












基于JAVA开发的Weka是一款不错的机器学习以及数据挖掘的开源软件。在上一个文章(Top期刊中拟南芥高质量抠图,不用PS用这个,点点鼠标就搞定)当为大家介绍了一款神器ImageJ,而Weka也作为一个插件集成在该软件中。
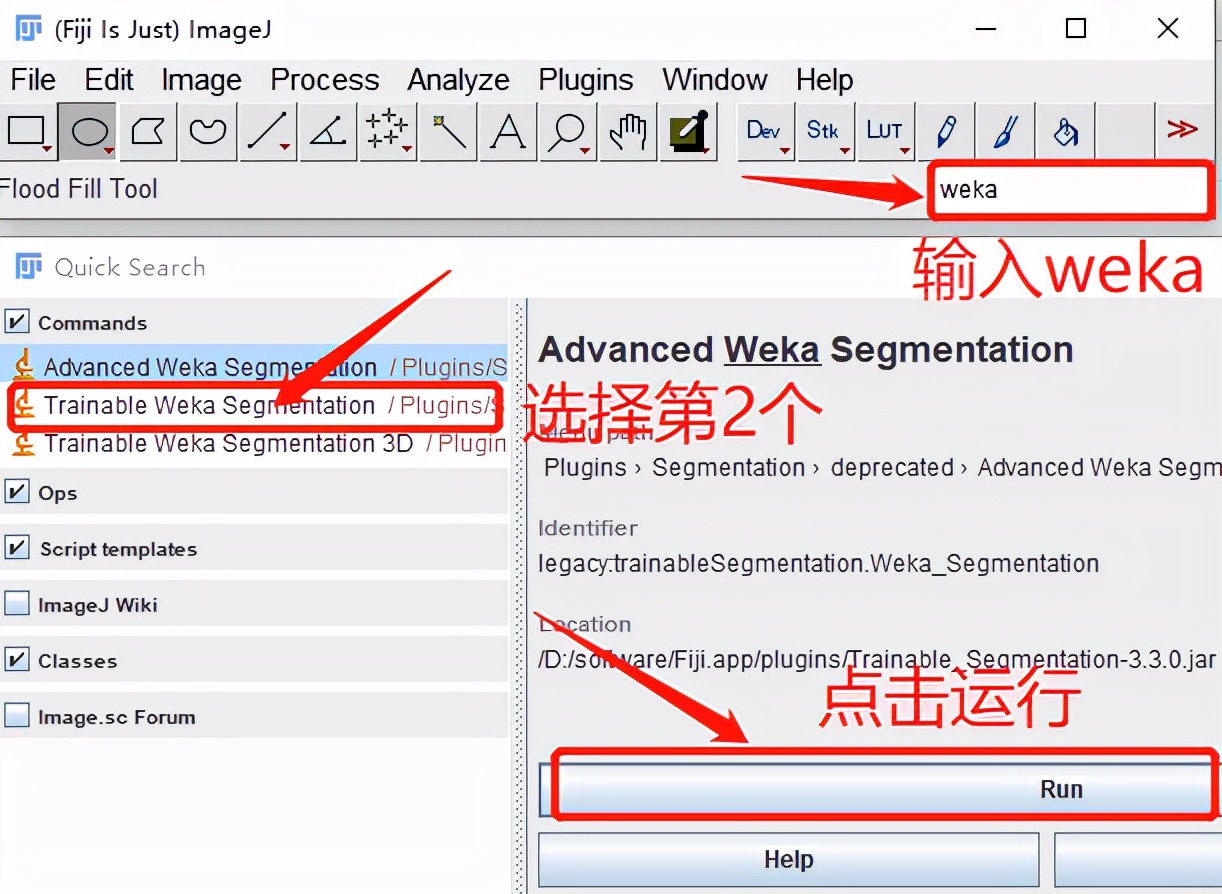
紧接着软件弹窗提示打开图片,我们这次训练识别孢子模型,如下图:
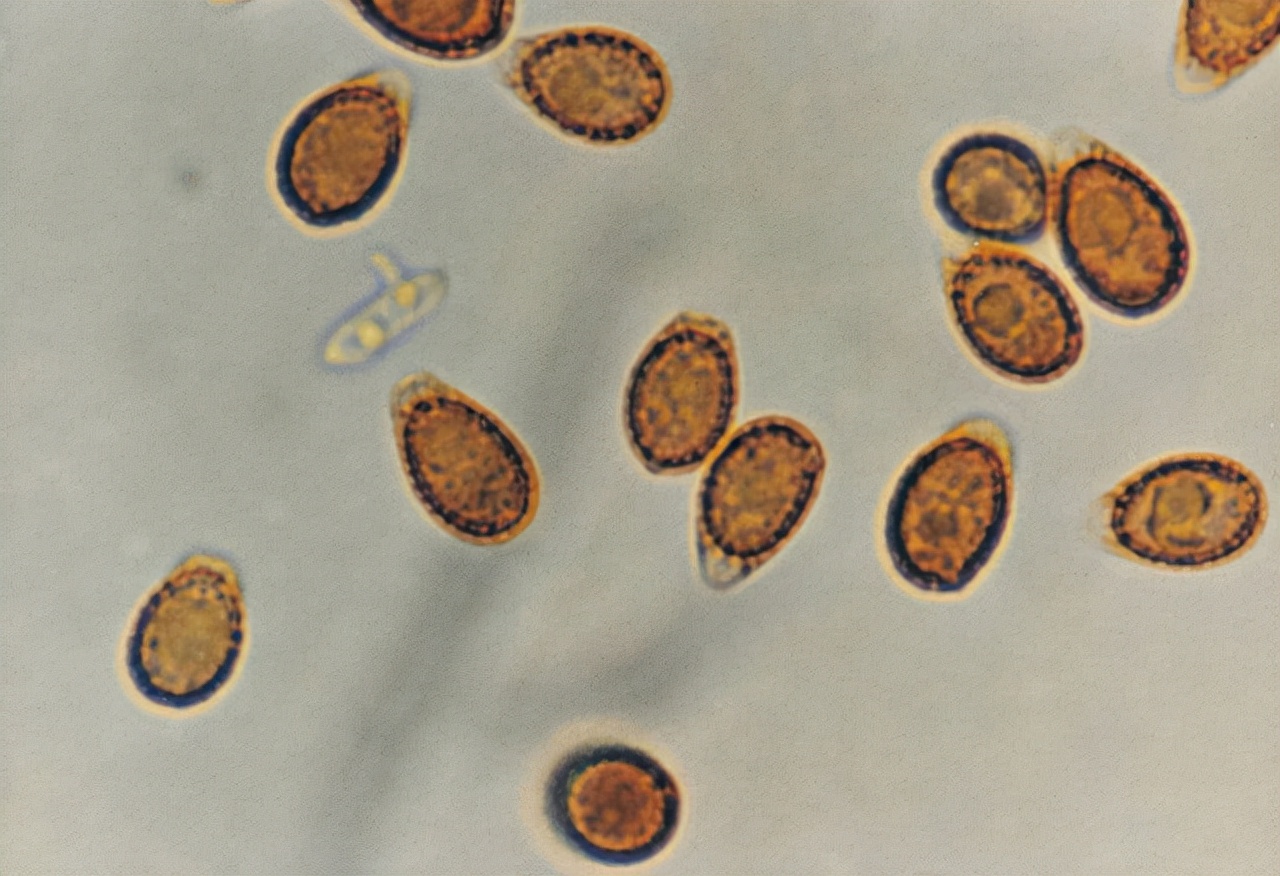
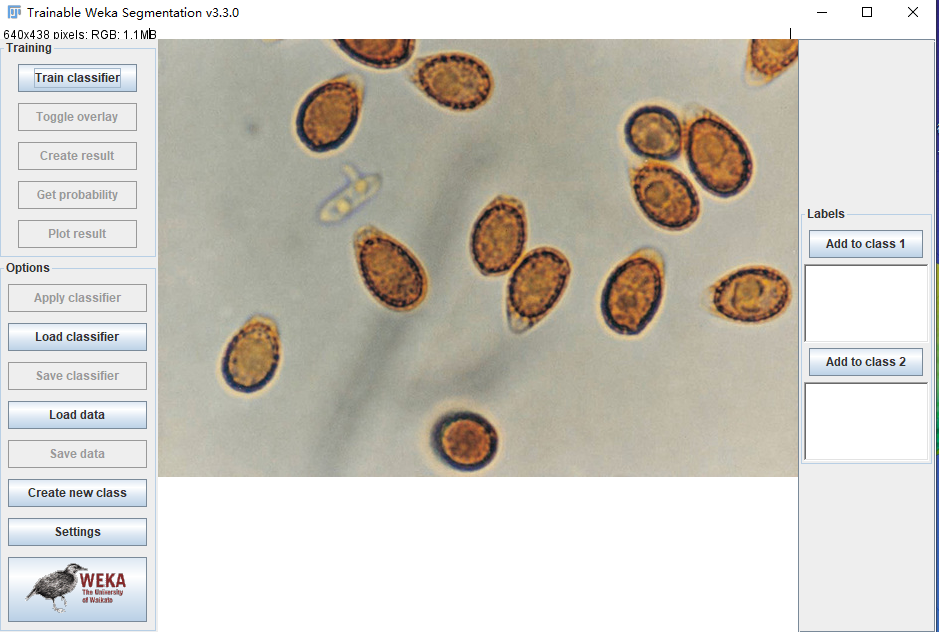
选择图片后即可进入WEKA界面。
该界面包括:
- 训练栏:模型训练(Train classifier)
- 选项栏:加载模型(Load classifier)、加载数据(Load Data)、新建类别(Create new class)、设置(Settings)
