本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
CLIP大家都不陌生吧?
由OpenAI于今年1月份推出,能够实现文本描述与图片的精准匹配。
现在,有人“灵机一动”,从CLIP中学习了一种音频表示方法。
用这个方法搭配VQGAN-CLIP,就能实现声音到图像的转变!
比如给它听4种不同的青蛙叫,它就能生成4种青蛙的照片:

给它听不同的教堂铃声,就能生成下面这样的图像:

嗯,画风有点诡异,仿佛看到了还未被完全驯服的AI的内心世界……
不过这是不是还挺有意思?
那同样都使用VQGAN-CLIP,到底是用文字生成还是用这种音频表示的生成效果更好呢?
这也有一张对比图片:

第一行是VQGAN-CLIP根据文字生成的图片,第二行是根据音频。从左到右分别为:街头音乐、狗叫、小孩玩耍、枪击声。
你觉得哪个更像?
目前,关于这个音频表示方法的研究已被国际声学、语音与信号处理顶会ICASSP接收。

所以,一个音频是怎么和图像连接起来的呢?
从CLIP中提取音频表示方法
下面就来看看这个音频表示方法有何特殊之处。
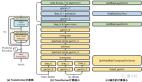
方法名叫Wav2CLIP,从下图我们可以看出它和CLIP的模型架构非常像。

作为视听(audio-visual)对应模型,Wav2CLIP也有两个编码器,一个是冻结图像编码器(Frozen Image Encoder),一个是音频编码器,分别从视频中提取图像和音频数据进行训练。
冻结图像编码器通过冻结CLIP的图像编码器获得,也就是将CLIP视觉模型的图结构和权重固化到一起后直接加载运行。
音频编码器的预训练通过提取视频中CLIP图像的embedding完成,这也是Wav2CLIP的前置(pretext)任务。
按照CLIP论文的原始方法,研究人员采用对比损失(contrastive loss)进行特征提取,并添加多层感知器(MLP)作为投影层。
交叉投影的损失函数定义如下:

△ f/g:投影函数,L:对比损失函数
添加MLP层的好处有两个:
一是有助于稳定提取过程;
二是能够加强多模态的一致性,因为模型学习到的音频embedding能通过这个投影层恢复CLIP图像的embedding。
总的来说,Wav2CLIP的训练数据为一段视频,利用CLIP的图像编码器(freeze操作)对音频图片和音频进行特征提取,就可以生成“明白”自己应该对应什么图片的音频表示。
所以反过来也可以根据这种表示推出图片,就像我们在开头看到的“青蛙”和“教堂铃声”一样。
具体方法就是通过把引导VQGAN在潜空间中查找与文本提示匹配的图像的CLIP embeddings,替换成Wav2CLIP音频embeddings而完成。
由于Wav2CLIP不同于以往的视听对应模型,它不需要将视觉模型与听觉模型结合起来学习,所以训练方法也就非常轻量级。
再加上Wav2CLIP的embeddings源于CLIP,这意味着它们是与文字对齐的。
所以经过额外层的训练,Wav2CLIP也能执行零样本音频分类、音频字幕和跨模态检索(根据文本搜索音频)等下游任务。
下游任务性能比较
在实验评估中,Wav2CLIP采用ResNet-18的架构作为音频编码器。
首先来看Wav2CLIP在分类和检索任务上的性能。

- 与非SOTA的音频表示模型相比,Wav2CLIP在几乎所有分类和检索任务中的性能都比YamNet和OpenL3略强,不是最强的地方,表现和第一名差别也不大。
具体在检索任务上,对于音频检索(AR),可以看到Wav2CLIP作为帧级特征提取器的性能很有竞争力。
对于跨模态检索(CMR)任务,Wav2CLIP达到了0.05 MRR,这意味着它能够从前20个音频中检索出正确结果,比OpenL3好不少。
- 与SOTA模型相比,仍有改进的余地。
不过也情有可原,因为对于大多数SOTA模型来说,编码器在每个任务上都经过专门的训练或微调,而Wav2CLIP只用冻结特征提取器,并且只训练简单的MLP分类器输出答案,也就是所有任务都采用的是同一个音频编码器。
再看在音频字幕任务中与基线比较的结果:
所有指标都略优于基线。
不过作者表示,这不是一个公平的比较,因为他们的编码器和解码器架构都不同,但他们想表明的是:Wav2CLIP很容易适应不同的任务,并且仍然具有合理的性能。

最后再来看一下Wav2CLIP与OpenL3和YamNet使用不同百分比的训练样本进行VGGSound音频分类的结果(VGGSound包含309种10s的YouTube视频)。
可以发现Wav2CLIP碾压OpenL3,和YamNet不相上下——使用10%的训练数据就能达到相同性能。
不过Wav2CLIP和YamNet预训练的前置任务非常不同,YamNet需要大量的标记数据,Wav2CLIP在完全没有人工注释的情况下完成预训练,所以Wav2CLIP更易于扩展。

总的来说,这种音频表示方法进一步训练的模型在上面这3种任务上都能表现出与同类相媲美或更高的性能。
在未来工作方面,研究人员表示将在Wav2CLIP上尝试各种专门为多模态数据设计的损失函数和投影层,并探索从共享embedding空间生成音频,以实现从文本或图像到音频的跨模态生成。
论文地址:
https://arxiv.org/abs/2110.11499
开源代码:
https://github.com/descriptinc/lyrebird-Wav2CLIP
更多音频转图像的demo欣赏:
https://descriptinc.github.io/lyrebird-wav2clip