随着企业数字化转型的进程加快,零代码平台的的应用越来越广泛,逐渐被企业级的客户认可和接受。
零代码顾名思义就是在不写代码的情况下可以搭建应用和功能来满足客户的需求,但事实是残酷的,真实的客户需求永远比我们想象的要复杂,传统的零代码产品需要提供各种扩展能力,比如可以让开发人员编写复杂的业务逻辑代码,并对接到平台中。
这样虽然能够满足需求,但会有两个问题:
- 客户的需求随时可能发生变化,需求一变就需要进行代码的修改;
- 一线业务人员无法直接在平台中进行调整,一些小的改动都需要进行开发、测试、发布的流程。
这时就需要服务编排了,服务编排是什么,下面举两个例子:
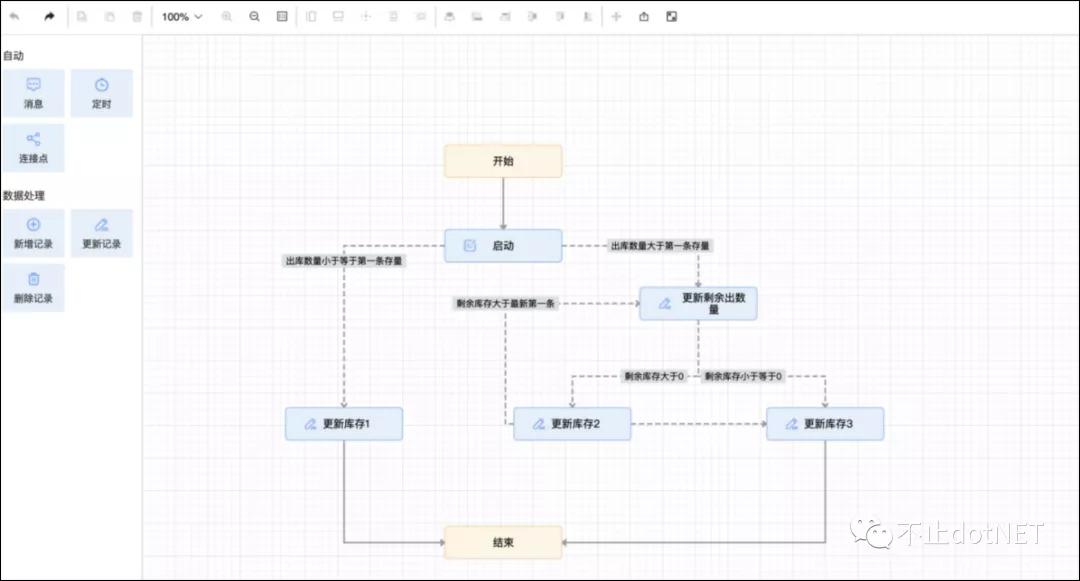
1、仓储物流出库先进先出更新库存量
在仓储物流系统中,商品的入库有时间的先后顺序,出库时需要遵循先入库的先进行出库,如下图所示:
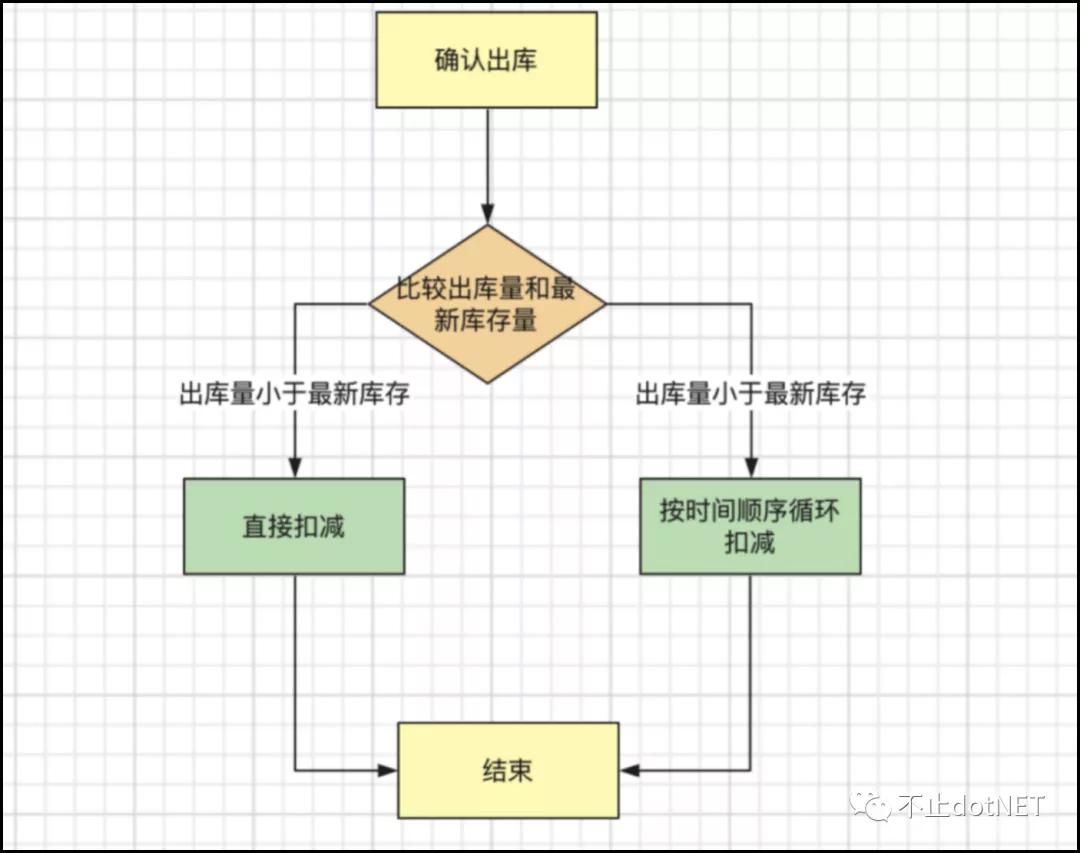
在不具备服务编排的系统中,搭建好功能后,还需要编写处理出库逻辑的 API 接口方法和系统中的某个方法对接起来。这个工作只能由开发人员来完成。
使用服务器编排工具,就能轻松地可视化拖拽就能实现了,如下图:
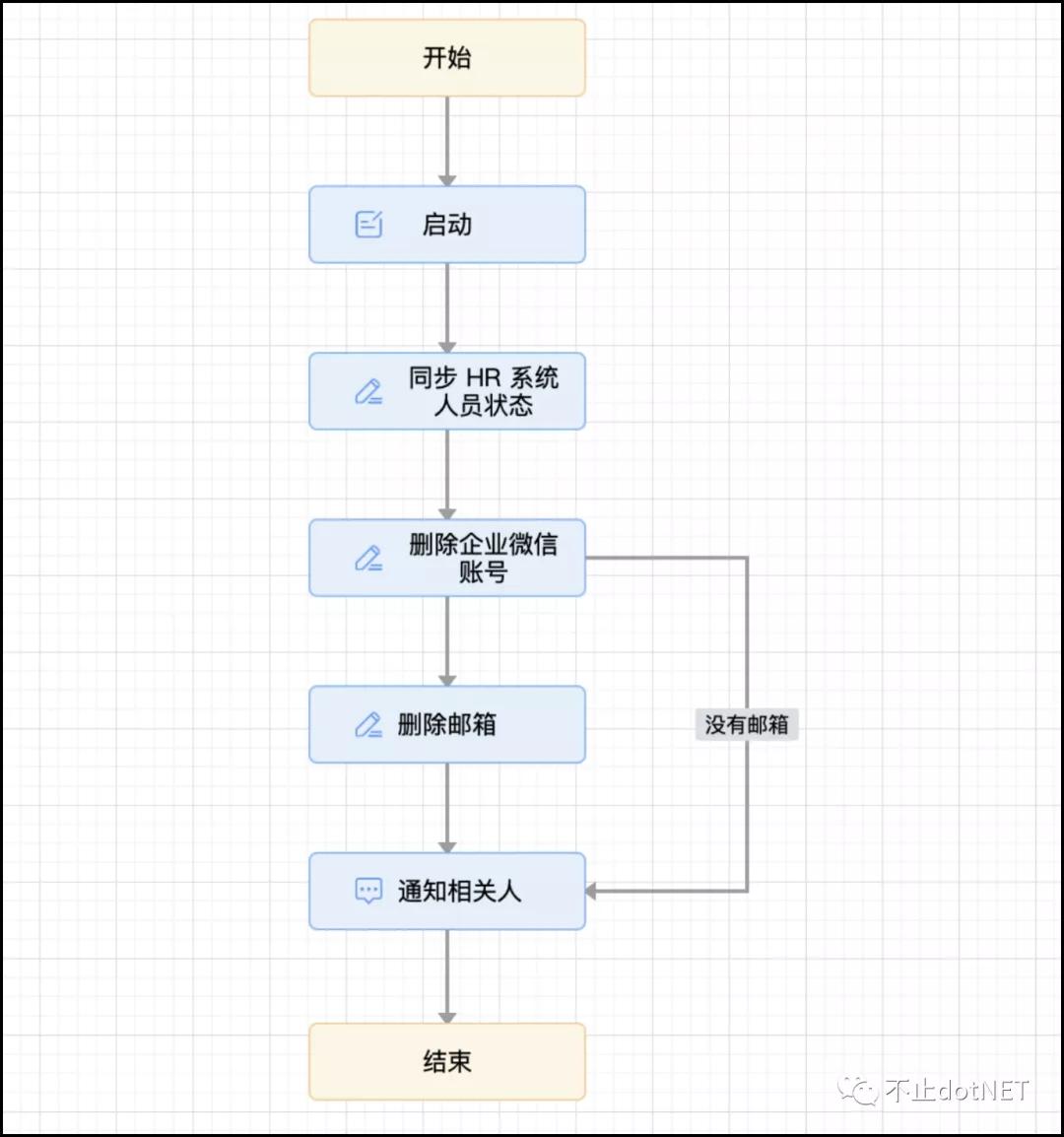
2、人员离职后需要处理一系列的操作,比如:
修改 HR 系统中对应用户的状态;
删除企业微信中的账号;
禁用邮箱;
发送通知。
使用服务编排可以很轻松就能实现,前提是要有丰富的业务组件:
服务编排其实就是一系列单个的业务组件通过流程的方式进行组合起来,最终达到业务的目的,流程中可以控制分支逻辑或循环逻辑。
提到流程,我们印象里都是 OA、CRM 等系统中的各种请假审批流、合同审批流等。事实上,广义上的工作流是对工作流程及其各操作步骤之间业务规则的抽象、概括、描述。
简单的说,为了实现某个业务目标,抽象拆解出来的一系列步骤及这些步骤之间的协作关系,就是工作流。也就是上面所说的业务服务的编排流程。
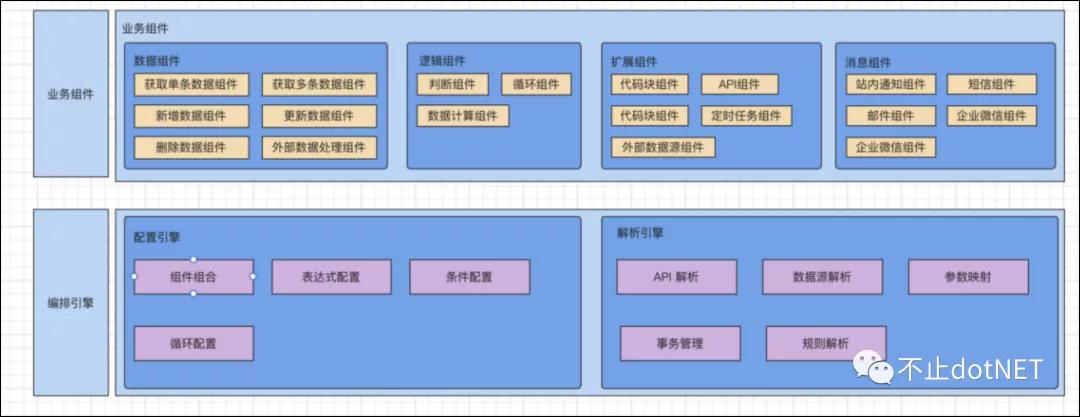
服务编排引擎的总体架构图如下:
在近些年比较火的微服务中也存在着服务的编排,常见的有三种模式:
- Orchestration(编制):通过一个可执行的流程来协同内部及外部的服务交互,通过流程来控制总体的目标、涉及的操作、服务调用顺序。这种模式必须有一个流程控制服务,用来接收请求,组织服务间的调用,并最终完成业务逻辑。这种方案中大多是同步调用,虽然在某个时刻能够很清晰的知道服务的执行情况,但当业务复杂,服务很多的情况下,在控制服务中会存在大量的耦合,难以维护;
- Choreography(编排):通过消息的交互序列来控制各个部分资源的交互,参与交互的资源都是对等的,没有集中的控制。可以看作一种消息驱动模式,或者说是订阅发布模式,不同的服务之间通过消息机制串联起来,这种方式大多都是异步的。好处就是耦合度低,但也会带来一些问题,比如:业务流程是通过订阅的方式来体现的,很难直接监控每笔业务的处理,因此难于调试;由于没有预定义流程,所以很难在事前保证流程正确性,基本靠事后分析数据来判断等;
- API网关:API网关是一种简单的接口聚合/拆分的方式:业务组件的请求后先到达网关,网关调用各微服务,并最终聚合/拆分需反馈的结果。API网关其实就是一个适配网关,比如对于 Web端,可以一个页面同时发起几十个请求,而对于移动端,最好是一个页面就几个请求。而采用API 网关,后面的微服务可以是相同的。但只能应对一些逻辑简单的场景。
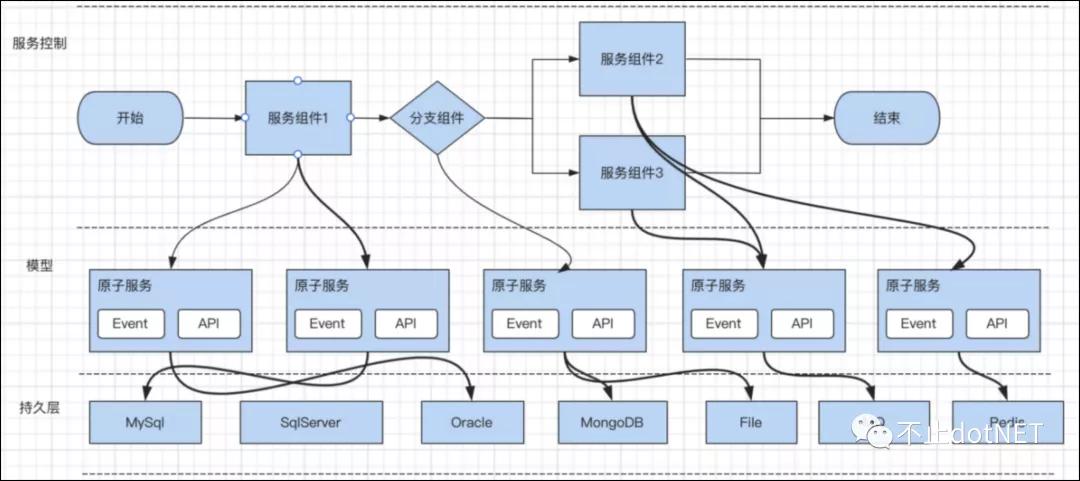