- 标签栏:添加不同分类(此处分类默认两个,可以在Settings中进行详细设置)
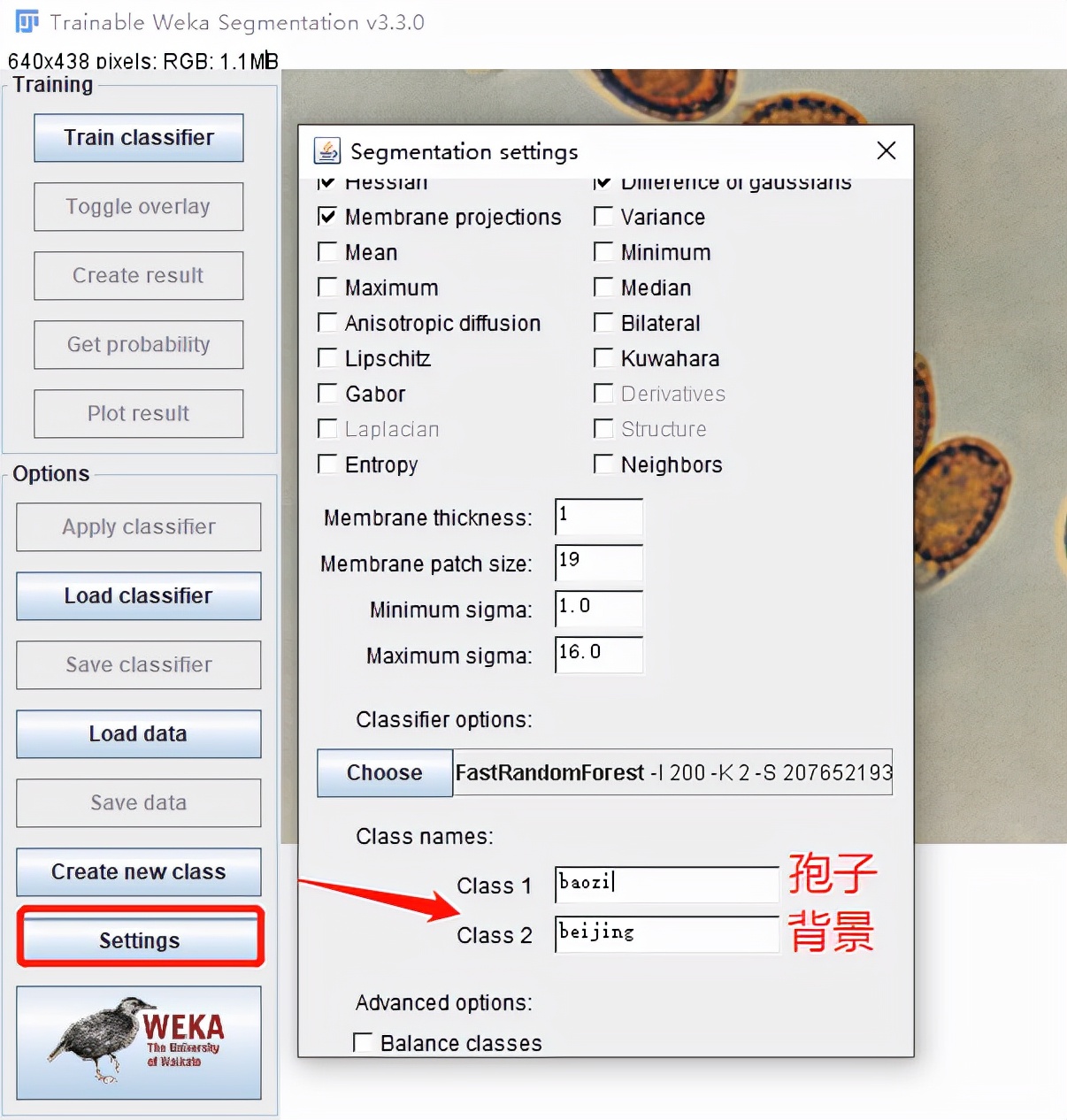
我们进入设置,可以对类别进行重命名,这样防止混乱。
模型训练
接下来我们开始训练模型
首先在ImageJ面板上选择形状选择工具,圈选孢子并填入到孢子分类(红色模块),同理分类背景(绿色模块)。