把神经网络的限制视为无限多个残差层的组合,这种观点提供了一种将其输出隐式定义为常微分方程 ODE 的解的方法。连续深度参数化将模型的规范与其计算分离。虽然范式的复杂性增加了,但这种方法有几个好处:(1)通过指定自适应计算的容错,可以以细粒度的方式用计算成本换取精度;(2)通过及时运行动态 backward 来重建反向传播所需中间状态的激活函数,可以使训练的内存成本显著降低。
另一方面,对神经网络的贝叶斯处理改动了典型的训练 pipeline,不再执行点估计,而是推断参数的分布。虽然这种方法增加了复杂性,但它会自动考虑模型的不确定性——可以通过模型平均来对抗过拟合和改进模型校准,尤其是对于分布外数据。
近日,来自多伦多大学和斯坦福大学的一项研究表明贝叶斯连续深度神经网络的替代构造具有一些额外的好处,开发了一种在连续深度贝叶斯神经网络中进行近似推理的实用方法。该论文的一作是多伦多大学 Vector Institute 的本科学生 Winnie Xu,二作是 NeurIPS 2018 最佳论文的一作陈天琦,他们的导师 David Duvenaud 也是论文作者之一。
 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">- 论文地址:https://arxiv.org/pdf/2102.06559.pdf
- 项目地址:https://github.com/xwinxu/bayesian-sde
