Hash表回顾
哈希表是一种存储数据的结构,他有很多名字(键值对、字典、符号表、映射、关联数组)。在哈希表中,键和值是一一对应的关系,一个键key对应一个值value。哈希表这个数据结构可以通过键key,在O(1)时间复杂度的情况下获得对应的值。
由于C语言自己没有内置哈希表这一数据结构,因此Redis自己实现了Hash表。
哈希冲突及处理办法
哈希表最关键的问题就在于哈希冲突。即,两个项,经过哈希函数计算,发现其对应的存储方式位置一致。对于这种情况,就需要进行进一步处理了。
解决哈希冲突的办法
大家应该背过我写的数据结构与算法八股文背诵版,还记得解决Hash冲突的方法嘛。
线性探查法(开放地址)。
这个方法的核心是:一旦碰见有冲突,该项往后顺延.
来看个例子吧。
1.按hash算法,新键值对应该存在箭头所处位置,可惜该位置有值了:
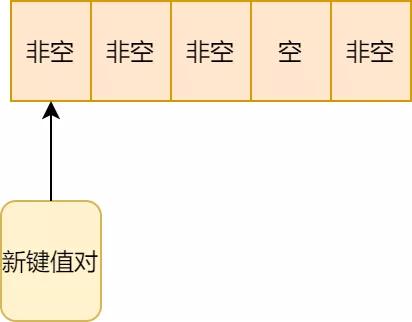
开放地址法
2.因此需要存储顺延的位置:
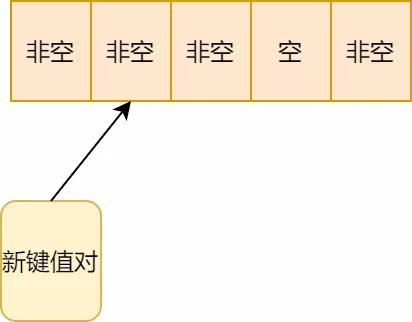
开放地址法
3.顺延位置也有值了,再往后顺延
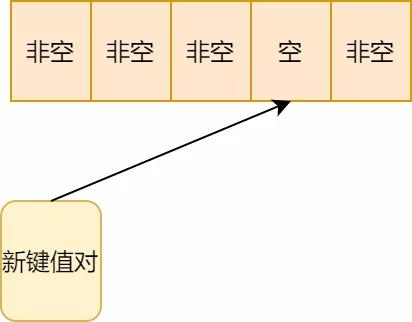
开放地址法
4.顺延位置还是有值,再往后顺延,终于存储上了
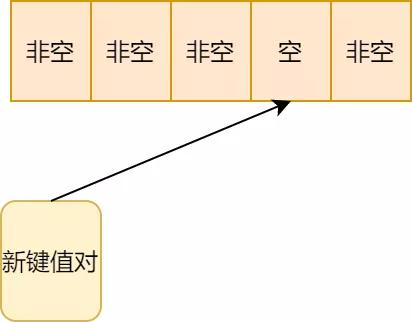
开放地址法
链地址法(拉链法)
Redis采用的方法就是这种拉链法。来看下面例子。新键值对计算应该存到二号,二号此时已经有一个键值对了。因此,直接通过链表的方式挂到二号键值对1的下面。
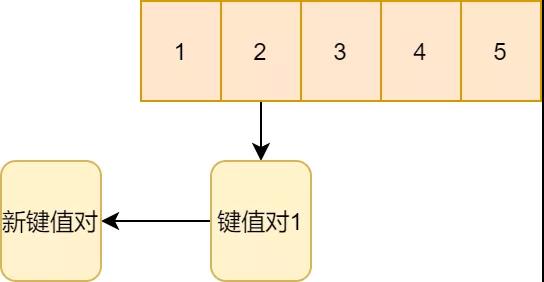
拉链法
对于新的键值对也是如此,通过链表的方式挂到二号键值对2的下面。
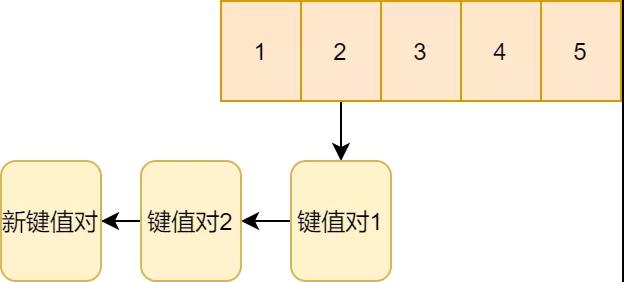
Rehash
在讲rehash之前,首先需要引入一个定义:负载因子。来看一下负载因子的定义吧:
负载因子 = 散列表内元素个数/散列表的长度
如果负载因子高,就说明哈希冲突概率大,这样会严重拖慢查找效率。
如果负载因子低,就说明这哈希表好像占用空间太多了,大部分空间都没元素。
为了使负载因子值在合理范围内,程序需要对哈希表进行扩展或收缩。由于空间变大或缩小,之前的键在老表的存储位置,在新表中就不一定一样了,需要重新计算。这个重新计算,并把老表元素转移到新表元素的过程就叫做rehash。当然无论是java中的hashmap,concurrenthashmap,还是今天要讲的Redis哈希表,都涉及rehash过程。
Redis中哈希表的数据结构
来看一下Redis的Hash表逻辑设计结构 Redis的哈希表主要由三个结构构成:
dictht。单纯表示一个哈希表
dictEntry。哈希表的一项,可以看作就是一个键值对
dict。Redis给外层调用的哈希表结构,包含两个dictht
- typedef struct dictht {
- dictEntry **table; //哈希表数组(哈希表项集合)
- unsigned long size; //Hash表大小
- unsigned long sizemask; //哈希表掩码
- unsigned long used;//Hash表已使用的大小
- } dictht;
