是按照CRD的结构所创建的资源。而Custom Controller(定制控制器)则能够确保Kubernetes集群、或应用程序始终将其当前的状态,与我们所期望的状态相匹配。因此,Operator可以被理解为我们部署在集群中的一组Kubernetes定制控制器。它会去侦听被定制资源中,针对Kubernetes资源的创建、修改、删除等操作。您可以通过链接-- https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/,了解更多有过定制资源的相关内容。
Kubernetes Operator的用例
总的说来,Kubernetes Operator可以实现:
- 提供一种在Kubernetes上部署有状态服务(如各种数据库)的方法
- 处理应用程序代码的升级
- 根据性能指标,横向扩展资源
- 按需备份和恢复应用程序或数据库的状态
- 向Kubernetes部署监控、存储、归档(vault)等方案
什么是Prometheus Operator?
简单来说,类似其他标准化的Kubernetes部署对象,Prometheus Operator能够以完全自动化的方式部署Prometheus服务器、Alertmanager、以及所有相关的密钥和configmap等。该方式有助于在较短几分钟内,建立出Prometheus监控系统,并实例化Kubernetes的集群监控。而在完成部署后,Prometheus Operator将具有如下功能:
- 自动化:便捷地为Kubernetes的命名空间、特定的应用或团队启动Prometheus实例。
- 服务发现:无需额外学习Prometheus的特定配置语言,便可使用熟悉的Kubernetes标签,自动发现有待监控的目标。
- 轻松配置:可管理Prometheus的版本、持久性、留存策略、以及来自Kubernetes资源的副本等基本资源的相关配置。
安装Prometheus栈的方法
在Kubernetes中设置Prometheus监控栈有如下三种不同的方法:
1.自行创造一切
如果您已准备好了Prometheus组件、及其先决条件,则可以通过参考其相互之间的依赖关系,以正确的顺序为Prometheus、Alertmanager、Grafana的所有密钥、以及ConfigMaps等每个组件,手动部署YAML规范文件。这种方法通常非常耗时,并且需要花费大量的精力,去部署和管理Prometheus生态系统。同时,它还需要构建强大的文档,以便将其复制到其他环境中。
2. 使用Prometheus Operator
既然前文提到了Prometheus Operator能够管理Prometheus所有组件的生命周期,那么我们可以参考链接--https://github.com/prometheus-operator/prometheus-operator,据此在Kubernetes集群中部署Prometheus。
3. 使用Helm Chart部署Operator
作为一种更好、更高效的方式,我们可以使用由Prometheus社区维护的Helm Chart,来部署Prometheus Operator。概括地说,Helm会随着Prometheus、Alertmanager和其他定制资源的创建,进行Prometheu Operator的初始化安装。然后,Prometheus Operator会管理这些定制资源的整个生命周期。其安装步骤如下:
- Go
- helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
- helm repo update
- helm install prometheus prometheus-community/kube-prometheus-stack
此处的kube-Prometheus-stack安装了以下组件:
- Prometheus Operator
- 创建Prometheus、Alertmanager、以及相关的CR
- Grafana
- 各种节点导出器
它们还预先配置了针对协同工作、以及为您设置了基本集群的监控,以方便您轻松地调整和添加各种自定义。上述命令的执行速度非常快,只需几分钟便可启动并运行所有的组件。
您可以通过“helm get manifestPrometheus| kubectl get -f –”命令,来查看创建的所有对象。
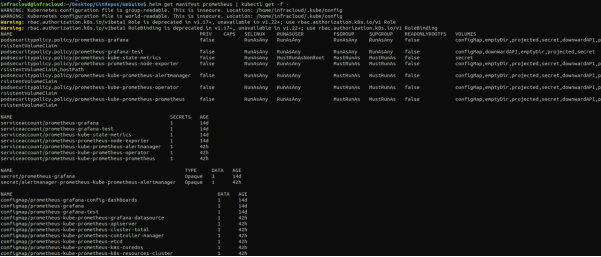
如上所图示,您将能够看到Prometheus栈的Deployments和StatefulSet等所有不同的资源。
Prometheus如何找到所有监控项并抓取的目标?
为了让Prometheus发现待监控的对象,我们需要传递一个被称为prometheus.yaml的YAML(配置文件,以便Prometheus可以参考并实施监控。每个待监控的目标端点都在prometheus.yaml中的scrape_configs部分下被定义。下面展示了Prometheus release tar中自带的典型配置文件的内容:
- Go
- # my global config
- global:
- scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
- evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
- # scrape_timeout is set to the global default (10s).