具体来说,该研究考虑了无限深度贝叶斯神经网络每层分别具有未知权重的限制,提出一类称为 SDE-BNN(SDE- Bayesian neural network )的模型。该研究表明,使用 Li 等人(2020)描述的基于可扩展梯度的变分推理方案可以有效地进行近似推理。
在这种方法中,输出层的状态由黑盒自适应随机微分方程(SDE 求解器计算,并训练模型以最大化变分下界。下图将这种神经 SDE 参数化与标准神经 ODE 方法进行了对比。这种方法保持了训练贝叶斯神经 ODE 的自适应计算和恒定内存成本。
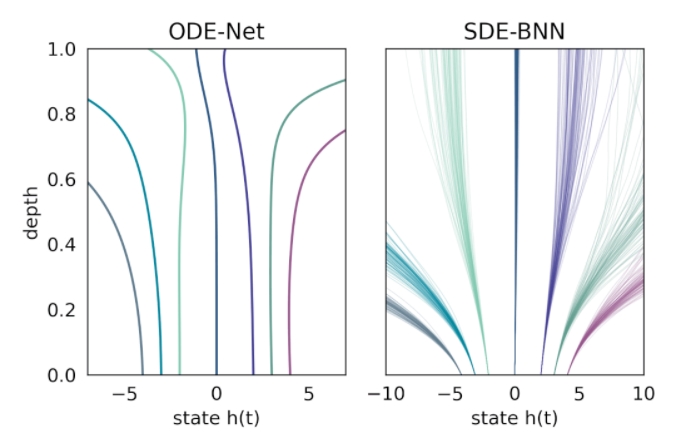
无限深度贝叶斯神经网络(BNN)
标准离散深度残差网络可以被定义为以下形式的层的组合:
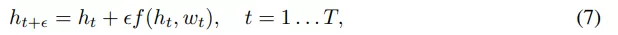 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">其中 t 是层索引,
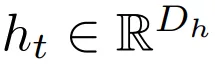 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">表示 t 层隐
藏单元激活向量,输入 h_0 = x,
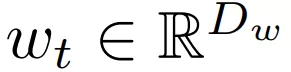 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">表示 t 层的参数,在离散设置中
