数据库故障恢复机制的前世今生一文中提到,今生磁盘数据库为了在保证数据库的原子性(A, Atomic) 和持久性(D, Durability)的同时,还能以灵活的刷盘策略来充分利用磁盘顺序写的性能,会记录REDO和UNDO日志,即ARIES方法。本文将重点介绍REDO LOG的作用,记录的内容,组织结构,写入方式等内容,希望读者能够更全面准确的理解REDO LOG在InnoDB中的位置。本文基于MySQL 8.0代码。
一、为什么需要记录REDO
为了取得更好的读写性能,InnoDB会将数据缓存在内存中(InnoDB Buffer Pool),对磁盘数据的修改也会落后于内存,这时如果进程或机器崩溃,会导致内存数据丢失,为了保证数据库本身的一致性和持久性,InnoDB维护了REDO LOG。修改Page之前需要先将修改的内容记录到REDO中,并保证REDO LOG早于对应的Page落盘,也就是常说的WAL,Write Ahead Log。当故障发生导致内存数据丢失后,InnoDB会在重启时,通过重放REDO,将Page恢复到崩溃前的状态。
二、需要什么样的REDO
那么我们需要什么样的REDO呢?首先,REDO的维护增加了一份写盘数据,同时为了保证数据正确,事务只有在他的REDO全部落盘才能返回用户成功,REDO的写盘时间会直接影响系统吞吐,显而易见,REDO的数据量要尽量少。其次,系统崩溃总是发生在始料未及的时候,当重启重放REDO时,系统并不知道哪些REDO对应的Page已经落盘,因此REDO的重放必须可重入,即REDO操作要保证幂等。最后,为了便于通过并发重放的方式加快重启恢复速度,REDO应该是基于Page的,即一个REDO只涉及一个Page的修改。
熟悉的读者会发现,数据量小是Logical Logging的优点,而幂等以及基于Page正是Physical Logging的优点,因此InnoDB采取了一种称为Physiological Logging的方式,来兼得二者的优势。所谓Physiological Logging,就是以Page为单位,但在Page内以逻辑的方式记录。举个例子,MLOG_REC_UPDATE_IN_PLACE类型的REDO中记录了对Page中一个Record的修改,方法如下:
- (Page ID,Record Offset,(Filed 1, Value 1) ... (Filed i, Value i) ... )
其中,PageID指定要操作的Page页,Record Offset记录了Record在Page内的偏移位置,后面的Field数组,记录了需要修改的Field以及修改后的Value。
由于Physiological Logging的方式采用了物理Page中的逻辑记法,导致两个问题:
1、需要基于正确的Page状态上重放REDO
由于在一个Page内,REDO是以逻辑的方式记录了前后两次的修改,因此重放REDO必须基于正确的Page状态。然而InnoDB默认的Page大小是16KB,是大于文件系统能保证原子的4KB大小的,因此可能出现Page内容成功一半的情况。InnoDB中采用了Double Write Buffer的方式来通过写两次的方式保证恢复的时候找到一个正确的Page状态。这部分会在之后介绍Buffer Pool的时候详细介绍。
