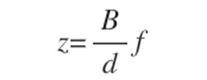神经网络可以学习解决各种问题,从识别照片中的猫到驾驶自动驾驶汽车。但这些强大的模式识别算法是否真正理解它们正在执行的任务仍然是一个悬而未决的问题。
例如,一个负责让自动驾驶汽车保持在车道上的神经网络可能会通过观察路边的灌木丛来学习如何做到这一点,而不是学习检测车道和关注道路的地平线。
近日,麻省理工学院的研究人员表明,当某种特定的神经网络被训练执行导航任务时,其能够理解该项任务真正的因果结构。由于这些网络可以直接从视觉数据中理解任务,因此在复杂环境(例如树木茂密的位置或快速变化的天气条件)中导航时,它们应该比其他神经网络更有效。
未来,这项工作可以提高执行高风险任务的机器学习代理的可靠性和可信度。如在繁忙高速公路上驾驶自动驾驶汽车。
研究成果以「 Causal Navigation by Continuous-time Neural Networks 」为题发表在预印本平台 arXiv 上。该研究将于今年 12 月在 「2021 年神经信息处理系统会议 (NeurIPS) 」上发表。
「因为这些机器学习系统能够以因果方式进行推理,我们可以知道并指出它们如何运作和做出决策的。这对于安全关键型应用至关重要,」共同主要作者、计算机科学与人工智能实验室 (CSAIL) 的博士后 Ramin Hasani 说。
因果学习模型 主要方法是图形方法,它试图将因果关系建模为有向图。对时间连续过程进行因果建模的一种方法是学习常微分方程 (ODE) 。在该研究中,描述了一类连续模型,它能够解释干预并因此从数据中捕获因果结构。
连续时间模型(Continuous-time Models)与离散化深度模型相比,连续时间(CT)模型显示出广泛的优势。它们可以通过高级 ODE 求解器实现的连续向量场执行自适应计算。它们在建模时间序列数据方面很强,并实现了内存和参数效率。
在这项工作中,研究人员证明了 CT 网络的一个重要属性:表明神经 ODE 的双线性近似可以产生富有表现力的因果模型。
连续时间网络是一类深度学习模型,其隐藏状态由连续 ODE 表示。
视觉导航 视觉导航认知映射和规划通过构建环境地图来解决学习从视觉输入流中导航的问题,并计划代理的行动以实现给定的目标。用于学习驾驶上下文的视觉导航已经广泛研究了因果混淆问题,以及模仿学习问题的泛化,通过使用模块从像素输入中提取有用的先验。这些方法可以从该研究中设计的基于液体时间常数网络 (liquid time-constant networks,LTC)的网络中受益。
一个引人注目的结果
神经网络是一种重要的机器学习技术,其中计算机通过分析许多训练示例,通过反复试验来学习完成任务。而「液体」神经网络会改变它们的基本方程,以不断适应新的输入。
这项新研究借鉴了先前的工作,其中 Hasani 和其他人展示了一种受大脑启发的深度学习系统,称为神经回路策略 (NCP),可以将感知模块中的数据转换为转向命令,仅包含 19 个神经元,比现有最好模型要小好几个数量级,能够自主控制自动驾驶车辆。
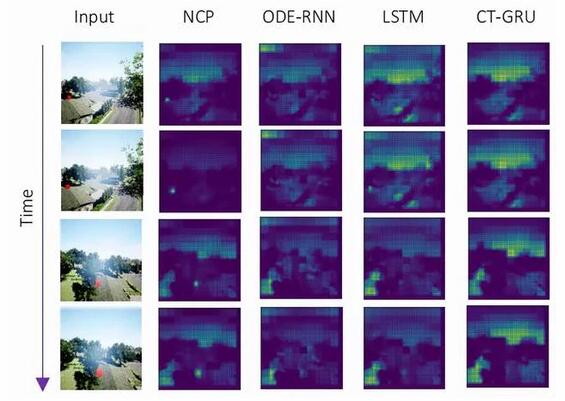
图示:来自原始视觉输入的因果导航。(来源:论文)
研究人员观察到,执行车道保持任务的 NCP 在做出驾驶决定时将注意力集中在道路的地平线和边界上,就像人类驾驶汽车时一样。他们研究的其他神经网络并不总是专注于道路。
「这是一个很酷的观察,但我们没有对其进行量化。因此,我们想找出这些网络为何以及如何能够捕获数据的真正因果关系的数学原理,」Hasani 说。
