













可能我们对 RocketMQ 的消费者认知乍一想很简单,就是一个拿来消费消息的客户端而已,你只需要指定对应的 Topic 和 ConsumerGroup,剩下的就是只需要:
- 接收消息
- 处理消息
就完事了。
简略消费模型
当然,可能在实际业务场景下,确实是这样。但是如果我们不清楚 Consumer 启动之后到底会做些什么,底层的实现的一些细节,在面对复杂业务场景时,排查起来就会如同大海捞针般迷茫。
相反,你如果了解其中的细节,那么在排查问题时就会有更多的上下文,就有可能会提出更多的解决方案。
关于 RocketMQ 的一些基础概念、一些底层实现之前都已在文章 RocketMQ基础概念剖析&源码解析 中写过了,没有相关上下文的可以先去补齐一部分。
简单示例
整体逻辑
首先我们还是从一个简单的例子来看一下,RocketMQ Consumer 的基本使用。从使用入手,一点点了解细节。
- public class Consumer {
- public static void main(String[] args) throws InterruptedException, MQClientException {
- DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name_4");
- consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
- consumer.subscribe("TopicTest", "*");
- consumer.registerMessageListener(new MessageListenerConcurrently() {
- @Override
- public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
- ConsumeConcurrentlyContext context) {
- System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
- return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
- }
- });
- consumer.start();
- System.out.printf("Consumer Started.%n");
- }
- }
代码看着肯定有些难度,下面的流程图和上面的代码逻辑等价,可以结合着一起看。