2、需要保证REDO重放的幂等
Double Write Buffer能够保证找到一个正确的Page状态,我们还需要知道这个状态对应REDO上的哪个记录,来避免对Page的重复修改。为此,InnoDB给每个REDO记录一个全局唯一递增的标号LSN(Log Sequence Number)。Page在修改时,会将对应的REDO记录的LSN记录在Page上(FIL_PAGE_LSN字段),这样恢复重放REDO时,就可以来判断跳过已经应用的REDO,从而实现重放的幂等。
三、REDO中记录了什么内容
知道了InnoDB中记录REDO的方式,那么REDO里具体会记录哪些内容呢?为了应对InnoDB各种各样不同的需求,到MySQL 8.0为止,已经有多达65种的REDO记录。用来记录这不同的信息,恢复时需要判断不同的REDO类型,来做对应的解析。根据REDO记录不同的作用对象,可以将这65中REDO划分为三个大类:作用于Page,作用于Space以及提供额外信息的Logic类型。
1、作用于Page的REDO
这类REDO占所有REDO类型的绝大多数,根据作用的Page的不同类型又可以细分为,Index Page REDO,Undo Page REDO,Rtree PageREDO等。比如MLOG_REC_INSERT,MLOG_REC_UPDATE_IN_PLACE,MLOG_REC_DELETE三种类型分别对应于Page中记录的插入,修改以及删除。这里还是以MLOG_REC_UPDATE_IN_PLACE为例来看看其中具体的内容:
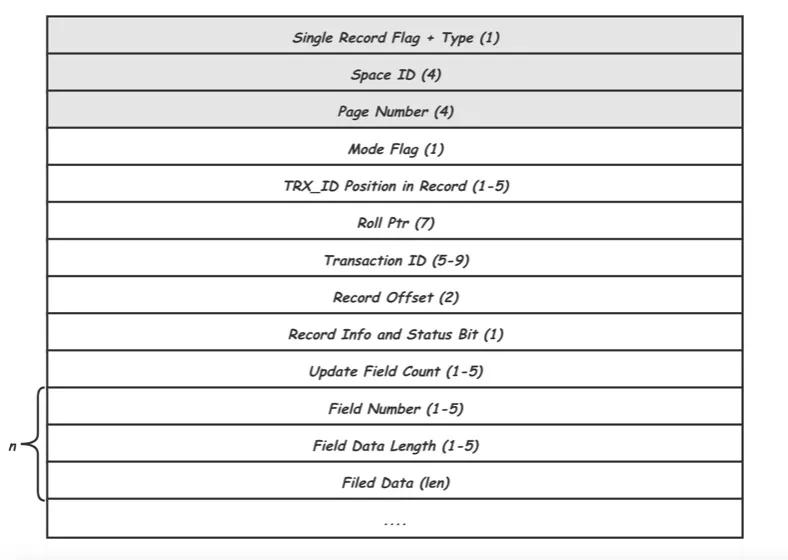
其中,Type就是MLOG_REC_UPDATE_IN_PLACE类型,Space ID和Page Number唯一标识一个Page页,这三项是所有REDO记录都需要有的头信息,后面的是MLOG_REC_UPDATE_IN_PLACE类型独有的,其中Record Offset用给出要修改的记录在Page中的位置偏移,Update Field Count说明记录里有几个Field要修改,紧接着对每个Field给出了Field编号(Field Number),数据长度(Field Data Length)以及数据(Filed Data)。
2、作用于Space的REDO
这类REDO针对一个Space文件的修改,如MLOG_FILE_CREATE,MLOG_FILE_DELETE,MLOG_FILE_RENAME分别对应对一个Space的创建,删除以及重命名。由于文件操作的REDO是在文件操作结束后才记录的,因此在恢复的过程中看到这类日志时,说明文件操作已经成功,因此在恢复过程中大多只是做对文件状态的检查,以MLOG_FILE_CREATE来看看其中记录的内容:

同样的前三个字段还是Type,Space ID和Page Number,由于是针对Page的操作,这里的Page Number永远是0。在此之后记录了创建的文件flag以及文件名,用作重启恢复时的检查。
3、提供额外信息的Logic REDO
除了上述类型外,还有少数的几个REDO类型不涉及具体的数据修改,只是为了记录一些需要的信息,比如最常见的MLOG_MULTI_REC_END就是为了标识一个REDO组,也就是一个完整的原子操作的结束。
