Eslint 是我们每天都在用的工具,我们会用它的 cli 或 api 来做代码错误检查和格式检查,有时候也会写一些 rule 来做自定义的检查和修复。
虽然每天都用,但我们却很少去了解它是怎么实现的。而了解 Eslint 的实现原理能帮助我们更好的使用它,更好的写一些插件。
所以,这篇文章我们就通过源码来探究下 Eslint 的实现原理吧。
Linter
Linter 是 eslint 最核心的类了,它提供了这几个 api:
verify // 检查
verifyAndFix // 检查并修复
getSourceCode // 获取 AST
defineParser // 定义 Parser
defineRule // 定义 Rule
getRules // 获取所有的 Rule
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
SourceCode 就是指的 AST(抽象语法树),Parser 是把源码字符串解析成 AST 的,而 Rule 则是我们配置的那些对 AST 进行检查的规则。这几个 api 比较容易理解。
Linter 主要的功能是在 verify 和 verifyAndFix 里实现的,当命令行指定 --fix 或者配置文件指定 fix: true 就会调用 verifyAndFix 对代码进行检查并修复,否则会调用 verify 来进行检查。
那 verify 和 fix 是怎么实现的呢?这就是 eslint 最核心的部分了:
确定 parser
我们知道 Eslint 的 rule 是基于 AST 进行检查的,那就要先把源码 parse 成 AST。而 eslint 的 parser 也是可以切换的,需要先找到用啥 parser:
默认是 Eslint 自带的 espree,也可以通过配置来切换成别的 parser,比如 @eslint/babel-parser、@typescript/eslint-parser 等。
下面是 resolve parser 的逻辑:
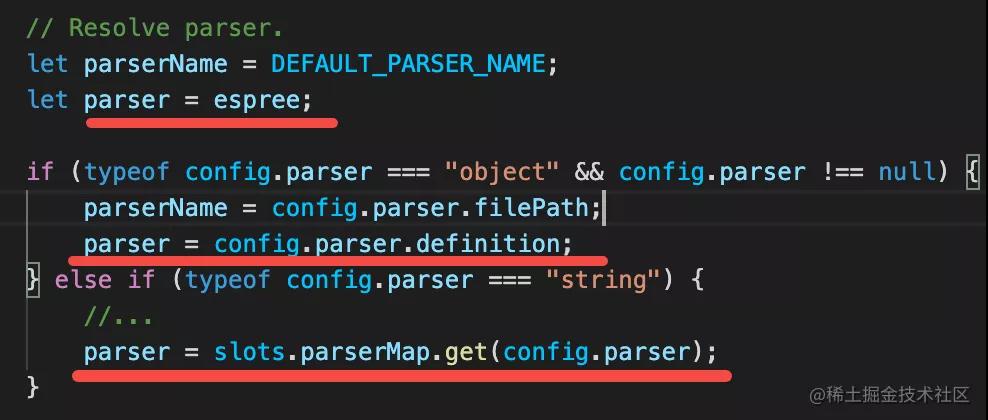
确定了 parser 之后,就是调用 parse 方法了。
parse 成 SourceCode
parser 的 parse 方法会把源码解析为 AST,在 eslint 里是通过 SourceCode 来封装 AST 的。后面看到 SourceCode 就是指 AST.
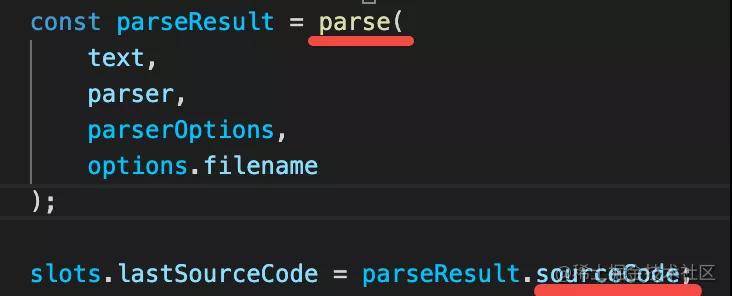
有了 AST,就可以调用 rules 对 AST 进行检查了
调用 rule 对 SourceCode 进行检查,获得 lintingProblems
parse 之后,会调用 runRules 方法对 AST 进行检查,返回结果就是 problems,也就是有什么错误和怎么修复的信息。
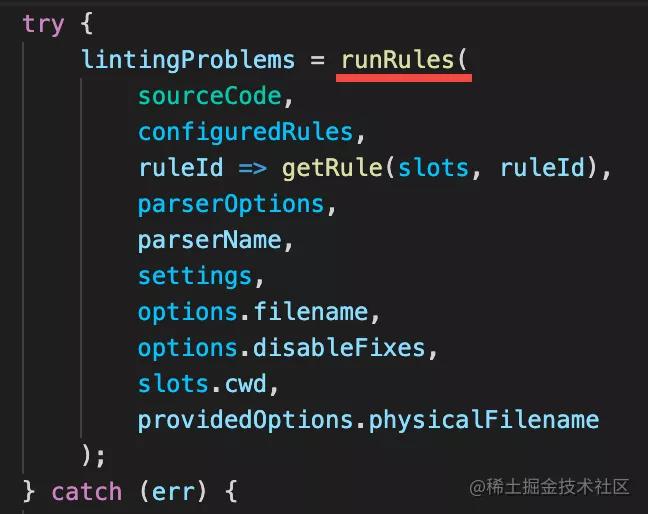
那 runRules 是怎么运行的 rule 呢?
