【51CTO.com快译】介绍
我们在本项目中将学习如何用简单的代码为您的机器学习模型构建应用编程接口(API)并加以部署。我花了1小时学习FastAPI,花了5分钟学习如何部署到Deta服务器。我们还将使用Python Request在本地服务器和远程服务器上测试API。不妨更深入地了解我们将在项目中使用的这些技术。
spaCy
与用于试验和评估的著名NLTK Python库相比,spaCy对应用程序和部署更友好。spaCy 带有预构建的统计神经网络NLP模型,有强大的功能,易于在您的项目spaCy中使用和实现。我们将使用一个很简单的小型预构建英文模型从我们的文本提取实体。
FastAPI
FastAPI是一个使用Python构建API的快速Web框架,它有更短的查询时间、简单且代码最小化,让您在几分钟内即可用FastAPI设计第一个API。我们将学习FastAPI的工作原理以及如何使用预构建模型从英文文本获取实体。
Deta
我们将为API使用Deta Micros服务,并在没有Docker或YAML文件的情况下部署项目。Deta平台拥有易于部署的CLI、高可扩展性、安全的API身份验证密钥、更改子域的选项以及Web流量日志功能。这些功能在Deta上可以完全免费使用。我们在项目中将使用Deta CLI,仅用几行脚本来部署Fast API。
代码
我在学习FastAPI时偶然发现了促使我写本文的YouTube视频。Sebastián Ramírez 解释了Fast API的工作原理以及它如何成为最快速的Python Web框架。我们将编写两个Python 文件,一个含有机器学习模型,另一个含有您的API代码。
需求
我们在开始之前,需要创建一个含有requirements.txt文件的新目录。您可以在下面找到我们将要使用的所有必要库:
- fastapi
- spacy
- uvicorn
- https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.1.0/en_core_web_sm-3.1.0.tar.gz
您可以逐一安装,或者使用:
- $ pip install -r requirements.txt
我们将为该项目使用预训练的NLP模型,因此需要从GitHub存储库下载,或者只运行需求文件,它会自动下载并安装。
机器学习模型
我们将使用预训练的Spacy NLP模型从文本提取实体。如果您使用Jupyter notebook,尝试使用%%writefile 在您的目录中创建python文件。
首先加载NLP模型,然后从CBS 新闻文章提取实体。只需几行代码,您就可以运行第一个机器学习模型。还可以使用相同的方法加载经过训练的模型。
API文件
这是您的主文件,该文件含有:
1. read_main:使用GET,即从资源请求数据,它会显示一条欢迎消息。
2. 类Article:使用pydantic BaseModel来定义将用于您的API (helpmanual.io)的对象和变量。在本例中,我们将内容定义为字符串,将评论定义为字符串列表。
3. analyze_article:它使用来自ml文件的NLP对象,获取附有评论的文本列表,并显示实例。
我知道这让人有点困惑,不妨分解成几个小部分以便了解。
- %%writefile FastAPI-ML-Project/main.py
- from fastapi import FastAPI
- from ml import nlp
- from pydantic import BaseModel
- import starlette
- from typing import List
分解
我们创建了FastAPI的对象,然后使用@app. get(“/”),把它用作函数上的装饰器。
- @app是FastAPI对象的装饰器
- .get or .post:用于返回数据或处理输入的HTTP方法
- (“/”)是Web服务器上的位置,本例中是主页面。如果您想添加另一个目录,可以使用 (“/
/”)
我们创建了read_main函数显示主页上的消息,这很简单。
- app = FastAPI()
- @app.get("/")
- def read_main():
- return {"message": "Welcome"}
现在我们将创建从BaseModel继承函数和变量的Article类。该函数帮助我们创建将在POST方法中使用的参数类型。在本例中,我们将内容创建为字符串变量,将评论创建为字符串列表。
- class Article(BaseModel):
- content: str
- comments: List[str] = []
在最后一部分,我们为API创建了POST方法(“/article/”)。这意味着我们将创建一个新部分,该部分将参数作为输入并在处理后返回结果。
- Article类作为参数:使用Article列表创建文章参数,这将让我们可以添加多个文本条目。
- 从文章提取数据:创建循环先后从文章列表和评论列表提取数据。它还向数组添加评论。
- 将文本加载到NLP模型中:将内容加载到NLP预训练模型中。
- 提取实体:从nlp对象提取实体,然后添加到ents 数组中。这将堆叠结果。
- Display:该函数将返回实体和评论列表。
- @app.post("/article/")
- def analyze_article(articles: List[Article]):
- ents = []
- comments = []
- for article in articles:
- for comment in article.comments:
- comments.append(comment.upper())
- doc = nlp(article.content)
- for ent in doc.ents:
- ents.append({"text": ent.text, "label": ent.label_})
- return {"ents": ents, "comments": comments}
测试
Fast API建立在Uvicorn上,因此服务器也运行在Uvicorn上。在Jupyter notebook中,您可以使用以下代码运行应用程序,或在终端中输入uvicorn,然后输入main文件,其中FastAPI对象是本例中的 app。
- !cd /work/FastAPI-ML-Project && uvicorn main:app
- 2021-08-04 17:08:56.673584: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
- 2021-08-04 17:08:56.673627: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
- China GPE
- Beijing GPE
- INFO: Started server process [928]
- INFO: Waiting for application startup.
- INFO: Application startup complete.
- INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
- INFO: 127.0.0.1:51874 - "GET / HTTP/1.1" 200 OK
- INFO: 127.0.0.1:51876 - "POST /article/ HTTP/1.1" 200 OK
- INFO: 127.0.0.1:53028 - "POST /article/ HTTP/1.1" 200 OK
- KernelInterrupted: Execution interrupted by the Jupyter kernel.
我们的服务器运行流畅,于是不妨使用request.get方法来访问它。API在主页上显示“欢迎”消息,表明一切正常。
- import requests
- response = requests.get("http://127.0.0.1:8000")
- print(response.text)
- {"message":"Welcome"}
现在不妨在列表中添加单个文本和评论作为字典。我们将使用POST请求方法和/article/来访问NLP模型函数。将您的输出转换成.json() ,以便易于提取数据。
我们有字典键:['ents','comments']
- params = [{"content":"The 1992 Cricket World Cup was won by Pakistan",
- "comments":["waooo","not bad"]}]
- article = requests.post(f"http://127.0.0.1:8000/article/",json=params)
- data_dict = article.json()
- data_dict.keys()
不妨查看一下整个输出是什么样的。看起来我们有带有标签和实体列表的ents。comments键也一样。
- print("Output: ",article.text)
- Output: {"ents":[{"text":"1992","label":"DATE"},{"text":"Cricket World Cup","label":"EVENT"},{"text":"Pakistan","label":"GPE"}],"comments":["WAOOO","NOT BAD"]}
现在不妨提取单个实体及其文本,检查输出的灵活性。在本例中,我们从输出提取第二个实体。
结果显示完美。
- print("Label: ",list(data_dict["ents"][1].values())[1])
- print("Text: ",list(data_dict["ents"][1].values())[0])
- Label: EVENT
- Text: Cricket World Cup
部署
进入到终端,或者您可以在Jupyter notebook单元中执行相同的步骤,不过在任何脚本之前添加“!”。先要使用cd访问main.py和 ml.py文件所在的目录。
- cd ~”/FastAPI-ML-Project”
Deta需要的三个主文件是ml.py、main.py 和requirments.txt。