4、REDO是如何组织的
所谓REDO的组织方式,就是如何把需要的REDO内容记录到磁盘文件中,以方便高效的REDO写入,读取,恢复以及清理。我们这里把REDO从上到下分为三层:逻辑REDO层、物理REDO层和文件层。
1) 逻辑REDO层
这一层是真正的REDO内容,REDO由多个不同Type的多个REDO记录收尾相连组成,有全局唯一的递增的偏移sn,InnoDB会在全局log_sys中维护当前sn的最大值,并在每次写入数据时将sn增加REDO内容长度。如下图所示:

2 )物理REDO层
磁盘是块设备,InnoDB中也用Block的概念来读写数据,一个Block的长度OS_FILE_LOG_BLOCK_SIZE等于磁盘扇区的大小512B,每次IO读写的最小单位都是一个Block。除了REDO数据以外,Block中还需要一些额外的信息,下图所示一个Log Block的的组成,包括12字节的Block Header:前4字节中Flush Flag占用最高位bit,标识一次IO的第一个Block,剩下的31个个bit是Block编号;之后是2字节的数据长度,取值在[12,508];紧接着2字节的First Record Offset用来指向Block中第一个REDO组的开始,这个值的存在使得我们对任何一个Block都可以找到一个合法的的REDO开始位置;最后的4字节Checkpoint Number记录写Block时的next_checkpoint_number,用来发现文件的循环使用,这个会在文件层详细讲解。Block末尾是4字节的Block Tailer,记录当前Block的Checksum,通过这个值,读取Log时可以明确Block数据有没有被完整写完。

Block中剩余的中间498个字节就是REDO真正内容的存放位置,也就是我们上面说的逻辑REDO。我们现在将逻辑REDO放到物理REDO空间中,由于Block内的空间固定,而REDO长度不定,因此可能一个Block中有多个REDO,也可能一个REDO被拆分到多个Block中,如下图所示,棕色和红色分别代表Block Header和Tailer,中间的REDO记录由于前一个Block剩余空间不足,而被拆分在连续的两个Block中。
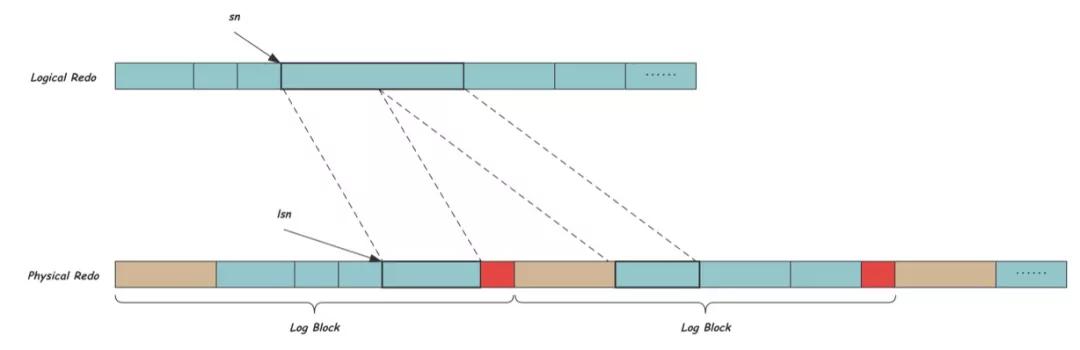
由于增加了Block Header和Tailer的字节开销,在物理REDO空间中用LSN来标识偏移,可以看出LSN和SN之间有简单的换算关系:
- constexpr inline lsn_t log_translate_sn_to_lsn(lsn_t sn) {
- return (sn / LOG_BLOCK_DATA_SIZE * OS_FILE_LOG_BLOCK_SIZE +
- sn % LOG_BLOCK_DATA_SIZE + LOG_BLOCK_HDR_SIZE);
- }
SN加上之前所有的Block的Header以及Tailer的长度就可以换算到对应的LSN,反之亦然。
3) 文件层
