













上周松哥转载了一个数据批量插入的文章,里边和大家聊了一下数据批量插入的问题,批量插入到底怎么做才快。
有个小伙伴看了文章后提出了不同的意见:

松哥认真和 BUG 同学聊了下,基本上明白了这个小伙伴的意思,于是我自己也写了个测试案例,重新整理了今天这篇文章,希望和小伙伴们一起探讨这个问题,也欢迎小伙伴们提出更好的方案。
1. 思路分析
批量插入这个问题,我们用 JDBC 操作,其实就是两种思路吧:
- 用一个 for 循环,把数据一条一条的插入(这种需要开启批处理)。
- 生成一条插入 sql,类似这种 insert into user(username,address) values('aa','bb'),('cc','dd')...。
到底哪种快呢?
我们从两方面来考虑这个问题:
- 插入 SQL 本身执行的效率。
- 网络 I/O。
先说第一种方案,就是用 for 循环循环插入:
- 这种方案的优势在于,JDBC 中的 PreparedStatement 有预编译功能,预编译之后会缓存起来,后面的 SQL 执行会比较快并且 JDBC 可以开启批处理,这个批处理执行非常给力。
- 劣势在于,很多时候我们的 SQL 服务器和应用服务器可能并不是同一台,所以必须要考虑网络 IO,如果网络 IO 比较费时间的话,那么可能会拖慢 SQL 执行的速度。
再来说第二种方案,就是生成一条 SQL 插入:
- 这种方案的优势在于只有一次网络 IO,即使分片处理也只是数次网络 IO,所以这种方案不会在网络 IO 上花费太多时间。
- 当然这种方案有好几个劣势,一是 SQL 太长了,甚至可能需要分片后批量处理;二是无法充分发挥 PreparedStatement 预编译的优势,SQL 要重新解析且无法复用;三是最终生成的 SQL 太长了,数据库管理器解析这么长的 SQL 也需要时间。
所以我们最终要考虑的就是我们在网络 IO 上花费的时间,是否超过了 SQL 插入的时间?这是我们要考虑的核心问题。
2. 数据测试
接下来我们来做一个简单的测试,批量插入 5 万条数据看下。
首先准备一个简单的测试表:
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
`password` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
接下来创建一个 Spring Boot 工程,引入 MyBatis 依赖和 MySQL 驱动,然后 application.properties 中配置一下数据库连接信息:
spring.datasource.username=root
spring.datasource.password=123
spring.datasource.url=jdbc:mysql:///batch_insert?serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
- 1.
- 2.
- 3.
大家需要注意,这个数据库连接 URL 地址中多了一个参数 rewriteBatchedStatements,这是核心。
MySQL JDBC 驱动在默认情况下会无视 executeBatch() 语句,把我们期望批量执行的一组 sql 语句拆散,一条一条地发给 MySQL 数据库,批量插入实际上是单条插入,直接造成较低的性能。将 rewriteBatchedStatements 参数置为 true, 数据库驱动才会帮我们批量执行 SQL。
OK,这样准备工作就做好了。
2.1 方案一测试
首先我们来看方案一的测试,即一条一条的插入(实际上是批处理)。
首先创建相应的 mapper,如下:
@Mapper
public interface UserMapper {
Integer addUserOneByOne(User user);
}
- 1.
- 2.
- 3.
- 4.
对应的 XML 文件如下:
<insert id="addUserOneByOne">
insert into user (username,address,password) values (#{username},#{address},#{password})
</insert>
- 1.
- 2.
- 3.
service 如下:
@Service
public class UserService extends ServiceImpl<UserMapper, User> implements IUserService {
private static final Logger logger = LoggerFactory.getLogger(UserService.class);
@Autowired
UserMapper userMapper;
@Autowired
SqlSessionFactory sqlSessionFactory;
@Transactional(rollbackFor = Exception.class)
public void addUserOneByOne(List<User> users) {
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH);
UserMapper um = session.getMapper(UserMapper.class);
long startTime = System.currentTimeMillis();
for (User user : users) {
um.addUserOneByOne(user);
}
session.commit();
long endTime = System.currentTimeMillis();
logger.info("一条条插入 SQL 耗费时间 {}", (endTime - startTime));
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
这里我要说一下:
虽然是一条一条的插入,但是我们要开启批处理模式(BATCH),这样前前后后就只用这一个 SqlSession,如果不采用批处理模式,反反复复的获取 Connection 以及释放 Connection 会耗费大量时间,效率奇低,这种效率奇低的方式松哥就不给大家测试了。
接下来写一个简单的测试接口看下:
@RestController
public class HelloController {
private static final Logger logger = getLogger(HelloController.class);
@Autowired
UserService userService;
/**
* 一条一条插入
*/
@GetMapping("/user2")
public void user2() {
List<User> users = new ArrayList<>();
for (int i = 0; i < 50000; i++) {
User u = new User();
u.setAddress("广州:" + i);
u.setUsername("张三:" + i);
u.setPassword("123:" + i);
users.add(u);
}
userService.addUserOneByOne(users);
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
写个简单的单元测试:
/**
*
* 单元测试加事务的目的是为了插入之后自动回滚,避免影响下一次测试结果
* 一条一条插入
*/
@Test
@Transactional
void addUserOneByOne() {
List<User> users = new ArrayList<>();
for (int i = 0; i < 50000; i++) {
User u = new User();
u.setAddress("广州:" + i);
u.setUsername("张三:" + i);
u.setPassword("123:" + i);
users.add(u);
}
userService.addUserOneByOne(users);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.