研究人员发现,当 NCP 被训练完成一项任务时,网络学习与环境交互并解释干预。本质上,网络识别其输出是否因某种干预而改变,然后将因果关系联系在一起。
在训练期间,网络向前运行以生成输出,然后向后运行以纠正错误。研究人员观察到,NCP 在前向模式和后向模式期间关联因果关系,这使网络能够非常关注任务的真实因果结构。
Hasani 和他的同事不需要对系统施加任何额外的限制,也不需要为 NCP 执行任何特殊设置来了解这种因果关系。
「因果关系对于飞行等安全关键应用的表征尤为重要,」Rus 说。「我们的工作证明了用于飞行决策的神经回路策略的因果关系特性,包括在具有密集障碍物的环境中飞行,如森林和编队飞行。」
NCP 在不同环境下执行导航任务
他们通过一系列模拟测试 NCP,其中自主无人机执行导航任务。每架无人机都使用来自单个摄像头的输入进行导航。无人机的任务是前往目标物体、追逐移动目标或在不同环境(包括红杉林和社区)中跟踪一系列标记。他们还在不同的天气条件下旅行,如晴朗的天空、大雨和大雾。
研究人员设计了具有不同记忆范围的逼真视觉导航任务,包括 (1) 导航到静态目标,(2) 追逐移动目标,以及 (3) 使用引导标记「徒步旅行」(hiking)。
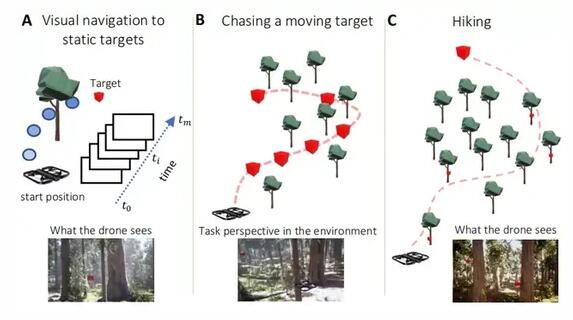
图示:视觉无人机导航任务。(来源:论文)
研究人员选择一组基线模型评估 NCP 网络。包括 ODERNNs、长短期记忆网络 (LSTMs) 和 CT-GRU 网络。
使用遮挡导航到静态目标 研究人员观察到 NCP 已经学会了注意其视野内的静态目标以做出未来的决定。与 CT 模型相比,LSTM 代理对光照条件敏感。NCP 是唯一可以直接从视觉数据中捕获任务因果结构的模型。

图示:在闭环环境中导航到静态目标。(来源:论文)
追逐移动目标 并非所有模型都能在干预发挥重要作用的闭环环境中成功完成任务。NCP 完成任务的成功率为 78%,而 LSTM 为 66%,ODE-RNN 为 52%,CT-GRU 为 38%。相比之下,NCP 已经学会了关注目标,并在它们在环境中移动时跟随它们。

图示:在闭环环境中追逐移动目标。NCP 是唯一可以直接从视觉数据中捕获任务因果结构的模型。(来源:论文)
在环境中「徒步旅行」 在此任务中,无人机跟随放置在环境中障碍物表面的多个目标标记。这个任务比之前的任务复杂得多。
研究人员观察到大多数代理在学习过程中学习了合理程度的验证损失。即使是 ODE-RNN 在被动设置中也实现了出色的性能。但是,在环境中部署时,除了 NCP 之外的任何模型都无法在 50 次运行中完全执行任务。由于其因果结构,NCP 可以成功执行 30%。
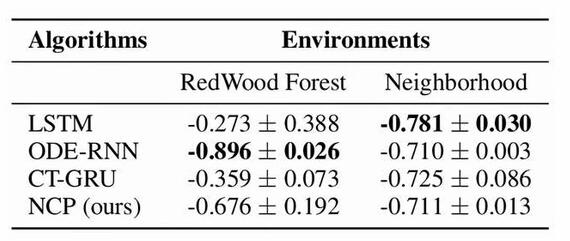
「我们观察到,NCP 是唯一一个在完成导航任务的同时,在不同环境中关注感兴趣对象的网络,无论你在哪里测试,以及在不同的照明或环境条件下。这是唯一可以随意执行此操作并实际学习我们希望系统学习的行为的系统,」Hasani 说。
「一旦系统了解了它实际应该做什么,它就可以在它从未经历过的新场景和环境条件下表现良好。这是当前非因果机器学习系统的一大挑战。我们相信这些结果非常令人兴奋,因为它们展示了如何从神经网络的选择中产生因果关系,」他说。
未来,研究人员希望探索使用 NCP 来构建更大的系统。将数千或数百万个网络放在一起,可以使他们处理更复杂的任务。
论文链接:https://arxiv.org/abs/2106.08314