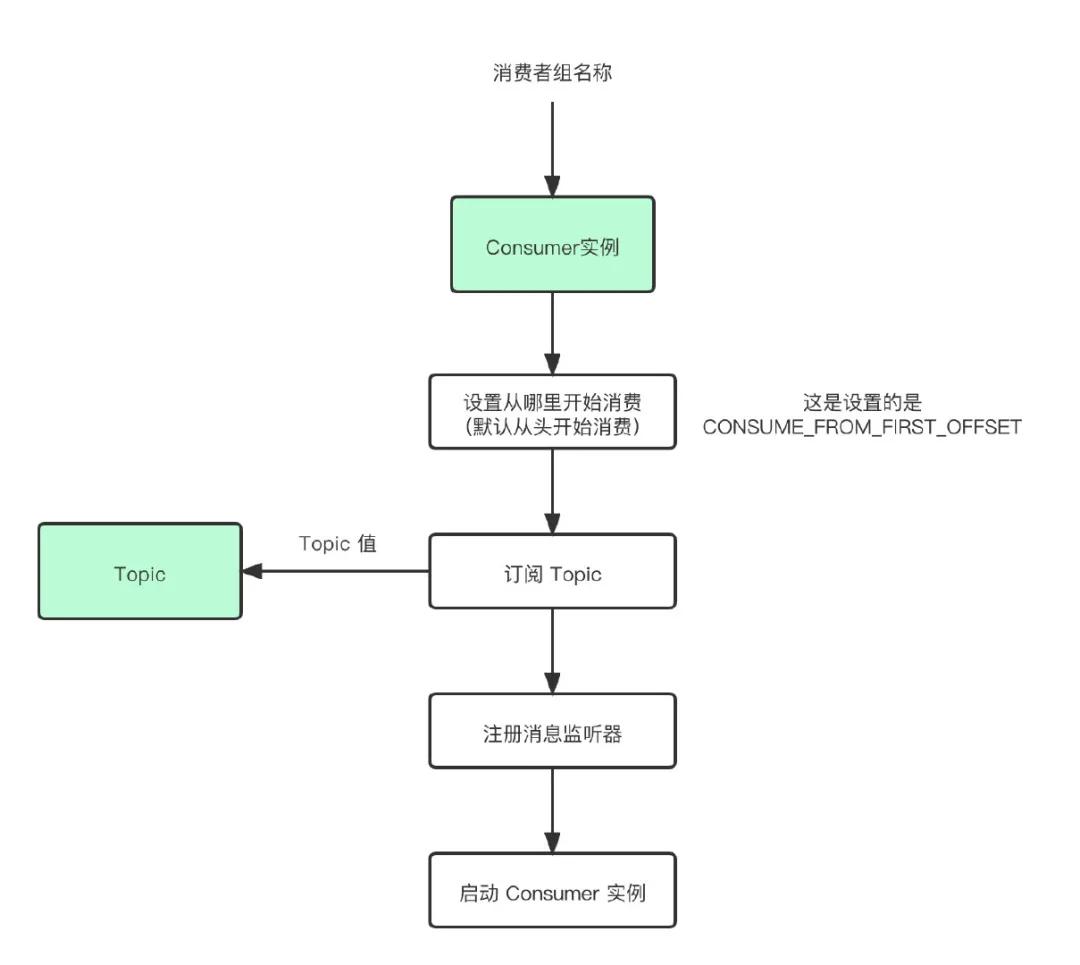
Consumer使用示例
消费点策略
这里除了像 Topic、注册消息监听器这种常规的内容之外,setConsumeFromWhere 值得我们更多的关注。它决定了消费者将从哪里开始消费,可选的值有三个:
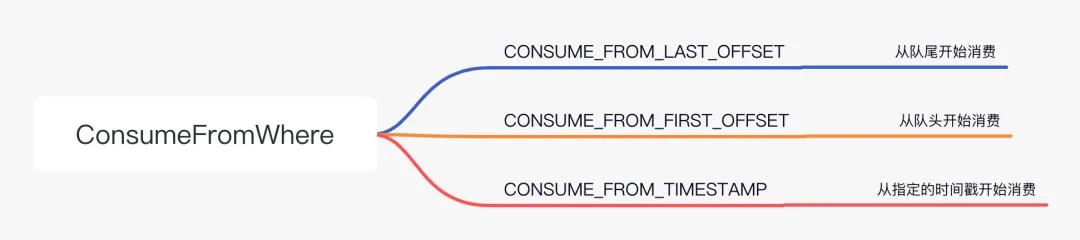
三个可选的 ConsumeFromWhere 的值
实际上 ConsumeFromWhere 的枚举类源码中还有另外三个值,但是已经被弃用了。但是这个配置仅对新的 ConsumerGroup 有效,已经存在的 ConsumerGroup 会继续按照上次消费到的 Offset 继续消费。
其实也很好理解,假设有 1000 条消息,你的服务已经消费到了 500 条了,然后你上线新的东西将服务重新启动,然后又从头开始消费了?这不扯吗?
缓存订阅的 Topic 信息
看起来就一行 consumer.subscribe("TopicTest", "*"),实际上背后做了很多事情,这里先给大家把简单的流程画出来。
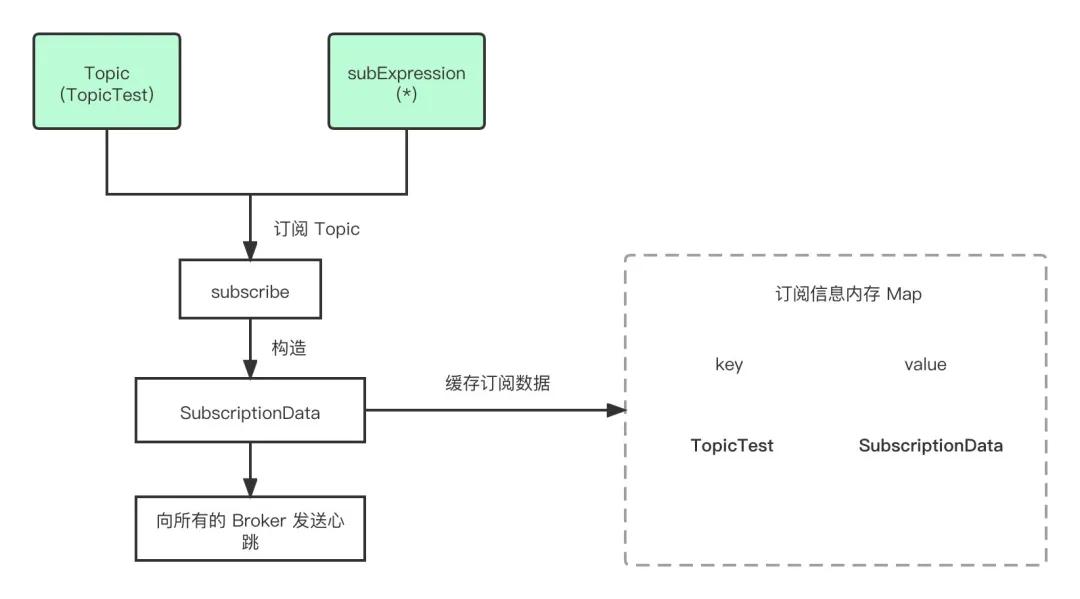
subscribe_topic
subscribe 函数的第一个参数就是我们需要消费的 Topic,这个自不必多说。第二个参数说复杂点叫过滤表达式字符串,说简单点其实就是你要订阅的消息的 Tag。
每个消息都会有一个自己的 Tag 这个如果你不清楚的话,可以考虑去看看上面那篇文章
这里我们传的是 *,代表订阅所有类别的消息。当然我们也可以传入 tagA || tagB || tagC 这种,代表我们只消费打了这三种 Tag 的消息。
RocketMQ 会根据我们传入的这两个参数,构造出 SubscriptionData ,放入一个位于内存的 ConcurrentHashMap 中维护起来,简单来说就一句话,把这个订阅的 Topic 缓存下来。
在缓存完之后会进行一个比较关键的操作,那就是开始向所有的 Broker 发送心跳。Consumer 客户端会将:
- 消费者的名称
- 消费类型 代表是通过 Push 或者 Pull 的模式消费消息
- 消费模型 指集群消费(CLUSTERING)或者是广播消费(BROADCASTING)
- 消费点策略 也就是类似 CONSUME_FROM_LAST_OFFSET 这种
- 消费者的订阅数据集合 一个消费者可以监听多个 Topic
- 生产者的集合 当前实例上注册的生产的集合