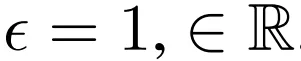 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">该研究通过设置
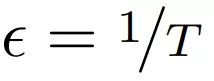 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">并将极限
设为
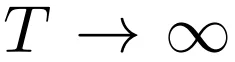 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">来构建残差网络的连续深度变体。 这样产生一个微分方程,该方程将隐藏单元进化描述为深度 t 的函数。 由于标准残差网络每层使用不同的权重进行参数化,因此该研究用 w_t 表示第 t 层的权重。此外该研究还引入一个超网络(hypernetwork) f_w,它将权重的变化指定为深度和当前权重的函数。然后将隐藏单元激活函数的进化和权重组合成一个微分方程:
 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">权重先验过程:该研究使用 Ornstein-Uhlenbeck (OU) 过程作为权重先验,该过程的特点是具有漂移(drift)和弥散(diffusion)的 SDE:
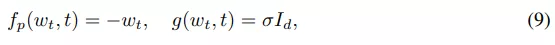 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">权重近似后验使用另一个具有以下漂移函数的 SDE 隐式地进行参数化:
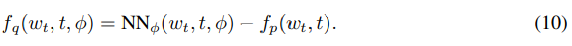 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">然后该研究在给定输入下评估了该网络需要边缘化权重和隐藏单元轨迹(trajectory)。这可以通过简单的蒙特卡罗方法来完成,从后验过程中采样权重路径 {w_t},并在给定采样权重和输入的情况下评估网络激活函数 {h_t}。这两个步骤都需要求解一个微分方程,两步可以通过调用增强状态 SDE 的单个 SDE 求解器同时完成:
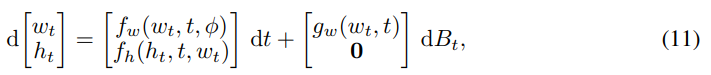 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">为了让网络拟合数据,该研究最大化由无限维 ELBO 给出的边缘似然(marginal likelihood)的下限:
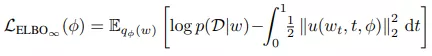 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">采样权重、隐藏激活函数和训练目标都是通过一次调用自适应 SDE 求解器同时计算的。
减小方差的梯度估计