rule 的实现如下,就是注册了对什么 AST 做什么检查,这点和 babel 插件很类似。
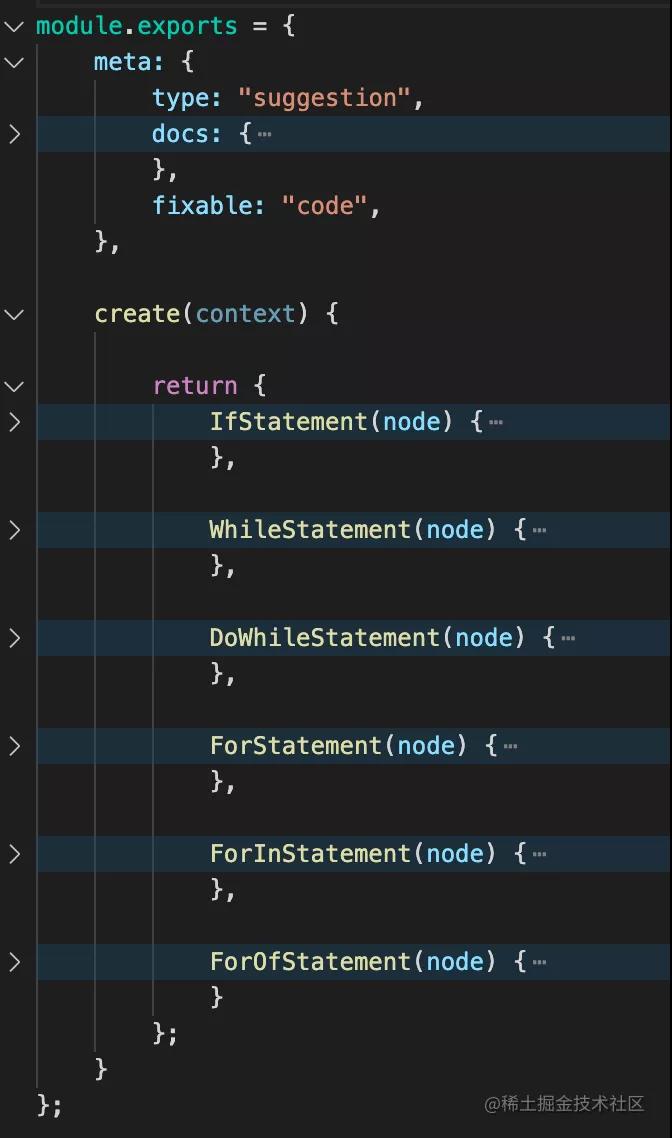
runRules 会遍历 AST,然后遇到不同的 AST 会 emit 不同的事件。rule 里处理什么 AST 就会监听什么事件,这样通过事件监听的方式,就可以在遍历 AST 的过程中,执行不同的 rule 了。
注册 listener:
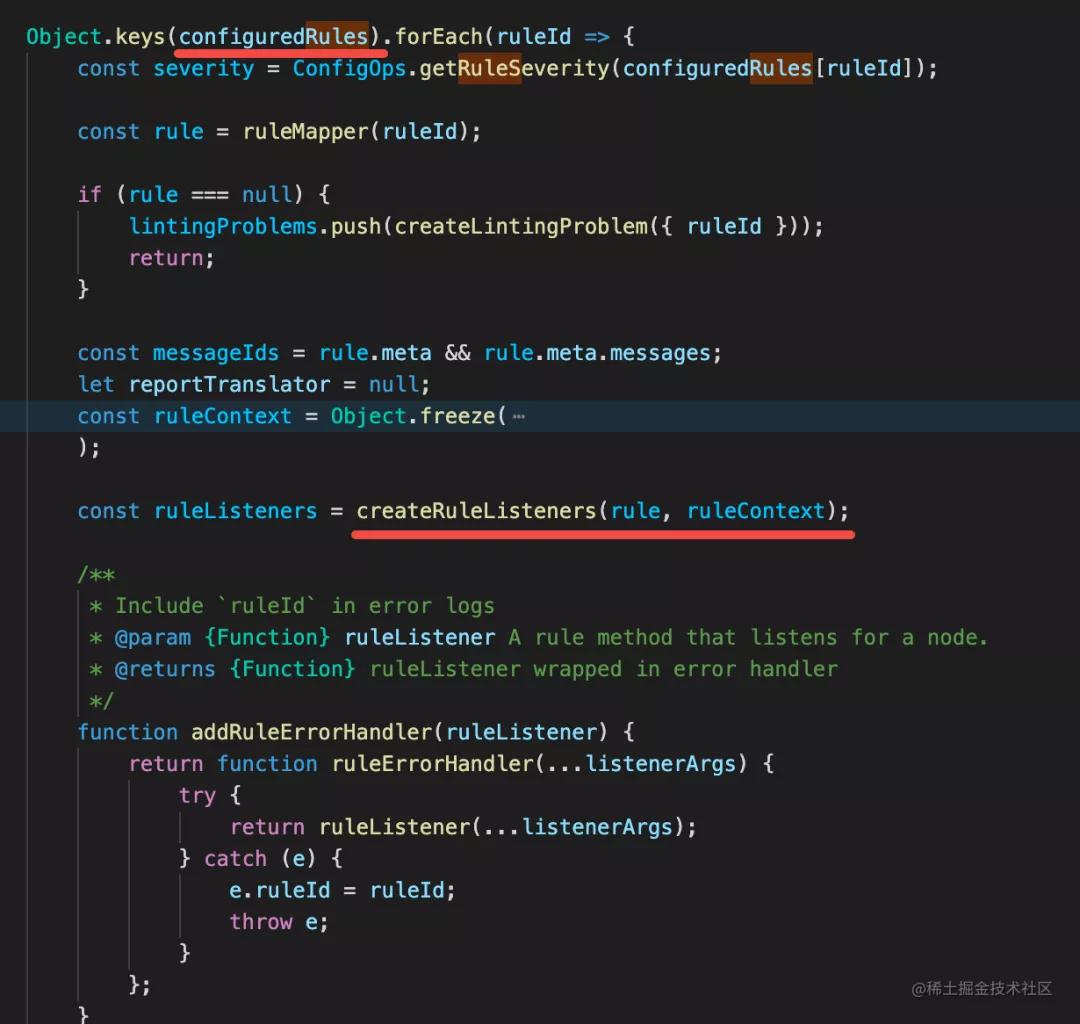
遍历 AST,emit 不同的事件,触发 listener:
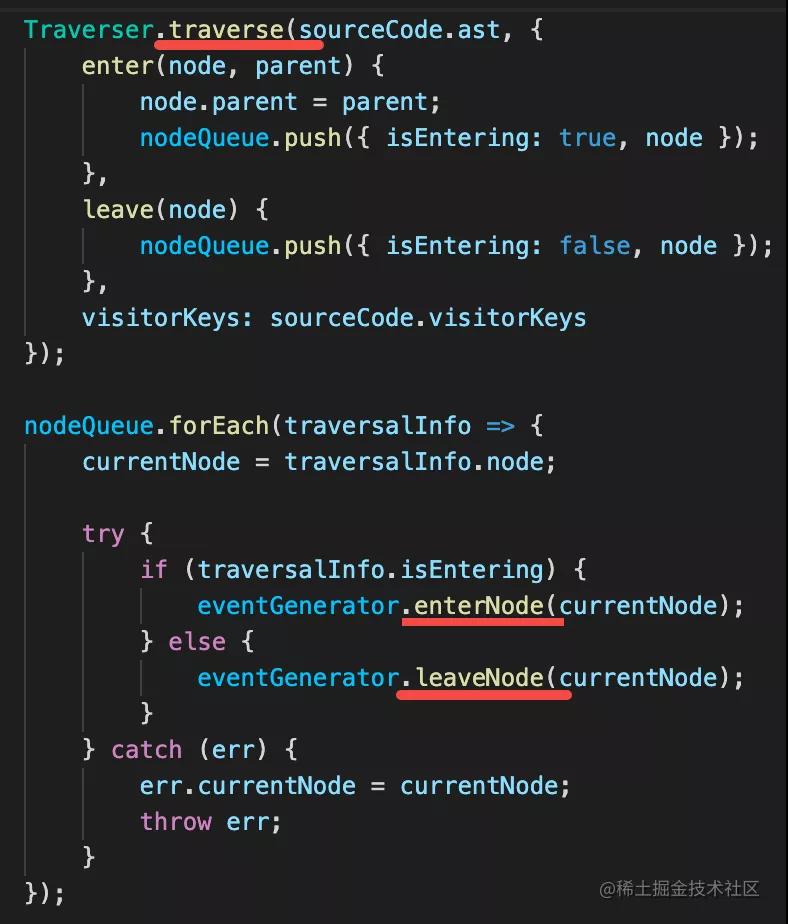
这样,遍历完一遍 AST,也就调用了所有的 rules,这就是 rule 的运行机制。
还有,遍历的过程中会传入 context,rule 里可以拿到,比如 scope、settings 等。