没错,在 Consumer 实例启动之后还会去运行 Producer 的相关代码。此外,如果一个客户端即没有配置生产者、也没有配置消费者,那么是不会执行心跳的逻辑的,因为没有意义。
启动消费者实例
上文提到的核心逻辑其实都在这里,我们在下面详细讨论,所以简单示例到这里就结束了。
进入启动核心逻辑
在启动的核心入口类中,总共对 4 种状态进行了分别处理,分别是:
- CREATE_JUST
- RUNNING
- START_FAILED
- SHUTDOWN_ALREADY
但我们由于是刚刚创建,会走到 CREATE_JUST 的逻辑中来,我们就重点来看 Consumer 刚刚启动时会做些什么。
检查配置
基操,跟我们平时写的业务代码没有什么两样,检查配置中的各种参数是否合法。
配置项太多了就不赘述,大家只需要知道 RocketMQ 启动的时候会对配置中的参数进行校验就知道了。
算了,还是列一列吧:
- 消费者组的名称是不是空
- 消费者组的名称不能是被 RocketMQ 保留使用的名称,即 —— DEFAULT_CONSUMER
- 消费模型(CLUSTERING、BROADCASTING)是否有配置
- 消费点策略(例如 CONSUME_FROM_LAST_OFFSET)是否配置
- 判断消费的方式是否合法,只能是顺序消费或者并发消费
- 消费者组的最小消费线程、最大消费线程数量是否在规定的范围内,这个范围是指(1, 1000),左开右开。还有就是最小不能大于最大这种判断
- ......等等等等
所以你看到了, 即使是牛X的开源框架也会有这种繁琐的、常见的业务代码。
改变实例名称
instanceName 会从系统的配置项 rocketmq.client.name 中获取,如果没有配置就会设置为 DEFAULT。,并且消费模型是 CLUSTERING(默认情况就是),就会将 DEFAULT 改成 ${PID}#${System.nanoTime()} 的字符串,这里举个例子。
- instanceName = "90762#75029316672643"
为什么要单独把这个提出来讲呢?这相当于是给每个实例一个唯一标识,这个唯一标识其实很重要,如果一个消费者组的 instanceName 相同,那么可能就会造成重复消费、或者消息堆积的问题的问题,造成消息堆积的这个点比较有意思,后续我有时间应该会单独写一篇文章来讨论。
但眼尖的同学可能已经看到了,instanceName 的组成不是 PID 和 System.nanoTime?PID 可能由于获取的是 Docker 容器宿主机器的 PID,可能是一样的,可以理解。那 System.nanoTime 呢?这也能重复?