结合上面方式各自的优点,服务编排引擎的实现思路如下:
1、一个服务的编排由一个或多个业务服务组件组成;
2、一个业务服务组件可以拆解为一个或多个原子服务;
3、每个原子服务可以抽象成一个通用模型;
4、每个原子服务提供 API 接口和事件监听机制;
5、每个原子服务根据持久化适配器将数据更新到订阅的持久化组件中。
整体过程如下图:
服务组件的调用是同步还异步,我们把这个决定权交给用户,可以通过设置的方式来进行,并提供重试机制,确保数据的最终一致性。
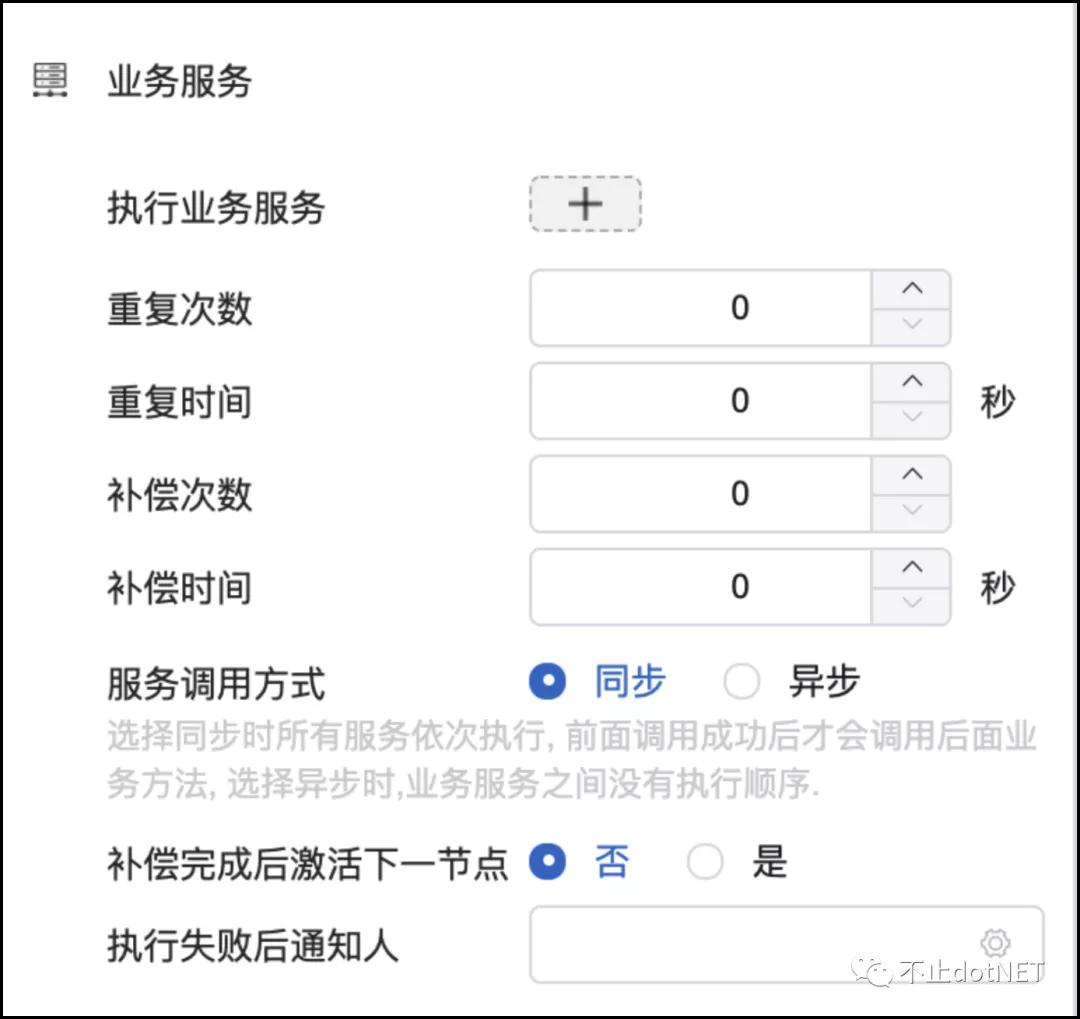
每个服务组件都有自己的入参和出参,在一个服务编排的请求上下文中会随着执行的阶段不同,动态组织参数,参数适配器会根据名称、类型等进行自动适配,当然也能根据在设置界面中的手动绑定进行适配。
原子服务只做一件事情,通过一个原子服务或多个原子服务,可以组装出来各种不同功能的业务组件,通过事件监听机制让服务之间、组件之间可以彻底解耦,以便能够灵活组装。