- # Alertmanager configuration
- alerting:
- alertmanagers:
- - static_configs:
- - targets:
- - localhost:9093
- # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
- rule_files:
- - '/etc/prometheus/alert.rules'
- # - "first_rules.yml"
- # - "second_rules.yml"
- # A scrape configuration containing exactly one endpoint to scrape:
- # Here it's Prometheus itself.
- scrape_configs:
- # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- - job_name: 'prometheus'
- # metrics_path defaults to '/metrics'
- # scheme defaults to 'http'.
- static_configs:
- - targets: ['localhost:9090']
- - job_name: 'node_exporter'
- scrape_interval: 5s
- static_configs:
- - targets: ['localhost:9100']
下面,让我们深入了解prometheus.yaml文件中的一些主要关键术语。其中,我们可以通过如下两种方式,为Prometheus指定目标端点集合:
- scrape_config通过指定一组目标和配置参数,来描述如何抓取他们。也就是说,在prometheus.yaml文件中,我们需要针对每个目标定义一个抓取配置块。
- ServiceMonitor则让我们以Kubernetes原生的方式,轻松地在scrape_config中创建一个作业条目。在内部,Prometheus Operator将配置从每个 ServiceMonitor资源转换为prometheus.yaml的scrape_config部分。由kube-prometheus-stack创建的Prometheus资源带有一个选择器,可以对所有带有标签release: prometheus(请参见配置)的ServiceMonitor进行各项操作。下图展示了其工作原理:
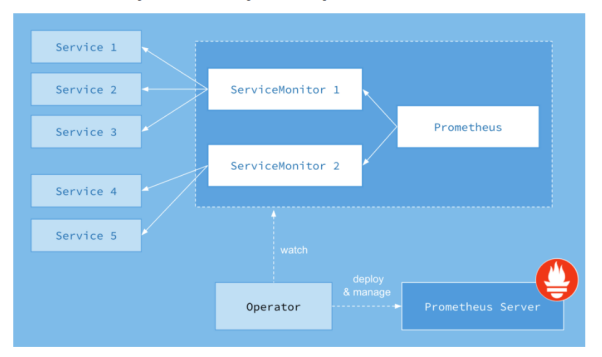
图片来源:CoreOS(https://www.openshift.com/blog)
让我们以Prometheus服务本身为例,查看ServiceMonitor能否自动在Prometheus配置文件中创建了一个scrape_config条目。
- Go
- kubectl get services prometheus-prometheus-oper-prometheus -o wide --show-labels
- NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR LABELS
- prometheus-prometheus-oper-prometheus ClusterIP 10.105.67.172 <none> 9090/TCP 12d app=prometheus,prometheus=prometheus-prometheus-oper-prometheus app=prometheus-operator-prometheus,release=prometheus,self-monitor=true
根据上述代码,我们进而可以查看相应的ServiceMonitor是否已为Prometheus的服务准备就绪。
- Go
- kubectl get servicemonitors.monitoring.coreos.com -l app=prometheus-operator-prometheus
- NAME AGE
- prometheus-prometheus-oper-prometheus 12d
上述代码证实了Prometheus服务本身ServiceMonitor的存在性。下面,让我们检查“prometheus-prometheus-oper-prometheus”是否已在Prometheusconfig YAML文件中添加了一个作业。我们首先需要访问由Prometheus Operator创建的Prometheuspod。
- Go
- kubectl exec -it prometheus-prometheus-prometheus-oper-prometheus-0 -- /bin/sh
- /prometheus $
让我们通过如下代码找出pod内由Prometheus使用的配置文件名。
- Go
- /prometheus $ ps
- PID USER TIME COMMAND
- 1 1000 4h58 /bin/prometheus … --config.file=/etc/prometheus/config_out/prometheus.env.yaml