最终REDO会被写入到REDO日志文件中,以ib_logfile0、ib_logfile1...命名,为了避免创建文件及初始化空间带来的开销,InooDB的REDO文件会循环使用,通过参数innodb_log_files_in_group可以指定REDO文件的个数。多个文件收尾相连顺序写入REDO内容。每个文件以Block为单位划分,每个文件的开头固定预留4个Block来记录一些额外的信息,其中第一个Block称为Header Block,之后的3个Block在0号文件上用来存储Checkpoint信息,而在其他文件上留空:
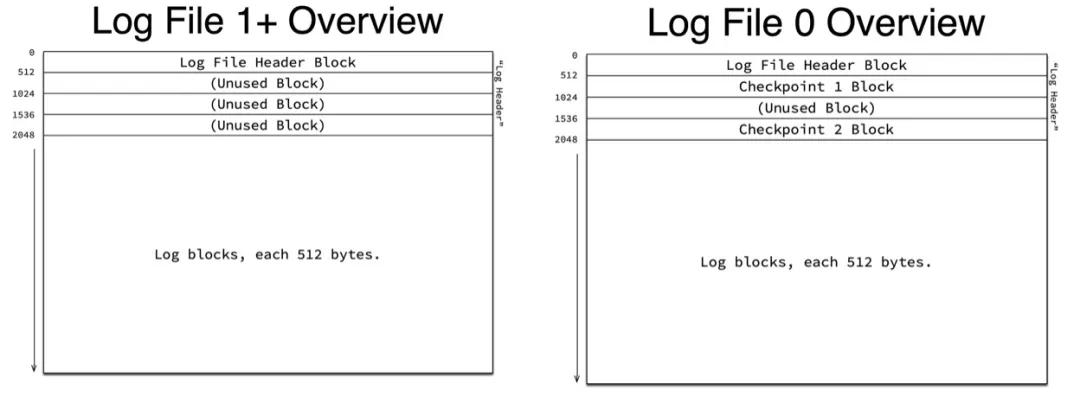
其中第一个Header Block的数据区域记录了一些文件信息,如下图所示,4字节的Formate字段记录Log的版本,不同版本的LOG,会有REDO类型的增减,这个信息是8.0开始才加入的;8字节的Start LSN标识当前文件开始LSN,通过这个信息可以将文件的offset与对应的lsn对应起来;最后是最长32位的Creator信息,正常情况下会记录MySQL的版本。

现在我们将REDO放到文件空间中,如下图所示,逻辑REDO是真正需要的数据,用sn索引,逻辑REDO按固定大小的Block组织,并添加Block的头尾信息形成物理REDO,以lsn索引,这些Block又会放到循环使用的文件空间中的某一位置,文件中用offset索引:
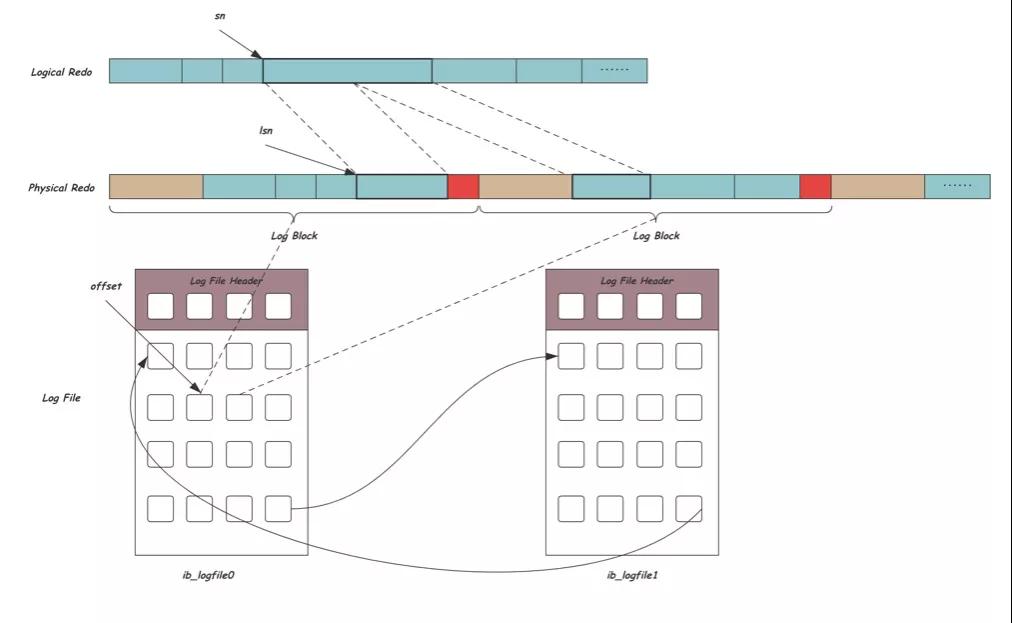
虽然通过LSN可以唯一标识一个REDO位置,但最终对REDO的读写还需要转换到对文件的读写IO,这个时候就需要表示文件空间的offset,他们之间的换算方式如下:
- const auto real_offset =
- log.current_file_real_offset + (lsn - log.current_file_lsn);
切换文件时会在内存中更新当前文件开头的文件offset,current_file_real_offset,以及对应的LSN,current_file_lsn,通过这两个值可以方便地用上面的方式将LSN转化为文件offset。注意这里的offset是相当于整个REDO文件空间而言的,由于InnoDB中读写文件的space层实现支持多个文件,因此,可以将首位相连的多个REDO文件看成一个大文件,那么这里的offset就是这个大文件中的偏移。
五、如何高效地写REDO
作为维护数据库正确性的重要信息,REDO日志必须在事务提交前保证落盘,否则一旦断电将会有数据丢失的可能,因此从REDO生成到最终落盘的完整过程成为数据库写入的关键路径,其效率也直接决定了数据库的写入性能。这个过程包括REDO内容的产生,REDO写入InnoDB Log Buffer,从InnoDB Log Buffer写入操作系统Page Cache,以及REDO刷盘,之后还需要唤醒等待的用户线程完成Commit。下面就通过这几个阶段来看看InnoDB如何在高并发的情况下还能高效地完成写REDO。
1、REDO产生
