大家好,我是才哥。
前段时间,菜市场出现了一个奇特的现场:菜比肉贵!
以北京为例,像猪肉的价格基本上从年初的25块/斤逐步下降到现在的10块/斤。
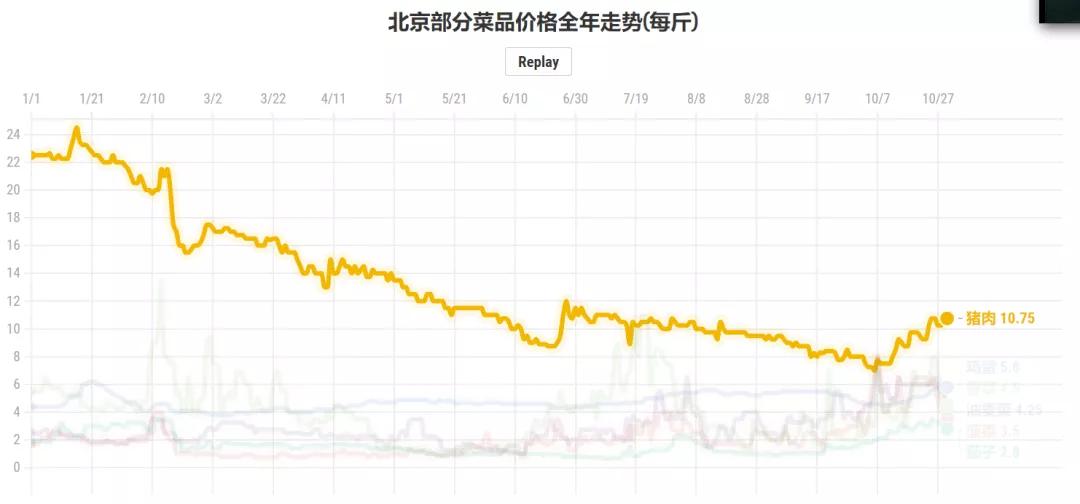
猪肉价格走势
而一些蔬菜比如油麦菜从年初的2.5元/斤到现在的4.5元/斤,高的时候能有8元/斤;再比如菠菜从年初的1.7元/斤到现在的4元/斤,高的时候也能到7-8元/斤。
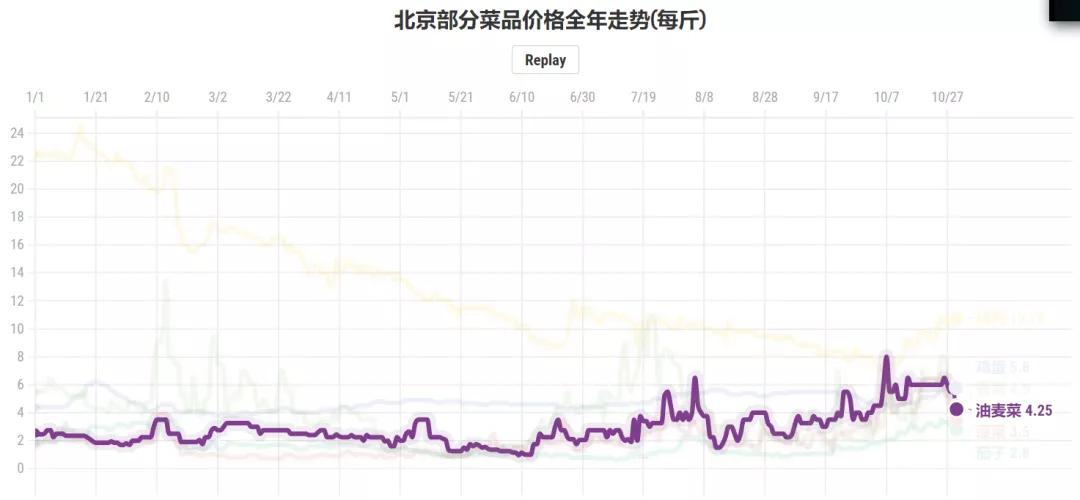
油麦菜价格走势
广大网友直呼:以前没钱吃肉,现在没钱吃菜!
我们知道前年 50块一斤猪肉(也是离谱),现在可以买5斤,于是就有了下面这张对比图:

以前没钱吃肉,现在没钱吃菜
那么,蔬菜价格目前到底是什么情况呢?全年一般又是什么样的走势呢?