实际上从 RocketMQ 的 Github 这个提交记录来看,至少在 2021年3月16号之前,这个问题还是有可能存在的。

RocketMQ 官方 Github 的提交记录
RocketMQ 官方在 3月16号的提交修复了这个问题,给大家看看改了啥:

提交具体内容
在原来的版本中,instanceName 就只由 PID 组成,就完全可能造成不同的消费者实例拥有相同的 instanceName。
熟悉的 RocketMQ 的同学有疑问,在 Broker 侧对 Consumer 的唯一标识不是 clientID 吗?没错,但 clientID 是由 clientIP 和 instanceName 一起组成的。
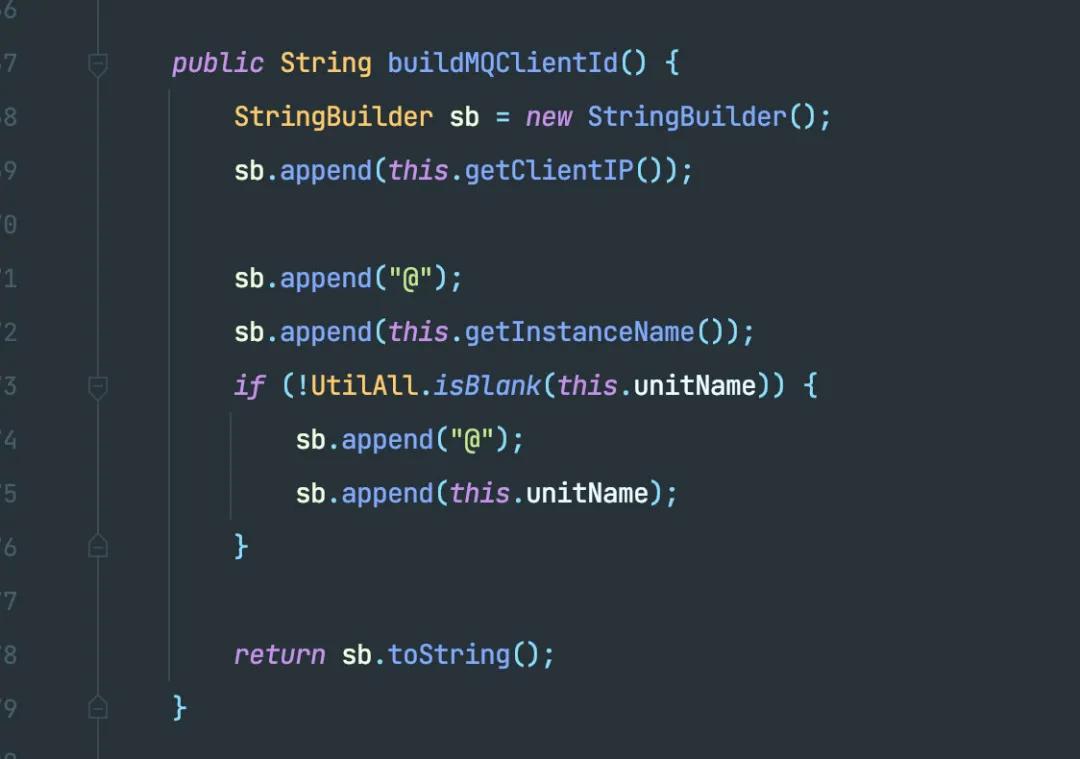
而 clientIP 上面也提到过了,可能由于 Docker 的原因获取到相同的,会最终导致 clientID 相同。
OK,关于改变实例的名称就到这,确实没想到讲了这么多。
实例化消费者
关键变量名为 mQClientFactory
接下来就会实例化消费者实例,在上面 改变实例名称 中讲到的 clientID 就是在这一步做的初始化。这里就不给大家列源码了,你就需要知道这个地方会实例化出来一个消费者就 OK 了,不要过多的纠结于细节。
然后会给 Rebalance 的实现设置上一些属性,例如消费者组名称、消息模型、Rebalance 采取的策略、刚刚实例化出来的消费者实例。
这个 Rebalance 的策略默认为:
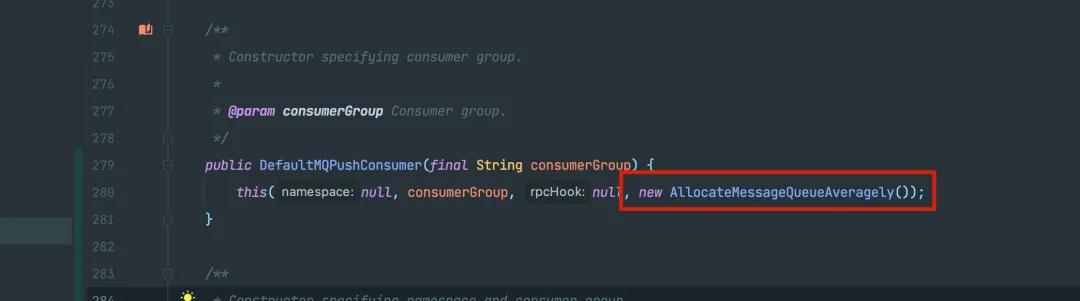