我们知道事务在写入数据的时候会产生REDO,一次原子的操作可能会包含多条REDO记录,这些REDO可能是访问同一Page的不同位置,也可能是访问不同的Page(如Btree节点分裂)。InnoDB有一套完整的机制来保证涉及一次原子操作的多条REDO记录原子,即恢复的时候要么全部重放,要不全部不重放,这部分将在之后介绍恢复逻辑的时候详细介绍,本文只涉及其中最基本的要求,就是这些REDO必须连续。InnoDB中通过min-transaction实现,简称mtr,需要原子操作时,调用mtr_start生成一个mtr,mtr中会维护一个动态增长的m_log,这是一个动态分配的内存空间,将这个原子操作需要写的所有REDO先写到这个m_log中,当原子操作结束后,调用mtr_commit将m_log中的数据拷贝到InnoDB的Log Buffer。
2、写入InnoDB Log Buffer
高并发的环境中,会同时有非常多的min-transaction(mtr)需要拷贝数据到Log Buffer,如果通过锁互斥,那么毫无疑问这里将成为明显的性能瓶颈。为此,从MySQL 8.0开始,设计了一套无锁的写log机制,其核心思路是允许不同的mtr,同时并发地写Log Buffer的不同位置。不同的mtr会首先调用log_buffer_reserve函数,这个函数里会用自己的REDO长度,原子地对全局偏移log.sn做fetch_add,得到自己在Log Buffer中独享的空间。之后不同mtr并行的将自己的m_log中的数据拷贝到各自独享的空间内。
- /* Reserve space in sequence of data bytes: */
- const sn_t start_sn = log.sn.fetch_add(len);
3、写入Page Cache
写入到Log Buffer中的REDO数据需要进一步写入操作系统的Page Cache,InnoDB中有单独的log_writer来做这件事情。这里有个问题,由于Log Buffer中的数据是不同mtr并发写入的,这个过程中Log Buffer中是有空洞的,因此log_writer需要感知当前Log Buffer中连续日志的末尾,将连续日志通过pwrite系统调用写入操作系统Page Cache。整个过程中应尽可能不影响后续mtr进行数据拷贝,InnoDB在这里引入一个叫做link_buf的数据结构,如下图所示:
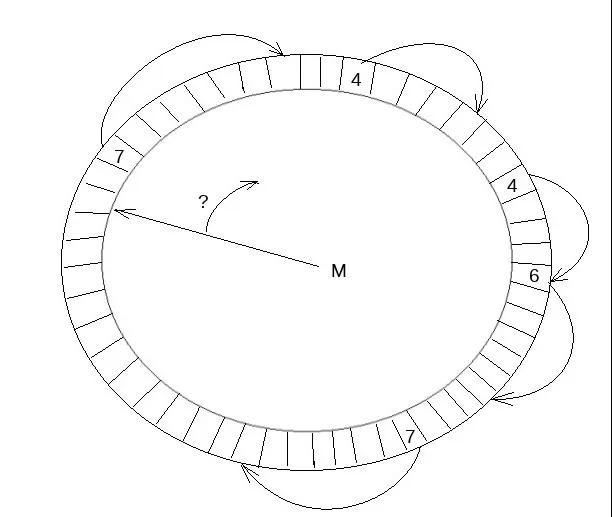
link_buf是一个循环使用的数组,对每个lsn取模可以得到其在link_buf上的一个槽位,在这个槽位中记录REDO长度。另外一个线程从开始遍历这个link_buf,通过槽位中的长度可以找到这条REDO的结尾位置,一直遍历到下一位置为0的位置,可以认为之后的REDO有空洞,而之前已经连续,这个位置叫做link_buf的tail。下面看看log_writer和众多mtr是如何利用这个link_buf数据结构的。这里的这个link_buf为log.recent_written,如下图所示:
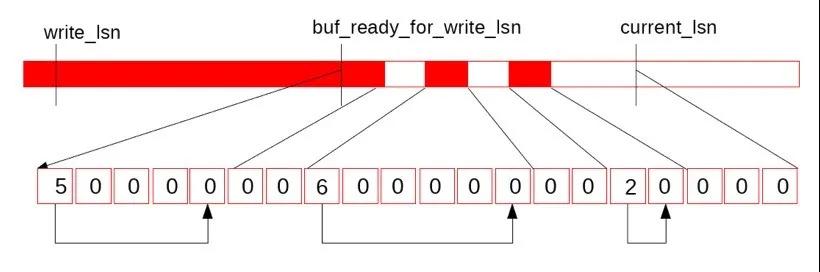