今天,我们就用Python采集一下北京新发地菜市场的价格行情来一起了解下!
1. 网页分析
目标网站:北京新发地
网址信息:http://www.xinfadi.com.cn/priceDetail.html
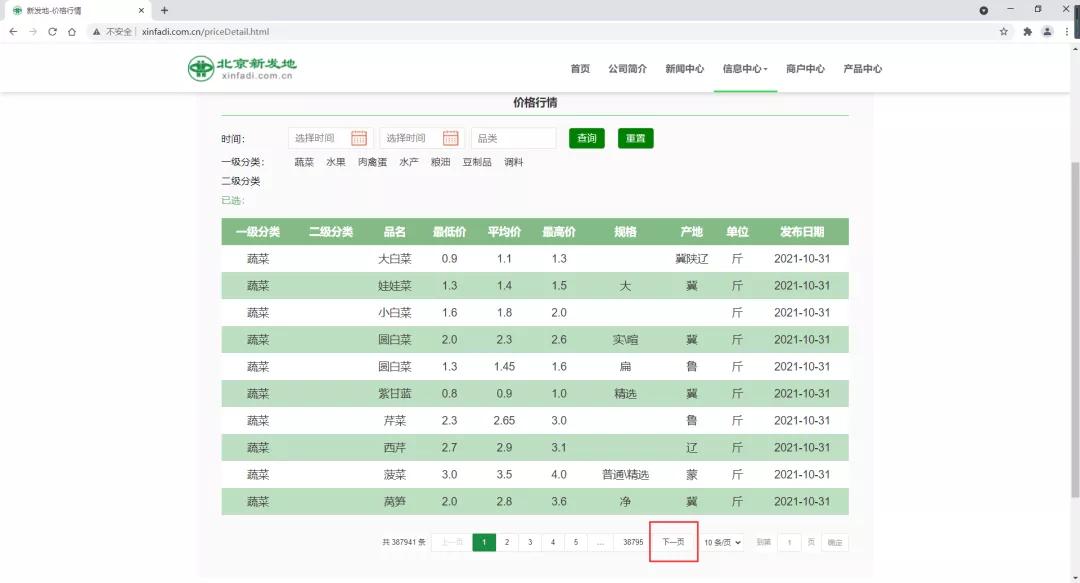
我们通过翻页(下一页)查看后续数据,但是发现地址栏url没变,所以是动态加载的,那么老规矩:F12开发者模式—>Network—>XHR,然后翻页可以找到数据请求信息如下:
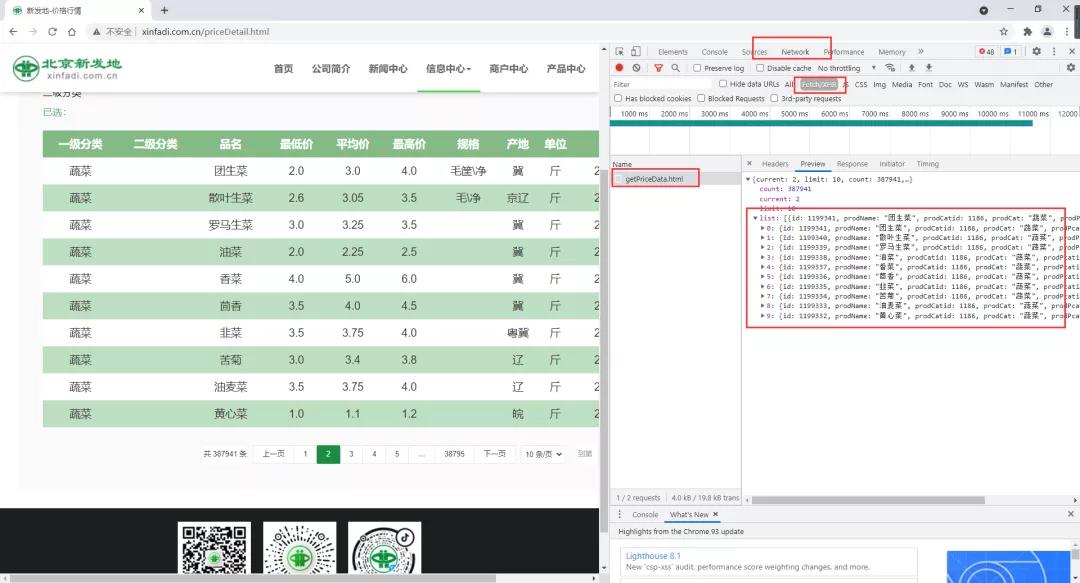
最终,我们确认请求接口地址及请求方式与信息如下:
请求类型:post
- url = r'http://www.xinfadi.com.cn/getPriceData.html'
- # 请求参数如下,其中page为页码
- FormData={
- 'limit': 20,
- 'current': page,
- 'pubDateStartTime': '2021/01/01',
- 'pubDateEndTime': '2021/10/30',
- 'prodPcatid':'',
- 'prodCatid':'',
- 'prodName':'',
- }
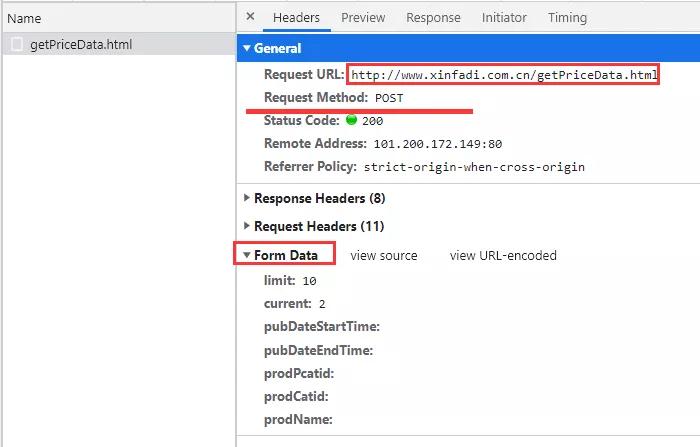
确定以上信息后,我们就可以简单的写代码进行数据采集了!
2. 数据采集
由于请求到的数据是json格式,比较好处理,我们直接上代码(完整代码)。
如果对代码不是很了解,可以加笔者好友或者加咱们交流群讨论!
- import requests
- import pandas as pd
- from tqdm import tqdm
- headers = {
- "Accept-Encoding": "Gzip",