AllocateMessageQueueAveragely 就是一个把 Messsage Queue 平均分配给消费者的策略,更多的细节也可以参考我上面的那篇文章。
除此之外,还会初始化拉取消息的核心实现 PullAPIWrapper。
初始化 offsetStore
这里会根据不同的消息模型(即 BROADCASTING 或者 CLUSTERING),实例化不同的 offsetStore 实现。
- BROADCASTING 采用的实现为 LocalFileOffsetStore
- CLUSTERING 采用的实现为 RemoteBrokerOffsetStore
区别就是 LocalFileOffsetStore 是在本地管理 Offset,而 RemoteBrokerOffsetStore 则是将 offset 交给 Broker 进行原
启动 ConsumeMessageService
缓存消费者组
接下来会将消费者组在当前的客户端实例中缓存起来,具体是在一个叫 consumerTable 的内存 concurrentHashMap 中。
其实源码中叫 registerConsumer:
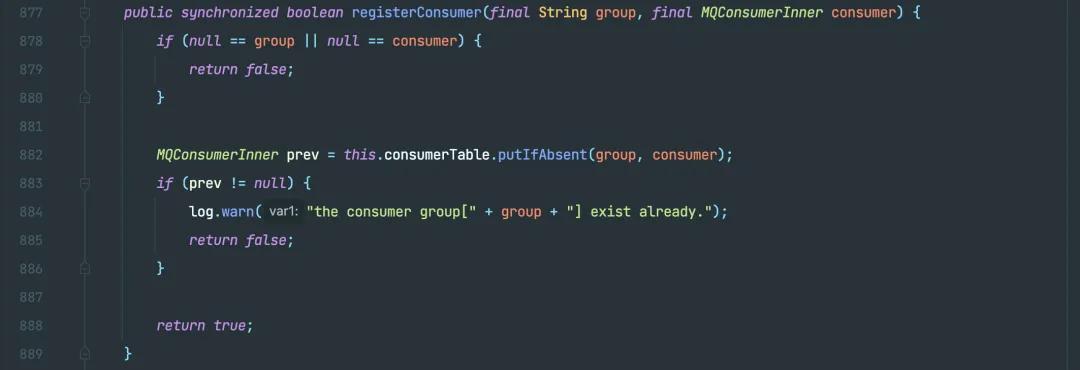
registerConsumer 源码
但我认为给大家「翻译」成缓存更合理,因为它就只是把构建好的 consumer 实例给缓存到 map 中,仅此而已。哦对,还做了个如果存在就返回 false,代表实际上并没有注册成功。
那为啥需要返回 false 呢?你如果存在了不执行缓存逻辑就好吗?甚至外面还要根据这个 false 来抛出 MQClientException 异常?