- 59 1000 0:00 /bin/sh
从上述代码可知,由Operator创建的配置文件prometheus.env.yaml可以被Prometheus服务器用于查找待监控和抓取的目标端点。最后,让我们检查Prometheus服务本身的作业是否已被ServiceMonitor添加到了该配置文件中:
- Go
- /Prometheus $ cat / etc /Prometheus/ config_out /Prometheus。ENV 。yaml | grep - i - A 10 "job_name: default/prometheus-prometheus-oper-prometheus/0"
- Go
- - job_name: default/prometheus-prometheus-oper-prometheus/0
- honor_labels: false
- kubernetes_sd_configs:
- - role: endpoints
- namespaces:
- names:
- - default
- metrics_path: /metrics
由上述代码可知,ServiceMonitor会自动为基于Kubernetes的服务创建一个待监控和抓取的作业。
此外,我们也可以直接在Prometheus Web UI中的Status -> Configuration下查看scrape_config的方法。如下图所示:
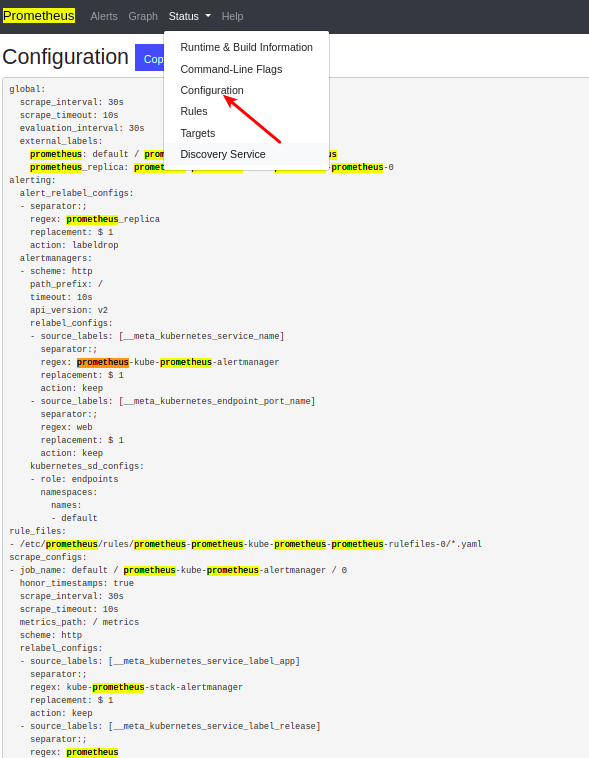
除了ServiceMonitor之外,我们也可以使用PodMonitor方法去抓取Kubernetes pod,并由Prometheus Operator处理定制的资源。PodMonitor能够以声明的方式,指定如何直接监控一组Pod。
您一定会问,既然我们有了ServiceMonitor,为何还需要PodMonitor呢?其主要原因是,ServiceMonitor合适那些Pod里已经有某个服务(Service)的场景。否则,您需要用到PodMonitor。通常,Prometheus可以被配置为如下两种方式,去定义待监控的目标端点。
- 使用static_config机制
如果待监控的Kubernetes服务/端点非常小且固定,那么您可以使用prometheus.yaml文件中的static_config来定义这些静态端点。示例链接展示了如何通过配置Prometheus,以默认使用static_configs来监控本身。
当然,这主要适用于简单的用例,而且需要在添加和删除节点时,手动更新prometheus.yml。而在Kubernetes之类的动态环境中,新的应用服务实例往往会出现得快而频繁。
- 使用service_discovery机制
目前,支持Prometheus的服务发现机制有:DNS、Kubernetes、AWS、Consul、以及其他自定义的类型。这些机制通常能够动态地发现待监控和抓取的目标端点。对于Kubernetes而言,它可以使用Kubernetes API来实现。示例链接展示了如何为Kubernetes配置Prometheus。其中,Prometheus Operator负责根据ServiceMonitor和PodMonitor资源完成上述配置。
Prometheus的规则
您可以创建一个包含规则语句的YAML文件,并使用Prometheus-configuration中的rule_files字段,将它们加载到Prometheus中。而在使用Prometheus Operator时,您可以使用PrometheusRule源的Helm,创建相应的规则。目前,Prometheus可以定期配置和评估如下两种类型的规则:
- 记录(Recording)规则
记录规则允许您预先计算出经常使用的PromQL表达式,并且需要相对大量的步骤,来实现表达式的结果。据此,在下一次运行相同的PromQL查询时,您可以直接从预先计算出的PromQL结果中获取到。这比反复执行相同的查询要快得多。例如:
- Go
- groups:
- - name: example
- rules:
- - record: job:http_inprogress_requests:sum
- expr: sum by (job) (http_inprogress_requests)
- 警报(Alerting)规则
警报规则允许您根据PromQL定义的警报条件,将有关触发警报的通知,发送到外部接收器上。只要警报表达式的结果为True时,就会发送警报。例如:
- Go
- groups:
- - name: example
- rules:
- - alert: HighRequestLatency
- expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
- for: 10m
- labels:
- severity: page
- annotations:
- summary: High request latency
警报和可视化
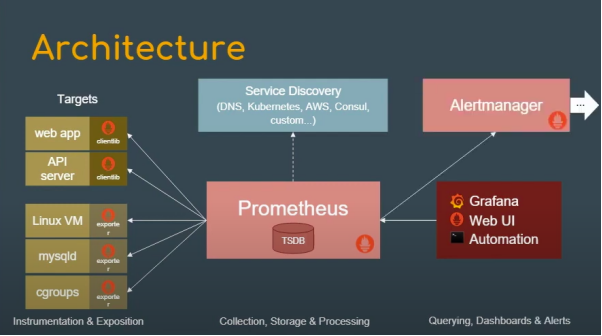
图片来源:Prometheus的介绍(https://www.youtube.com/watch?v=9GMWvFcQjYI&t=314s)