全选完毕后点击模型训练(Train classifier)等待机器训练完毕。


短暂等待后,我们发现所有孢子都标红,背景标绿。

模型训练还不错,但还需要进行微调。如相邻较近的孢子被圈成一块,我们需要将其分开,所以这次我们使用划线分割并添加到背景标签中,然后再次进行训练。
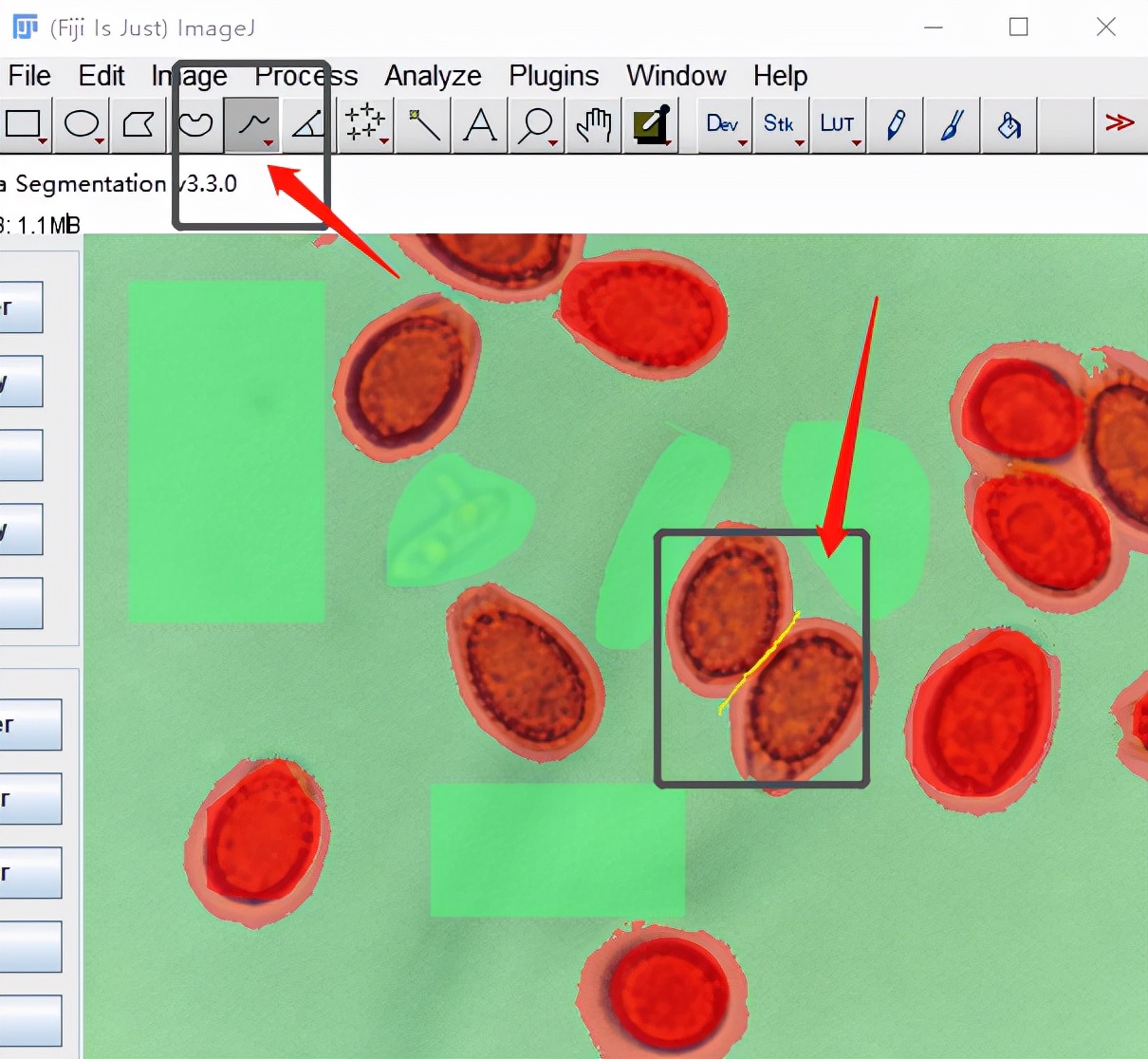