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
- }
- dfList = []
- url = r'http://www.xinfadi.com.cn/getPriceData.html'
- for page in tqdm(range(1,5373)):
- FormData={
- 'limit': 20,
- 'current': page,
- 'pubDateStartTime': '2021/01/01',
- 'pubDateEndTime': '2021/10/30',
- 'prodPcatid':'',
- 'prodCatid':'',
- 'prodName':'',
- }
- r = requests.post(url, data=FormData, headers=headers)
- data = r.json()
- dataList = data['list']
- df = pd.DataFrame(dataList)
- dfList.append(df)
- df = pd.concat(dfList)
- df.to_excel(r'菜品历史价格行情.xlsx',index=None)
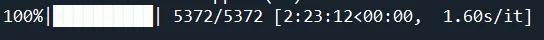
采集进度
可以看到,其实该网站并没有反爬,但是我们用最简单的这种采集方式花了2小时23分钟,属实有点久。
那么怎么可以加速呢?进程、线程与携程等方式可以加速,关于这方面的知识与应用我们会在后续进行专题介绍哈,这里先预告一下。
最终,我们采集到10万多条数据如下:
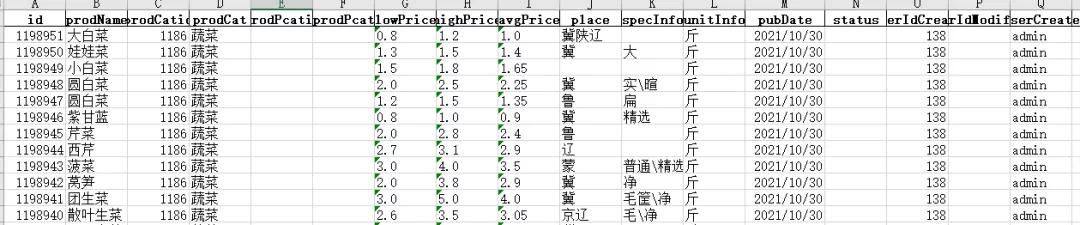
数据预览
以上就是本次全部内容,由于菜品类型较多,这里不做展开处理,大家可以自行下载研究哈。