该研究使用 STL(sticking the landing) 估计器来替换 path 空间 KL 中的原始估计器以适应 SDE 设置:
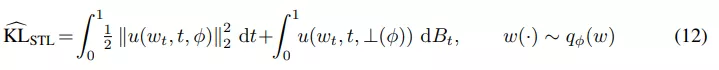 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">等式 (12) 中的第二项是鞅(martingale),期望值为零。在之前的工作中,研究者仅对第一项进行了蒙特卡罗估计,但该研究发现这种方法不一定会减少梯度的方差,如下图 4 所示。
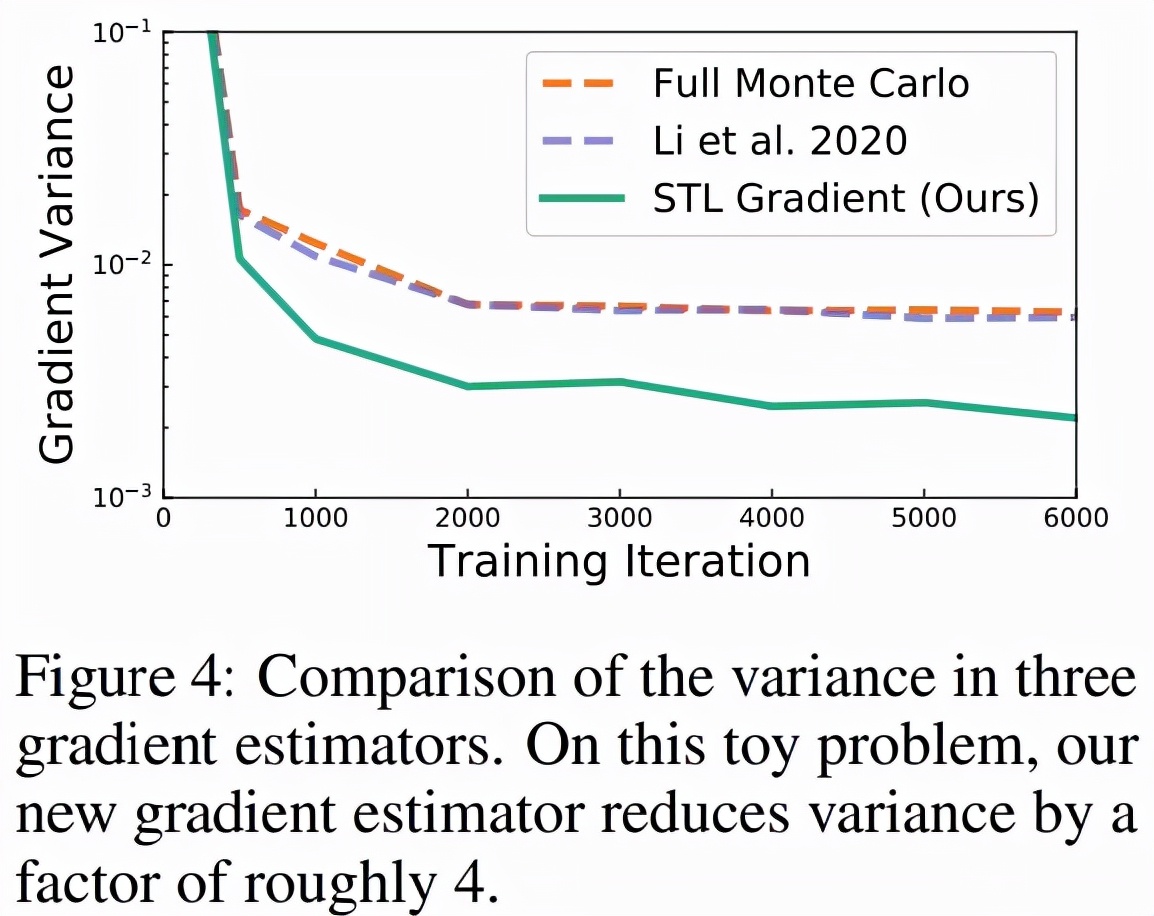 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">因为该研究提出的近似后验可以任意表达,研究者推测如果参数化网络 f_w 的表达能力足够强,该方法可在训练结束时实现任意低的梯度方差。
图 4 显示了多个梯度估计器的方差,该研究将 STL 与「完全蒙特卡罗(Full Monte Carlo)」估计进行了比较。图 4 显示,当匹配指数布朗运动时,STL 获得的方差比其他方案低。下表 4 显示了训练性能的改进。
 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">实验
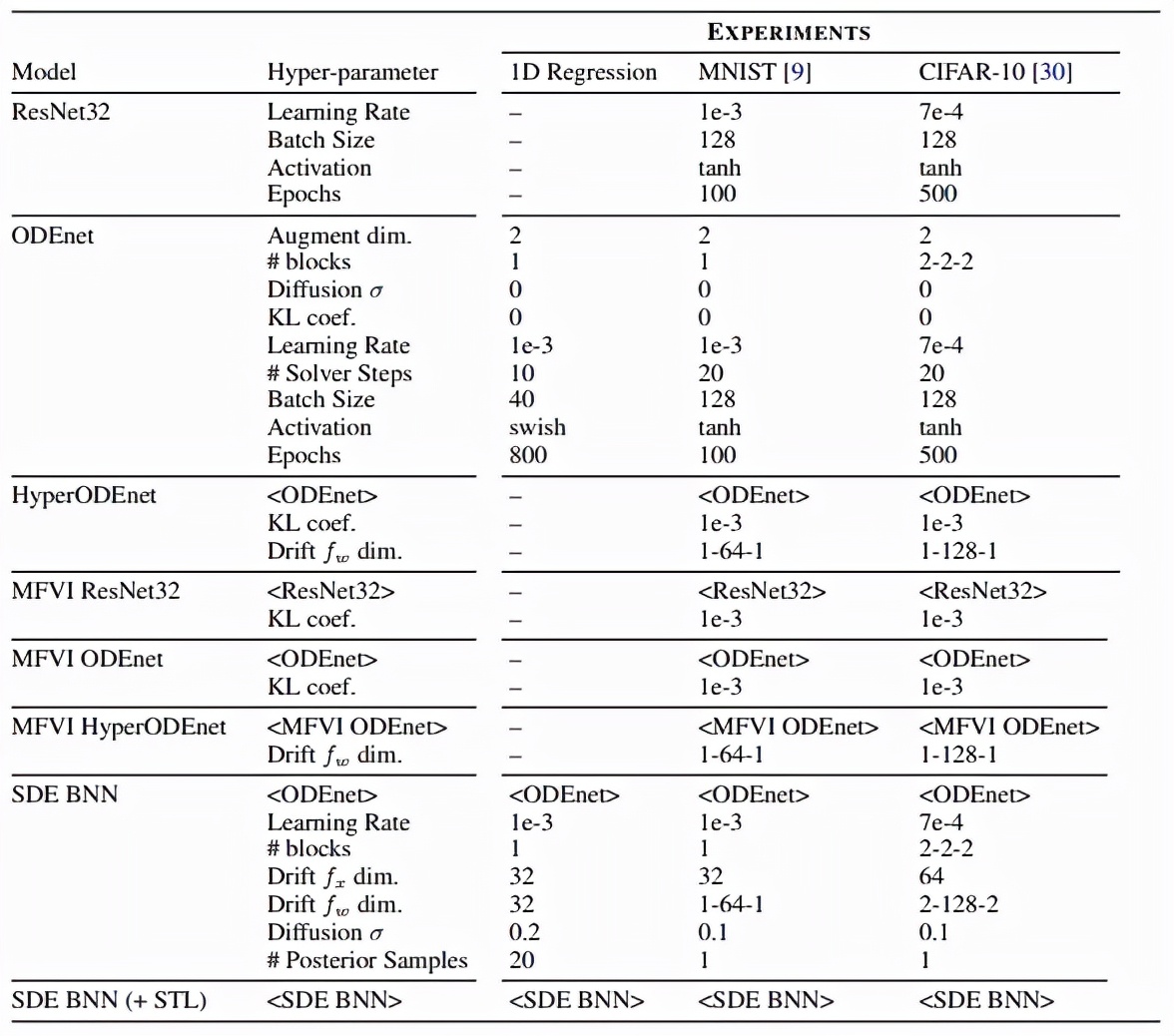
该研究的实验设置如下表所示,该研究在 MNIST 和 CIFAR-10 上进行了 toy 回归、图像分类任务,此外他们还研究了分布外泛化任务:
 无限深度贝叶斯神经网络">
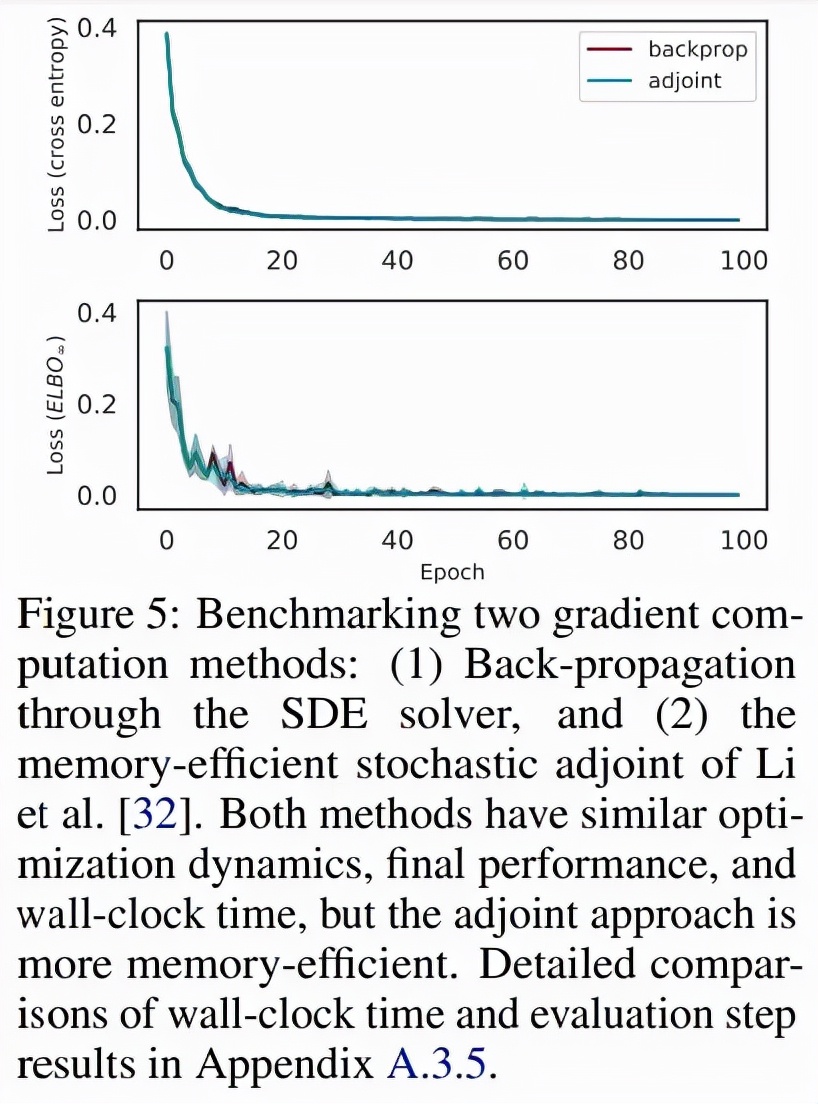
无限深度贝叶斯神经网络">为了对比求解器与 adjoint 的反向传播,研究者比较了固定和自适应步长的 SDE 求解器,并比较了 Li 等人提出的随机 adjoint 之间的比较, 图 5 显示了这两种方法具有相似的收敛性:
 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">1D 回归
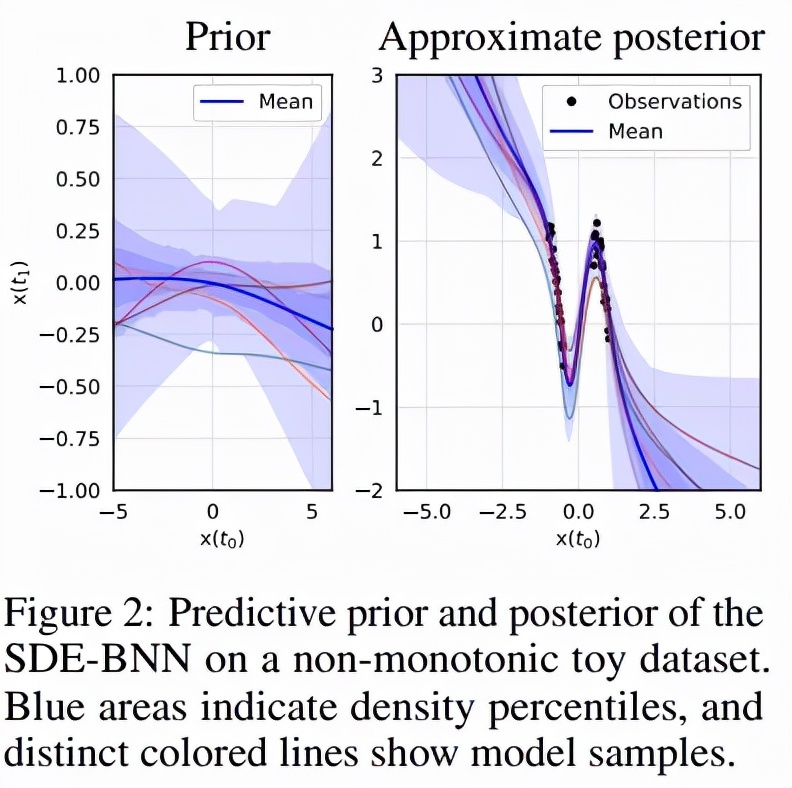
该研究首先验证了 SDE-BNN 在 1D 回归问题上的表现。以弥散过程的样本为条件,来自 1D SDE-BNN 的每个样本都是从输入到输出的双向映射。这意味着从 1D SDE-BNN 采样的每个函数都是单调的。为了能够对非单调函数进行采样,该研究使用初始化为零的 2 个额外维度来增加状态。图 2 显示了模型在合成的非单调 1D 数据集上学习了相当灵活的近似后验。
 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">图像分类
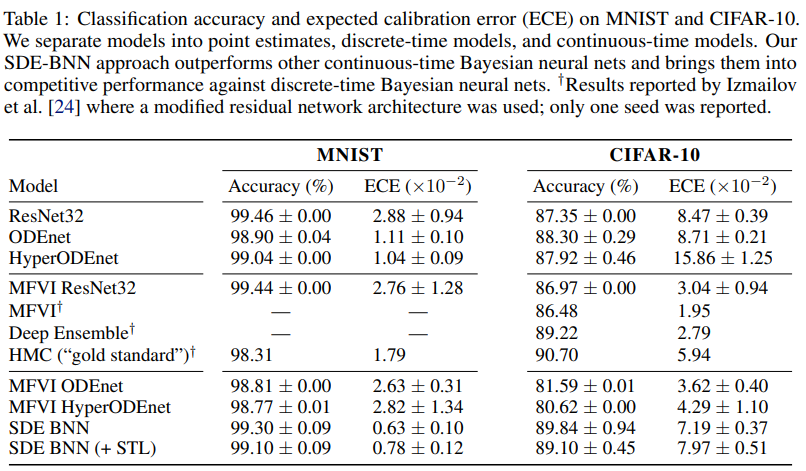
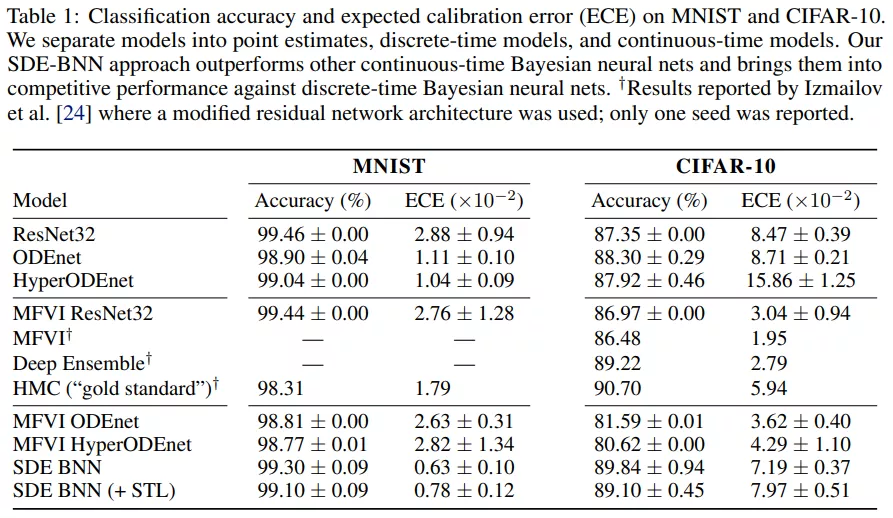