随着服务和组件的增多,调用链会变得越来越复杂,当一个服务编排整个处理完后,调用链会形成一个复杂网络,这对排查问题造成很大的麻烦。我们采用全链路跟踪来解决这个问题,在一个完整的业务调用开始时,会生成一个唯一 ID,这个 ID 会一直存储在调用上下文中。
上面说到原子服务会有两种方式被执行,API 和事件监听的方式,如果是 API ,ID 可以放在请求头中传递到下一层,如果是事件监听,ID 会做为消息体的一部分进行传递。
假设现在用户已编排了一个复杂的业务,服务组件之间的调用有同步也有异步,当某个环节出现问题时候,我们需要保证数据的最终一致性。常用的一种方式就是提供补偿机制。
补偿模式核心思想是:针对每个操作,都要注册一个与其对应的补偿(撤销)操作,一般来说操作本身和其补偿操作会在一个事务里完成,当其后续操作失败后,需要按相反顺序完成前面注册的所有撤销操作。
我们的补偿机制分为两种:
1、特定服务组件上的独立设置;
2、全局控制调用补偿,所有被调用服务会记录到一个列表中,如果出现需要重试或者回滚的操作,再从列表中获取出来进行相应的操作。
在补偿模式中,要求能够提供补偿的服务的操作必须支持幂等,否则当多次执行的时候就会出现数据错误。正常情况下,所有的补偿都是自动触发的,但有些特殊的场景还是需要人工干预,在调用失败的日志列表中管理员可以进行手动重试。