图中上半部分是REDO日志示意图,write_lsn是当前log_writer已经写入到Page Cache中日志末尾,current_lsn是当前已经分配给mtr的的最大lsn位置,而buf_ready_for_write_lsn是当前log_writer找到的Log Buffer中已经连续的日志结尾,从write_lsn到buf_ready_for_write_lsn是下一次log_writer可以连续调用pwrite写入Page Cache的范围,而从buf_ready_for_write_lsn到current_lsn是当前mtr正在并发写Log Buffer的范围。下面的连续方格便是log.recent_written的数据结构,可以看出由于中间的两个全零的空洞导致buf_ready_for_write_lsn无法继续推进,接下来,假如reserve到中间第一个空洞的mtr也完成了写Log Buffer,并更新了log.recent_written*,如下图:
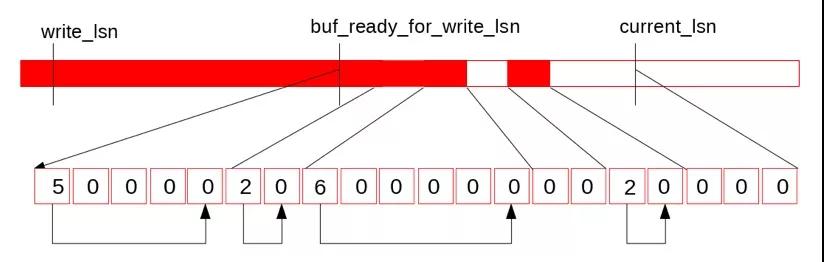
这时,log_writer从当前的buf_ready_for_write_lsn向后遍历log.recent_written,发现这段已经连续:
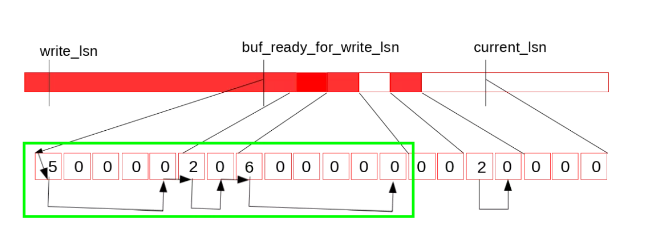
因此提升当前的buf_ready_for_write_lsn,并将log.recent_written的tail位置向前滑动,之后的位置清零,供之后循环复用:
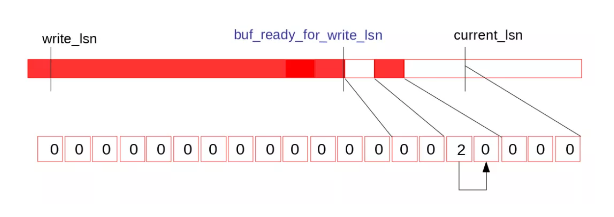
紧接log_writer将连续的内容刷盘并提升write_lsn。
4、刷盘
log_writer提升write_lsn之后会通知log_flusher线程,log_flusher线程会调用fsync将REDO刷盘,至此完成了REDO完整的写入过程。
5、唤醒用户线程
为了保证数据正确,只有REDO写完后事务才可以commit,因此在REDO写入的过程中,大量的用户线程会block等待,直到自己的最后一条日志结束写入。默认情况下innodb_flush_log_at_trx_commit = 1,需要等REDO完成刷盘,这也是最安全的方式。当然,也可以通过设置innodb_flush_log_at_trx_commit = 2,这样,只要REDO写入Page Cache就认为完成了写入,极端情况下,掉电可能导致数据丢失。
大量的用户线程调用log_write_up_to等待在自己的lsn位置,为了避免大量无效的唤醒,InnoDB将阻塞的条件变量拆分为多个,log_write_up_to根据自己需要等待的lsn所在的block取模对应到不同的条件变量上去。同时,为了避免大量的唤醒工作影响log_writer或log_flusher线程,InnoDB中引入了两个专门负责唤醒用户的线程:log_wirte_notifier和log_flush_notifier,当超过一个条件变量需要被唤醒时,log_writer和log_flusher会通知这两个线程完成唤醒工作。下图是整个过程的示意图:
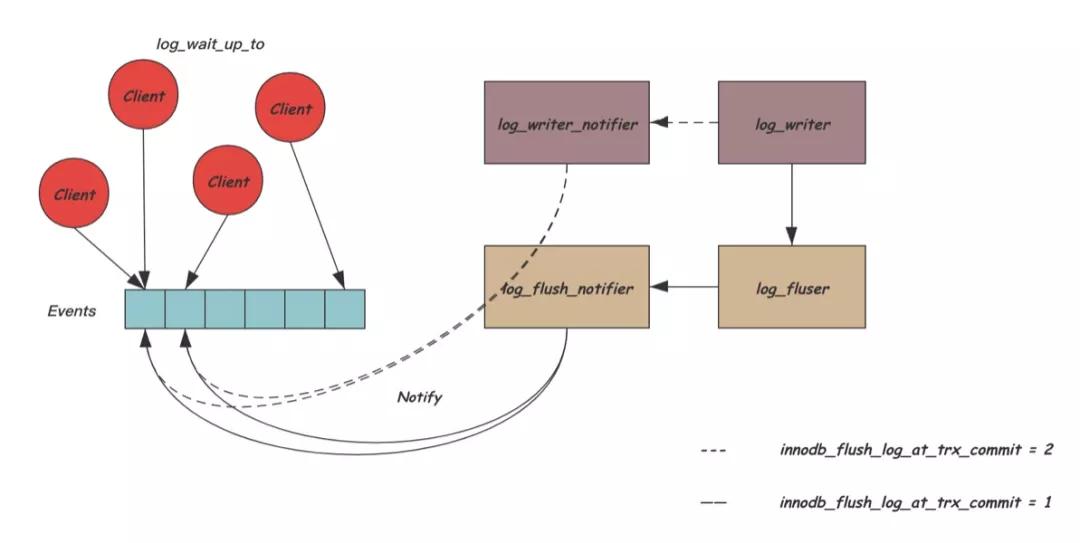
多个线程通过一些内部数据结构的辅助,完成了高效的从REDO产生,到REDO写盘,再到唤醒用户线程的流程,下面是整个这个过程的时序图:
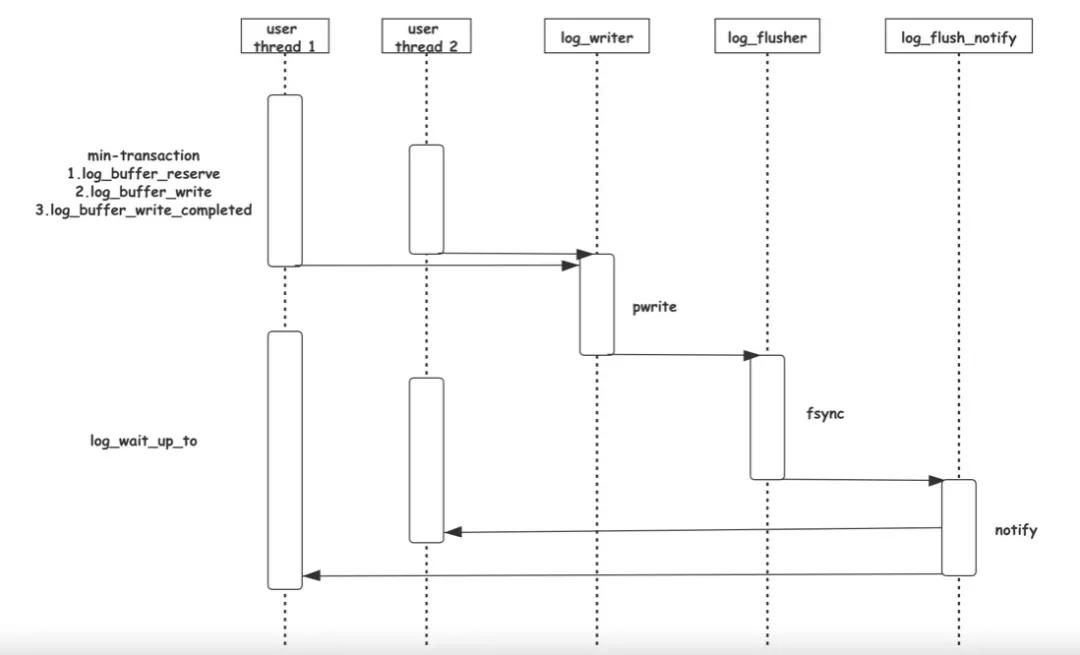