稍微解释一下各个项。
- table:哈希表项的指针数组
- size:哈希表大小,这应该不用多解释吧
- sizemask:掩码。这个值其实设计思想很棒,假设Redis长度是3,你想访问第5个元素,如果按之前的方法,那肯定是访问到超出redis哈希表范围的地址空间了。所以redis规定,你想访问元素,先把index与size做与,把超过redis长度的部分就截断了,就不会发生内存安全问题。
- Hash表已使用的大小。不解释。
讲了Hash表,来看看哈希项
- typedef struct dictEntry {
- void *key;
- union {
- void *val;
- uint64_t u64;
- int64_t s64;
- double d;
- } v;
- struct dictEntry *next;
- } dictEntry;
我们知道,Redis采用拉链法解决哈希冲突的问题。因此,Redis的哈希表项就有一个next指针,指向下一个元素,通过该指针,就可以访问多个具有相同哈希值的键值对。
最后我们来看看dict结构。
- typedef struct dict {
- dictType *type;
- void *privdata;
- dictht ht[2];
- int reshaidx;
- } dict;
大家肯定很好奇,好好的dict,搞两个哈希表做啥?当然也有不好奇的小伙伴,但没办法,架不住面试官也很好奇啊。
答案揭晓,两个hash表是为了rehash。
那什么情况下需要rehash呢?
- 如果redis没在执行后台备份,当负载因子大于等于1就执行。(反正CPU闲着也是闲着)
- 如果redis在执行后台备份,当负载因子大于等于5就执行。(CPU在干备份了,咱对于实在挤的表改一改,等CPU闲下来,再把稍微偏挤的rehash)
我们来看一下如果出现需要rehash的情况,需要的执行步骤:
- 分配空间给ht[1]。分配空间由ht[0]的具体参数决定。
- 将ht[0]存储的键值对,重新计算hash值和索引值,并赋值到ht[1]的对应位置中。
- 当赋值完成后,释放ht[0]所占用空间,并把ht[0]指向ht[1]目前的地址。
- ht[1]指向空表。
渐进式rehash
由于步骤二采用的计算方式如果在一定时间做,占用资源过高,所以redis提出了渐进式rehash的方式。拿大白话来讲,就是原来是一次,一次性的搬运,现在变成了分批搬运。
在分批搬运的过程中,难免会收到其他各式各样的请求。
- 对于写请求,即往redis哈希表增加新的键值对时,redis会把数据直接存放到ht[1]表中。
- 对于查请求,即查询特定键对应的值时,redis首先会在ht[0]中查找,如果查找失败,就会在ht[1]表中查找。
- 对于更新请求,redis首先会在ht[0]中查找,如果查找失败,就会在ht[1]表中更新。
- 对于删除请求,redis首先会在ht[0]中查找,如果查找失败,就会在ht[1]表中删除。
参考
https://www.cnblogs.com/tekkaman/p/5141936.html
https://blog.csdn.net/yangbodong22011/article/details/78467583
Redis的设计与实现
Redis源码剖析与实战