如果您使用Windows,在 PowerShell 中使用bellow命令下载并安装Deta CLI:
- iwr https://get.deta.dev/cli.ps1 -useb | iex
如果使用Linux:
- curl -fsSL https://get.deta.dev/cli.sh | sh
然后使用deta login,会将您带到浏览器,要求您输入username和password。如果您已登录,需要几秒钟来验证。
- deta login

Deta验证 | deta
终端中的这两个词是魔法词,会在2分钟内上传文件并部署您的应用程序。
- deta new
您的应用程序已上传到端点链接,本例中是https://93t2gn.deta.dev/。
- Successfully created a new micro{“name”: “FastAPI-ML-Project”,“runtime”: “python3.7”,“endpoint”: “https://93t2gn.deta.dev/",“visor”: “enabled”,“http_auth”: “disable”}Adding dependencies…Collecting fastapi…Successfully installed ……
如果您使用deta logs看到错误检查日志,作出一些更改,然后使用deta deploy来更新更改。
如您所见,我们的应用程序已部署在Deta服务器上并运行。
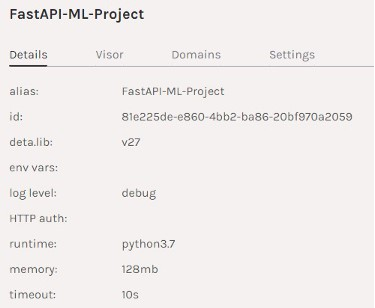
项目摘要| deta
您可以进入到Deta提供的链接,自行检查。

测试 Web API
最后不妨在Deta平台上将我们的远程API作为微服务来测试。这次我们将添加Deta端点链接,而不是添加本地IP。可以在没有标头的情况下运行,因为我们没有启用API身份验证。启用身份验证后,Deta还提供免费的API密钥。这意味着只有您或拥有API密钥的人才能访问Web服务器。想了解有关身份验证和子域的更多信息,建议查阅文档。
我们将添加相同的参数和相同的代码以获得相同的结果,瞧它多神奇。您的API在网上,可以通过使用链接即可轻松访问。
- header = {"accept": "application/json", "Content-Type": "application/json"}
- params = [
- {
- "content": "The 1992 Cricket World Cup was won by Pakistan",
- "comments": ["waooo", "not bad"],
- }
- ]
- article = requests.post("https://93t2gn.deta.dev/article/",headers=header ,json=params)
结论
我在学习FastAPI后考虑下一步做什么,于是有一天我在网上偶然发现了引起我注意的 Deta。我花了几分钟来安装Deta CLI,并在远程服务器上部署API。Deta的子域和免费API密钥功能给我留下了深刻印象。我很快了解了该服务的工作原理以及我将如何在未来的项目中使用它。
在学习几个机器学习模型之后,我们都会问这个问题:
我知道如何训练我的模型并获得预测,但下一步是什么?如何与他人分享我的模型,以便他们可以看到我构建的内容并在他们的项目中使用这些功能?
这时候Heroku、Google或Azure等云平台有了用武之地,但这些平台有点复杂,您需要学习为Docker文件编写代码,这有时令人沮丧。Deta用简单的两个字脚本解决您的所有问题,脚本在几秒钟内即可部署和运行您的应用程序。
原文标题:Deploying Your First Machine Learning API,作者:Abid Ali Awan
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】