再次训练后的模型,此时的模型比上次更好,如果还不满意,可以继续微调。
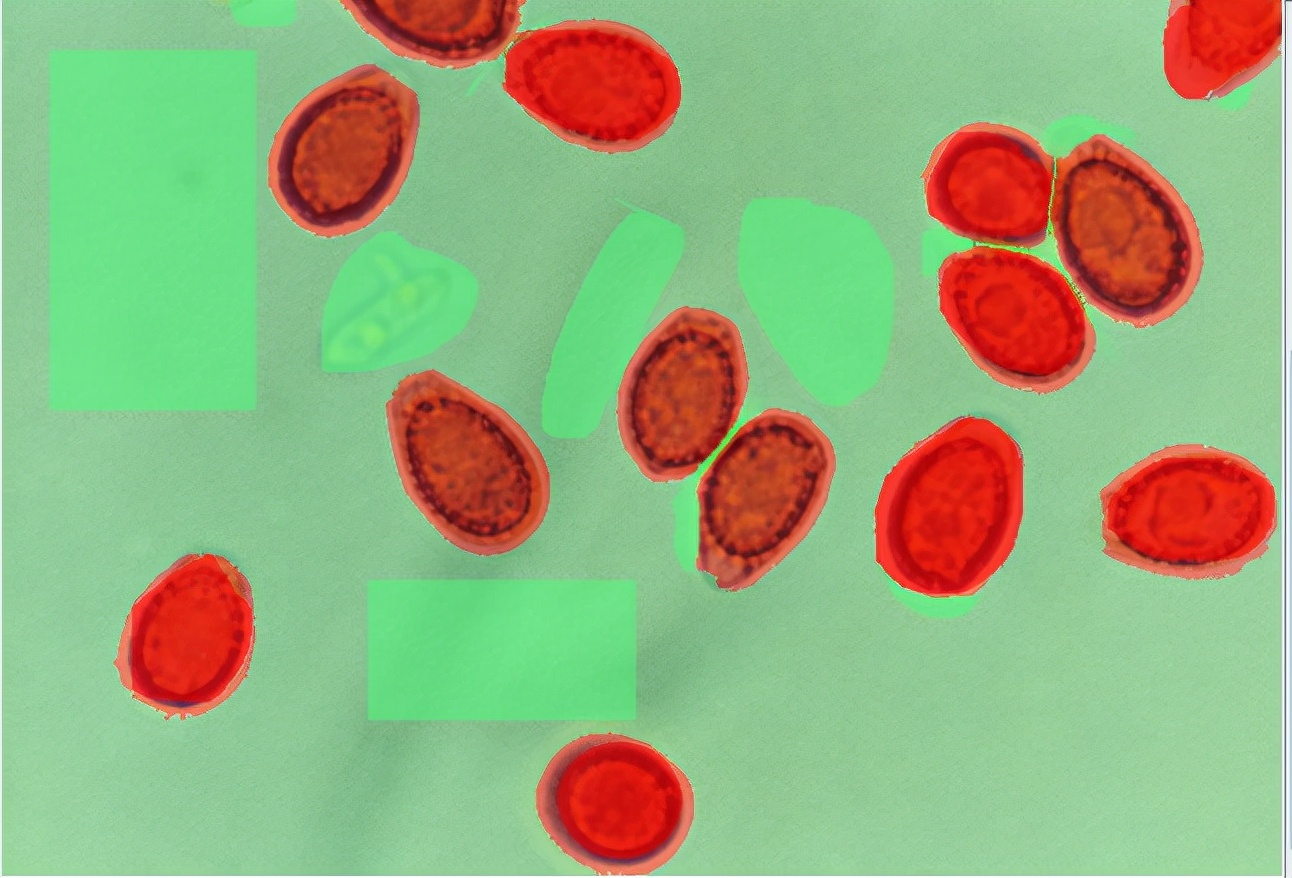
个数统计
训练完毕后选择 Create result
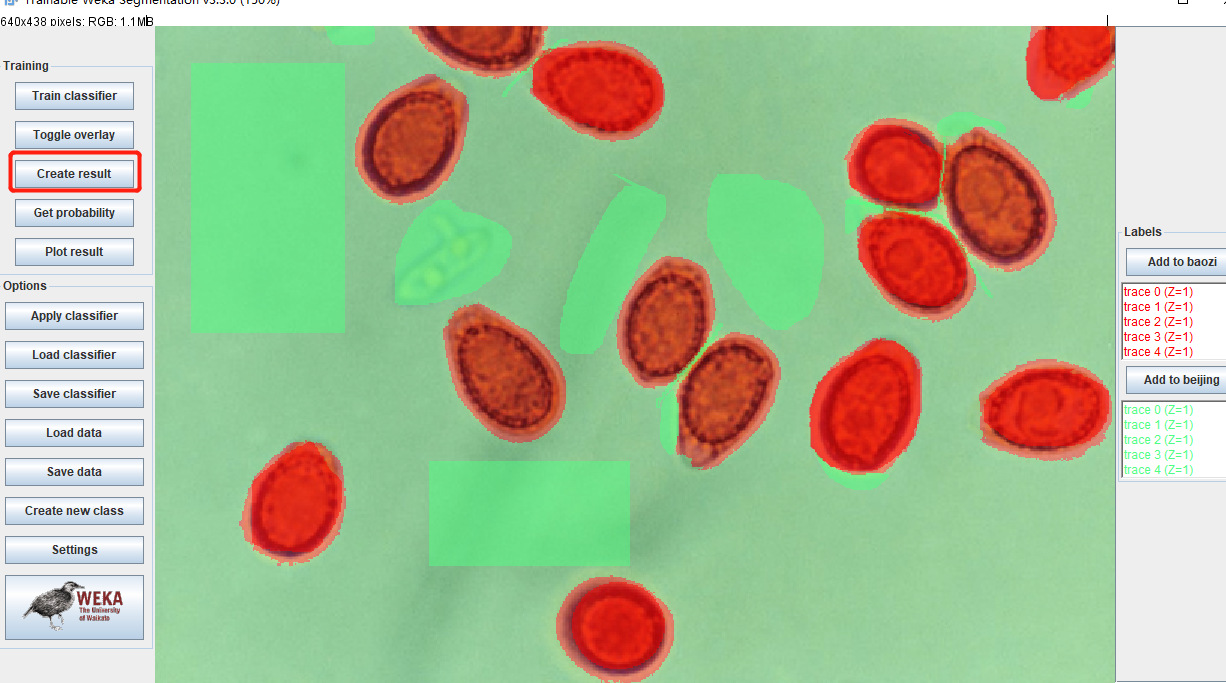
点选后结果如下图:

这时只需要这几步操作:
1、Image→Type→8 bit
2、Image→Adjust→Threshold