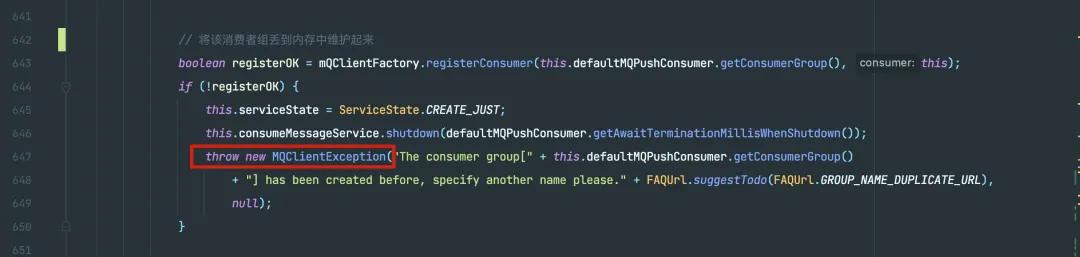
如果注册失败,抛出异常
为啥呢?假设你同事 A 已经使用了名称 consumer_group_name_for_a ,线上正在正常的运行消费消息。得,你加了个功能需要监听 MQ,也使用了 consumer_group_name_for_a,你想想如果 RocketMQ 不做校验,你倒是注册成功了,但是你同事 A 估计要骂娘了:“咋回事?咋开始重复消费了?”
启动 mQClientFactory
这个 mQClientFactory 就是在 实例化消费者 步骤中创建的消费者实例,最后会通过调用 mQClientFactory.start()。
这就是最后的核心逻辑了。
初始化 NameServer 地址

初始化用于通信的 Netty 客户端

初始化 Netty 客户端
启动一堆定时任务
这个一堆没有夸张,确实很多,举个例子:
- 刚刚上面那一步,如果 NameServer 没有获取到,就会启动一个定时任务隔一段时间去拉一次
- 比如,还会启动定时任务隔一段时间去 NameServer 拉一次指定 Topic 的路由数据。这个路由数据具体是指像 MessageQueue 相关的数据,例如有多少个写队列、多少个读队列,还有就是该 Topic 所分布的 Broker 的 brokerName、集群和 IP 地址等相关的数据,这些大致就叫路由数据
- 再比如,启动发送心跳的定时任务,不启动这个心跳不动
- 再比如,Broker 有可能会挂对吧?客户端这边是不是需要及时的把 offline 的 Broker 给干掉呢?所以 RocketMQ 有个 cleanOfflineBroker 方法就是专门拿来干这个的
- 然后有一个比较关键的就是持久化 offset,这里由于是采用的 CLUSTERING 消费,故会定时将当前消费者消费的情况上报给 Broker