表 1 给出了图像分类实验的结果。SDE-BNN 通常优于基线,由结果可得虽然连续深度神经 ODE (ODEnet) 模型可以在标准残差网络上实现类似的分类性能,但校准(calibration)较差。
 无限深度贝叶斯神经网络">
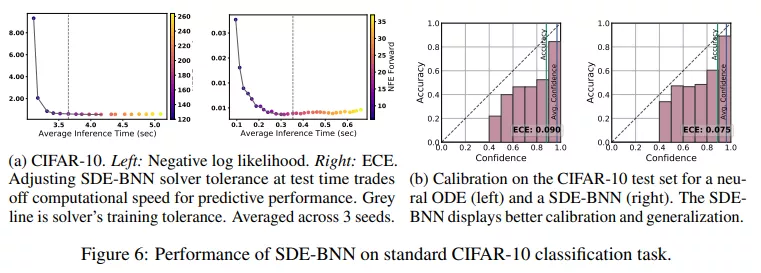
无限深度贝叶斯神经网络">图 6a 展示了 SDE-BNN 的性能,图 6b 显示具有相似准确率但比神经 ODE 校准更好的结果。
 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">表 1 用预期校准误差量化了模型的校准。SDE-BNN 似乎比神经 ODE 和平均场 ResNet 基线能更好地校准。
 无限深度贝叶斯神经网络">
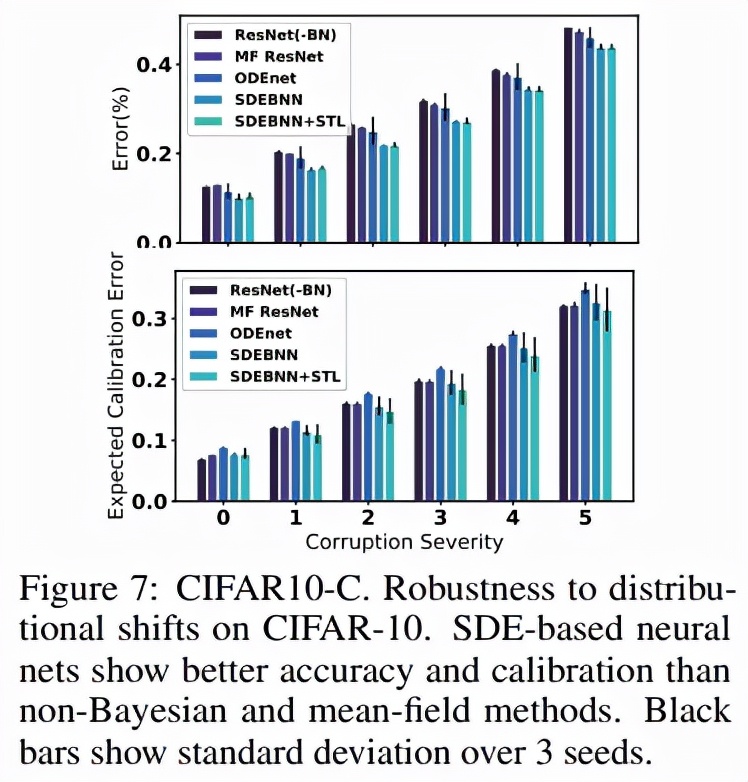
无限深度贝叶斯神经网络">下图 7 显示了损坏测试集上相对于未损坏数据的误差,表明随着扰动严重性级别的增加以及表 1 中总结的总体误差度量,mCE 稳步增加。在 CIFAR10 和 CIFAR10-C 上,SDE-BNN 和 SDE -BNN + STL 模型实现了比基线更低的整体测试误差和更好的校准。
 无限深度贝叶斯神经网络">
无限深度贝叶斯神经网络">与标准基线(ResNet32 和 MF ResNet32)相比,SDE-BNN 的绝对损坏误差(CE)降低了约 4.4%。域外输入的学习不确定性的有效性表明,尽管没有在多种形式的损坏上进行训练,但 SDE-BNN 对观测扰动也更加稳健。