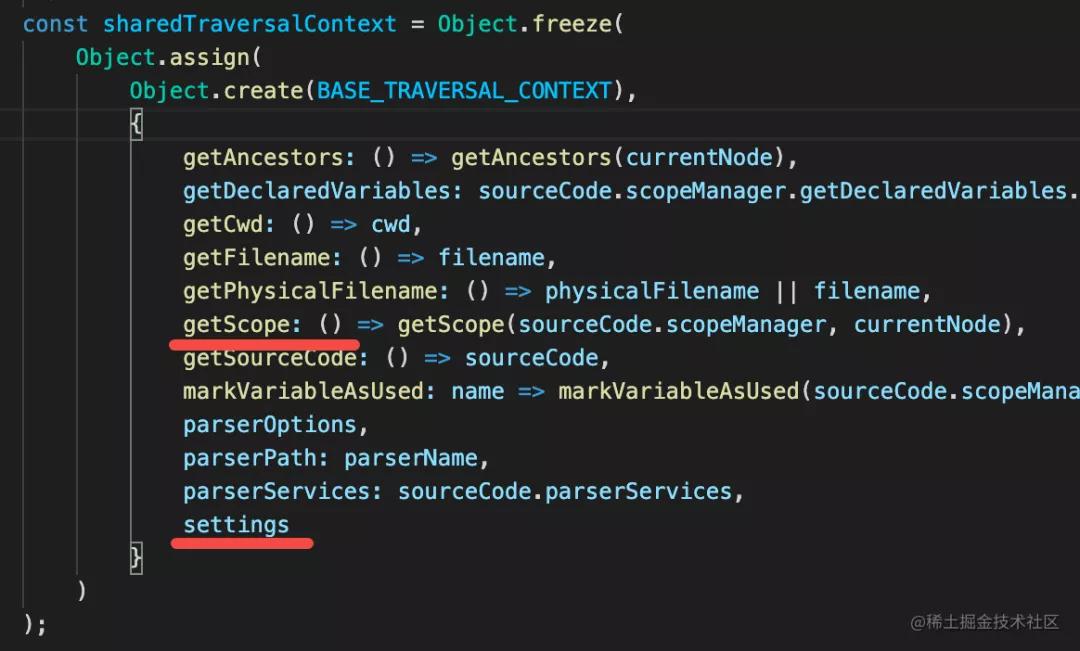
还有 ruleContext,调用 AST 的 listener 的时候可以拿到:
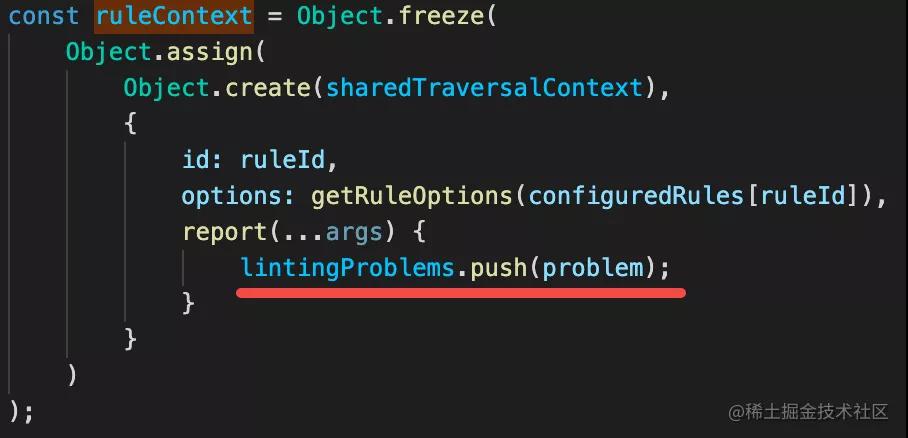
而 rule 里面就是通过这个 report 的 api 进行报错的,那这样就可以把所有的错误收集起来,然后进行打印。
这个 problem 是什么呢?