3、拖动滑轮调节成 白背景 黑孢子如下图
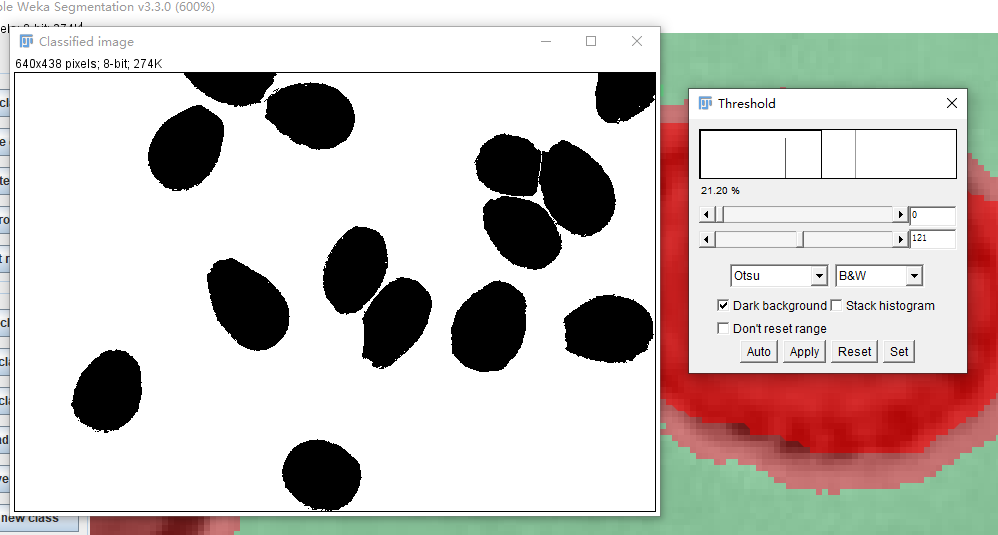
4、Process→Filters→Median
5、Process→Binary→Watershed
6、Analyze→Analyze Particles(注意:因为边界上面有孢子,所以不勾选Exclude on edges)