可以看到,耗时 901 毫秒,5w 条数据插入不到 1 秒。
2.2 方案二测试
方案二是生成一条 SQL,然后插入。
mapper 如下:
@Mapper
public interface UserMapper {
void addByOneSQL(@Param("users") List<User> users);
}
- 1.
- 2.
- 3.
- 4.
对应的 SQL 如下:
<insert id="addByOneSQL">
insert into user (username,address,password) values
<foreach collection="users" item="user" separator=",">
(#{user.username},#{user.address},#{user.password})
</foreach>
</insert>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
service 如下:
@Service
public class UserService extends ServiceImpl<UserMapper, User> implements IUserService {
private static final Logger logger = LoggerFactory.getLogger(UserService.class);
@Autowired
UserMapper userMapper;
@Autowired
SqlSessionFactory sqlSessionFactory;
@Transactional(rollbackFor = Exception.class)
public void addByOneSQL(List<User> users) {
long startTime = System.currentTimeMillis();
userMapper.addByOneSQL(users);
long endTime = System.currentTimeMillis();
logger.info("合并成一条 SQL 插入耗费时间 {}", (endTime - startTime));
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
然后在单元测试中调一下这个方法:
/**
* 合并成一条 SQL 插入
*/
@Test
@Transactional
void addByOneSQL() {
List<User> users = new ArrayList<>();
for (int i = 0; i < 50000; i++) {
User u = new User();
u.setAddress("广州:" + i);
u.setUsername("张三:" + i);
u.setPassword("123:" + i);
users.add(u);
}
userService.addByOneSQL(users);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
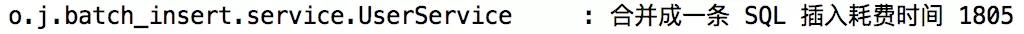
可以看到插入 5 万条数据耗时 1805 毫秒。
可以看到,生成一条 SQL 的执行效率还是要差一点。
另外还需要注意,第二种方案还有一个问题,就是当数据量大的时候,生成的 SQL 将特别的长,MySQL 可能一次性处理不了这么大的 SQL,这个时候就需要修改 MySQL 的配置或者对待插入的数据进行分片处理了,这些操作又会导致插入时间更长。
2.3 对比分析
很明显,方案一更具优势。当批量插入十万、二十万数据的时候,方案一的优势会更加明显(方案二则需要修改 MySQL 配置或者对待插入数据进行分片)。
3. MP 怎么做的?
小伙伴们知道,其实 MyBatis Plus 里边也有一个批量插入的方法 saveBatch,我们来看看它的实现源码:
@Transactional(rollbackFor = Exception.class)
@Override
public boolean saveBatch(Collection<T> entityList, int batchSize) {
String sqlStatement = getSqlStatement(SqlMethod.INSERT_ONE);
return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
可以看到,这里拿到的 sqlStatement 就是一个 INSERT_ONE,即一条一条插入。
再来看 executeBatch 方法,如下:
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {
Assert.isFalse(batchSize < 1, "batchSize must not be less than one");
return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, sqlSession -> {
int size = list.size();
int i = 1;
for (E element : list) {
consumer.accept(sqlSession, element);
if ((i % batchSize == 0) || i == size) {
sqlSession.flushStatements();
}
i++;
}
});
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
这里注意 return 中的第三个参数,是一个 lambda 表达式,这也是 MP 中批量插入的核心逻辑,可以看到,MP 先对数据进行分片(默认分片大小是 1000),分片完成之后,也是一条一条的插入。继续查看 executeBatch 方法,就会发现这里的 sqlSession 其实也是一个批处理的 sqlSession,并非普通的 sqlSession。
综上,MP 中的批量插入方案跟我们 2.1 小节的批量插入思路其实是一样的。
4. 小结
好啦,经过上面的分析,现在小伙伴们知道了批量插入该怎么做了吧?
本文转载自微信公众号「江南一点雨」,可以通过以下二维码关注。转载本文请联系江南一点雨公众号。



