在配置了警报规则后,我们需要通过Alertmanager来添加警报摘要、控制、甚至将收到的通知“静音”。如上图所示,Alertmanager会定期从Prometheus服务器处接收有关警报状态的信息,以确保对已定义的接收者(如电子邮件、PagerDuty等)进行分组、数据去重、以及通知发送。
我们不必担心在何处、以及如何在Kubernetes集群中定义或设置Alertmanager。我们之前在Helm Chart的帮助下部署Prometheus Operator时,已经创建了一个作为StatefulSet的Alertmanager。请参见如下代码:
- Go
- kubectl get statefulsets.apps
- NAME READY AGE
- alertmanager-prometheus-prometheus-oper-alertmanager 1/1 8d
Alertmanager StatefulSet会在内部使用一个配置文件--alertmanager.yaml。我们可以将它放入alertmanagerpod中。请参见如下命令:
- Go
- /bin/alertmanager --config.file=/etc/alertmanager/config/alertmanager.yaml
alertmanager.yaml文件包含了如下关键元素:
- 路由:这是一个代码块,可用于定义将警报路由到下一个位置。
- 接收器:接收器是可用来发送或通知警报的网络钩子、邮件地址、以及PagerDuty之类的工具。
- 禁止规则:禁止规则部分可以在另一个警报因相同原因被触发时,使之“静音”。例如,对于那些已经处于critical级别的应用服务,即便再次出现故障,其警告通知也会被静音。
我们可以通过如下示例来查看Alertmanager的配置文件:
- Go
- global:
- resolve_timeout: 5m
- route:
- group_by: ['alertname']
- group_wait: 10s
- group_interval: 10s
- repeat_interval: 1h
- receiver: 'web.hook'
- receivers:
- - name: 'web.hook'
- webhook_configs:
- - url: 'http://127.0.0.1:5001/'
- inhibit_rules:
- - source_match:
- severity: 'critical'
- target_match:
- severity: 'warning'
- equal: ['alertname', 'dev', 'instance']
使用Grafana进行指标可视化
作为一种标准化工具,Grafana可以帮助您可视化那些在Prometheus的帮助下,收集到的所有指标。kube-Prometheus-stack的Helm Chart已经为我们部署了Grafana。我们可以通过如下命令,定位Grafana服务。
- Go
- kubectl get services
- NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
- prometheus-grafana ClusterIP 10.104.143.147 <none> 80/TCP
通过如下代码,我们可以将端口转发到此服务上,以便显示在Grafana的Web界面上。
- Go
- kubectl port-forward svc/prometheus-grafana 3000:80
- Forwarding from 127.0.0.1:3000 -> 3000
- Forwarding from [::1]:3000 -> 3000
如下图,您可以在浏览器中访问http://localhost:3000。
在输入了默认用户名:admin和密码:prom-operator后,您可以访问到Grafana仪表板,如下图所示。
依次点击Dashboard -> Manage,您将能够看到由kube-prometheus-stack提供的有关Kubernetes集群的所有仪表板:
您可以浏览到诸如“Kubernetes/Compute Resources/Pod”等仪表板信息:
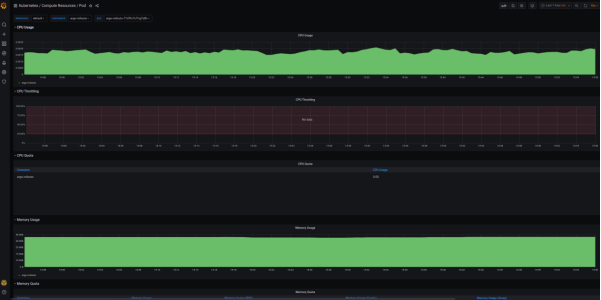
上面展示的标准化仪表板便是从kubernetes-mixin项目生成的。
小结
综上所述,我们讨论了Prometheus Operator是什么,如何在Prometheus Operator和Helm Chart的帮助下轻松地配置Prometheus,Prometheus如何发现带监控的资源,以及该如何配置Prometheus的各个组件与运作机制。此外,我们还探讨了如何设置警报,以及如何将它们可视化。
原文标题:Prometheus Definitive Guide: Prometheus Operator,作者:Ninad Desai
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】




