六、如何安全地清除REDO
由于REDO文件空间有限,同时为了尽量减少恢复时需要重放的REDO,InnoDB引入log_checkpointer线程周期性的打Checkpoint。重启恢复的时候,只需要从最新的Checkpoint开始回放后边的REDO,因此Checkpoint之前的REDO就可以删除或被复用。
我们知道REDO的作用是避免只写了内存的数据由于故障丢失,那么打Checkpiont的位置就必须保证之前所有REDO所产生的内存脏页都已经刷盘。最直接的,可以从Buffer Pool中获得当前所有脏页对应的最小REDO LSN:lwm_lsn。但光有这个还不够,因为有一部分min-transaction的REDO对应的Page还没有来的及加入到Buffer Pool的脏页中去,如果checkpoint打到这些REDO的后边,一旦这时发生故障恢复,这部分数据将丢失,因此还需要知道当前已经加入到Buffer Pool的REDO lsn位置:dpa_lsn。取二者的较小值作为最终checkpoint的位置,其核心逻辑如下:
- /* LWM lsn for unflushed dirty pages in Buffer Pool */
- lsn_t lwm_lsn = buf_pool_get_oldest_modification_lwm();
- /* Note lsn up to which all dirty pages have already been added into Buffer Pool */
- const lsn_t dpa_lsn = log_buffer_dirty_pages_added_up_to_lsn(log);
- lsn_t checkpoint_lsn = std::min(lwm_lsn, dpa_lsn);
MySQL 8.0中为了能够让mtr之间更大程度的并发,允许并发地给Buffer Pool注册脏页。类似与log.recent_written和log_writer,这里引入一个叫做recent_closed的link_buf来处理并发带来的空洞,由单独的线程log_closer来提升recent_closed的tail,也就是当前连续加入Buffer Pool脏页的最大LSN,这个值也就是上面提到的dpa_lsn。需要注意的是,由于这种乱序的存在,lwm_lsn的值并不能简单的获取当前Buffer Pool中的最老的脏页的LSN,保守起见,还需要减掉一个recent_closed的容量大小,也就是最大的乱序范围,简化后的代码如下:
- /* LWM lsn for unflushed dirty pages in Buffer Pool */
- const lsn_t lsn = buf_pool_get_oldest_modification_approx();
- const lsn_t lag = log.recent_closed.capacity();
- lsn_t lwm_lsn = lsn - lag;
- /* Note lsn up to which all dirty pages have already been added into Buffer Pool */