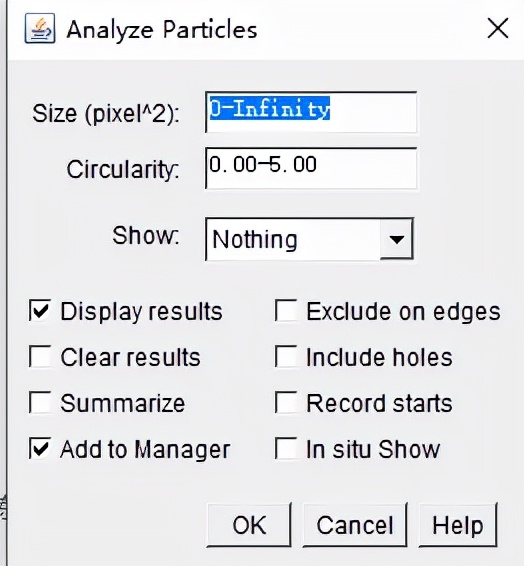
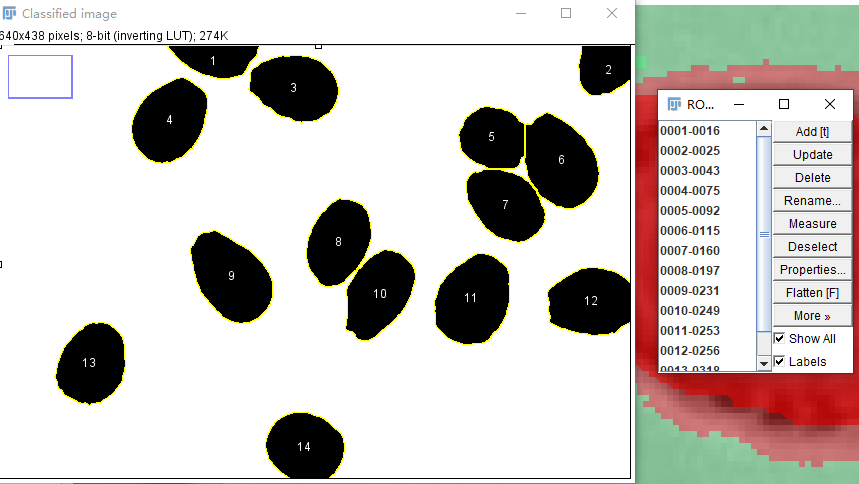
计数结果如下图:
模型保存与调用
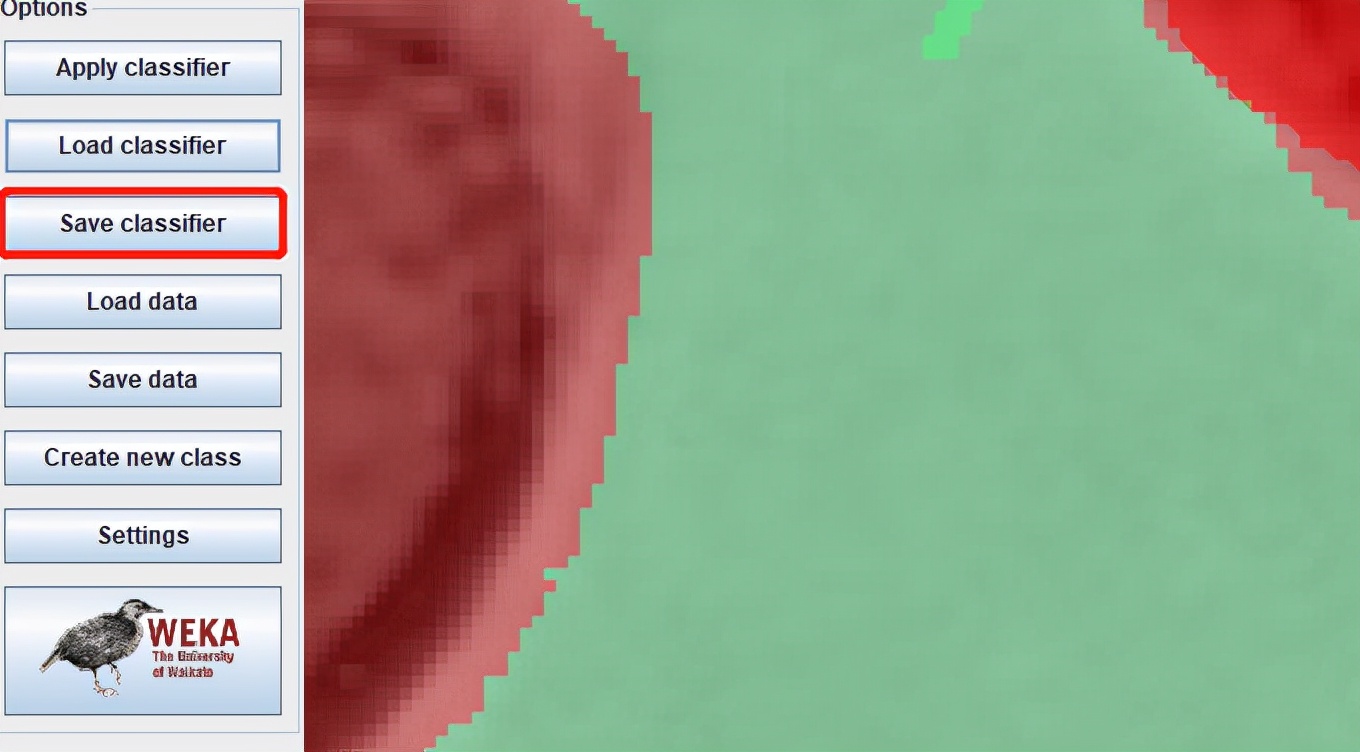
- 保存模型:
我们再次回到WEKA界面,然后点击 保存分类模型 (Save classifier),文件格式是classifier.model
- 调用模型
使用WEKA打开新的孢子图片后直接加载模型(Load classifier),然后直接Create result 即可分析图片,然后重复 个数统计 操作流程即可。
最后
清代彭端淑在《为学一首示子侄》说“天下事有难易乎?为之,则难者亦易矣;不为,则易者亦难矣。人之为学有难易乎?学之,则难者亦易矣;不学,则易者亦难矣。”
