- const lsn_t dpa_lsn = log_buffer_dirty_pages_added_up_to_lsn(log);
- lsn_t checkpoint_lsn = std::min(lwm_lsn, dpa_lsn);
这里有一个问题,由于lwm_lsn已经减去了recent_closed的capacity,因此理论上这个值一定是小于dpa_lsn的。那么再去比较lwm_lsn和dpa_lsn来获取Checkpoint位置或许是没有意义的。
上面已经提到,ib_logfile0文件的前三个Block有两个被预留作为Checkpoint Block,这两个Block会在打Checkpiont的时候交替使用,这样来避免写Checkpoint过程中的崩溃导致没有可用的Checkpoint。Checkpoint Block中的内容如下:

首先8个字节的Checkpoint Number,通过比较这个值可以判断哪个是最新的Checkpiont记录,之后8字节的Checkpoint LSN为打Checkpoint的REDO位置,恢复时会从这个位置开始重放后边的REDO。之后8个字节的Checkpoint Offset,将Checkpoint LSN与文件空间的偏移对应起来。最后8字节是前面提到的Log Buffer的长度,这个值目前在恢复过程并没有使用。
七、总结
本文系统的介绍了InnoDB中REDO的作用、特性、组织结构、写入方式已经清理时机,基本覆盖了REDO的大多数内容。关于重启恢复时如何使用REDO将数据库恢复到正确的状态,将在之后介绍InnoDB故障恢复机制的时候详细介绍。
参考
[1] MySQL 8.0.11Source Code Documentation: Format of redo log
https://dev.mysql.com/doc/dev/mysql-server/8.0.11/PAGE_INNODB_REDO_LOG_FORMAT.html?spm=ata.21736010.0.0.600e6f95JcmTlA
[2] MySQL 8.0: New Lock free, scalable WAL design
https://mysqlserverteam.com/mysql-8-0-new-lock-free-scalable-wal-design/?spm=ata.21736010.0.0.600e6f95JcmTlA
[3] How InnoDB handles REDO logging
https://www.percona.com/blog/2011/02/03/how-innodb-handles-redo-logging/?spm=ata.21736010.0.0.600e6f95JcmTlA
[4] MySQL Source Code
https://github.com/mysql/mysql-server?spm=ata.21736010.0.0.600e6f95JcmTlA
[5] 数据库故障恢复机制的前世今生
http://catkang.github.io/2019/01/16/crash-recovery.html?spm=ata.21736010.0.0.600e6f95JcmTlA