linting problem
lint problem 是检查的结果,也就是从哪一行(line)哪一列(column)到哪一行(endLine)哪一列(endColumn),有什么错误(message)。
还有就是怎么修复(fix),修复其实就是 从那个下标到哪个下标(range),替换成什么文本(text)。
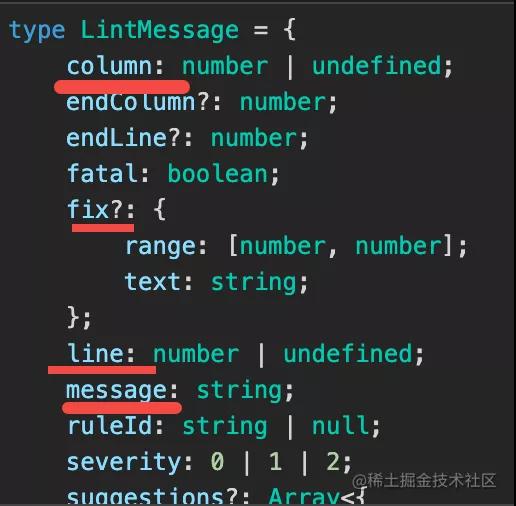
为什么 fix 是 range 返回和 text 这样的结构呢?因为它的实现就是简单的字符串替换。
通过字符串替换实现自动 fix
遍历完 AST,调用了所有的 rules,收集到了 linting problems 之后,就可以进行 fix 了。
fix 部分的相关源码是这样的:
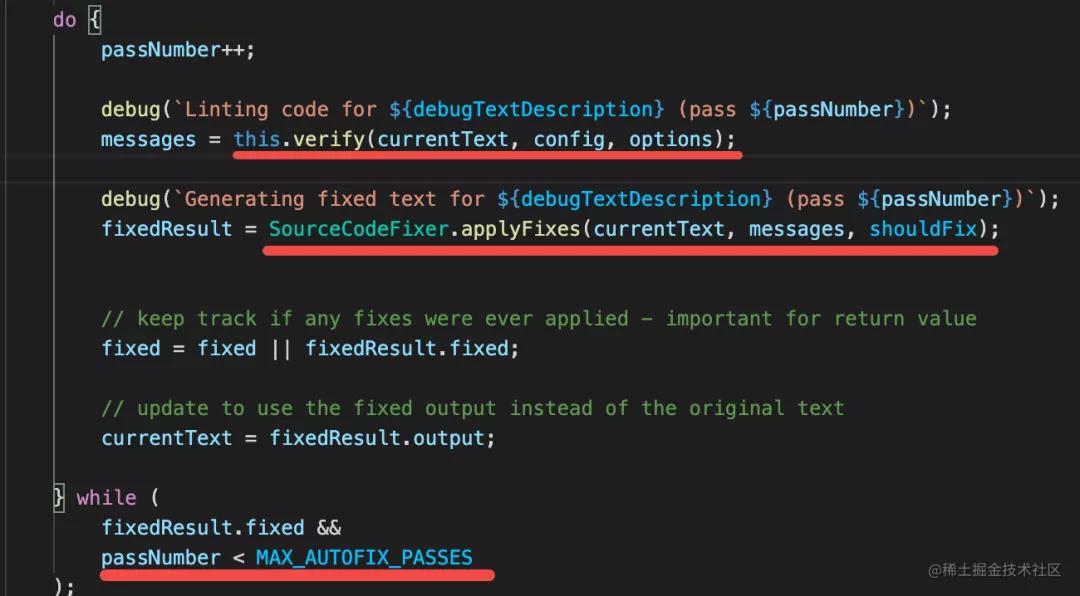
也就是 verify 进行检查,然后根据 fix 信息自动 fix。
fix 其实就是个字符串替换:
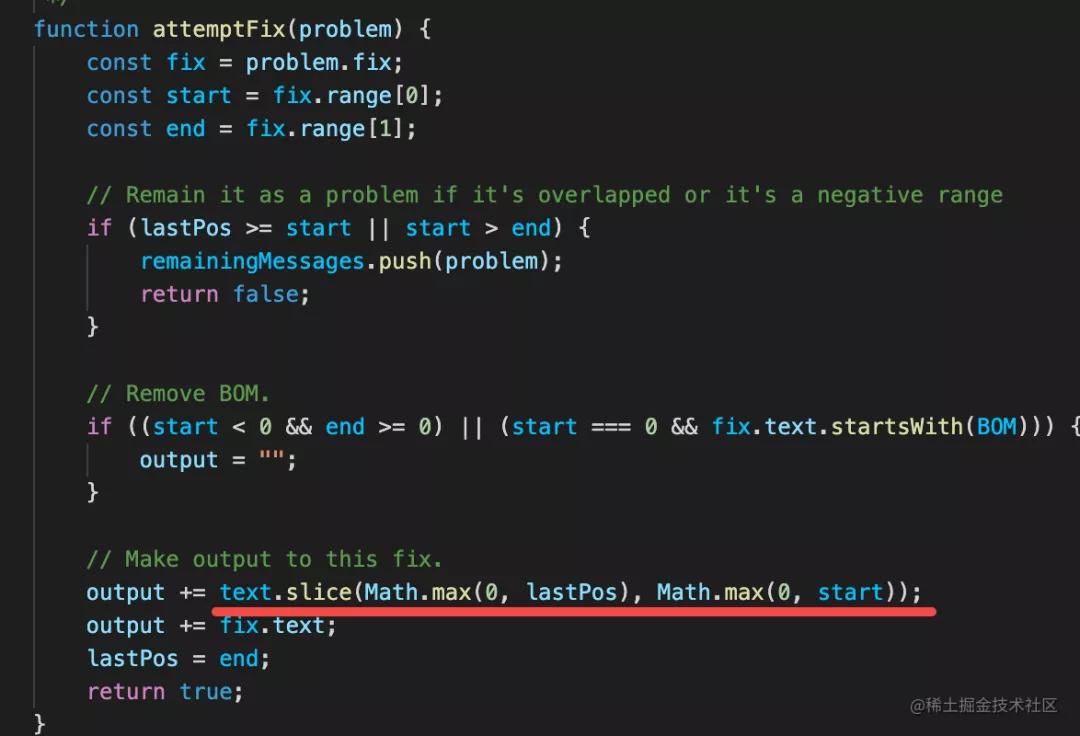
有的同学可能注意到了,字符串替换为什么要加个 while 循环呢?
因为多个 fix 之间的 range 也就是替换的范围可能是有重叠的,如果有重叠就放到下一次来修复,这样 while 循环最多修复 10 次,如果还有 fix 没修复就不修了。
这就是 fix 的实现原理,通过字符串替换来实现的,如果有重叠就循环来 fix。
preprocess 和 postprocess
其实核心的 verify 和 fix 的流程就是上面那些,但是 Eslint 还支持之前和之后做一些处理。也就是 pre 和 post 的 process,这些也是在插件里定义的。
module.exports = {
processors: {
".txt": {
preprocess: function(text, filename) {
return [ // return an array of code blocks to lint
{ text: code1, filename: "0.js" },
{ text: code2, filename: "1.js" },
];
},
postprocess: function(messages, filename) {
return [].concat(...messages);
}
}
}
};
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
之前的处理是把非 js 文件解析出其中的一个个 js 文件来,这和 webpack 的 loader 很像,这使得 Eslint 可以处理非 JS 文件的 lint。
之后的处理呢?那肯定是处理 problems 啊,也就是 messages,可以过滤掉一些 messages,或者做一些修改之类的。
那 preprocess 和 postprocess 是怎么实现的呢?
这个就比较简单了,就是在 verify 之前和之后调用就行。

通过 comment directives 来过滤掉一些 problems
我们知道 eslint 还支持通过注释来配置,比如 /* eslint-disable */ /*eslint-enable*/ 这种。
那它是怎么实现的呢?
注释的配置是通过扫描 AST 来收集所有的配置的,这种配置叫做 commentDirective,也就是哪行那列 Eslint 是否生效。
然后在 verify 结束的时候,对收集到的 linting problems 做一次过滤即可。

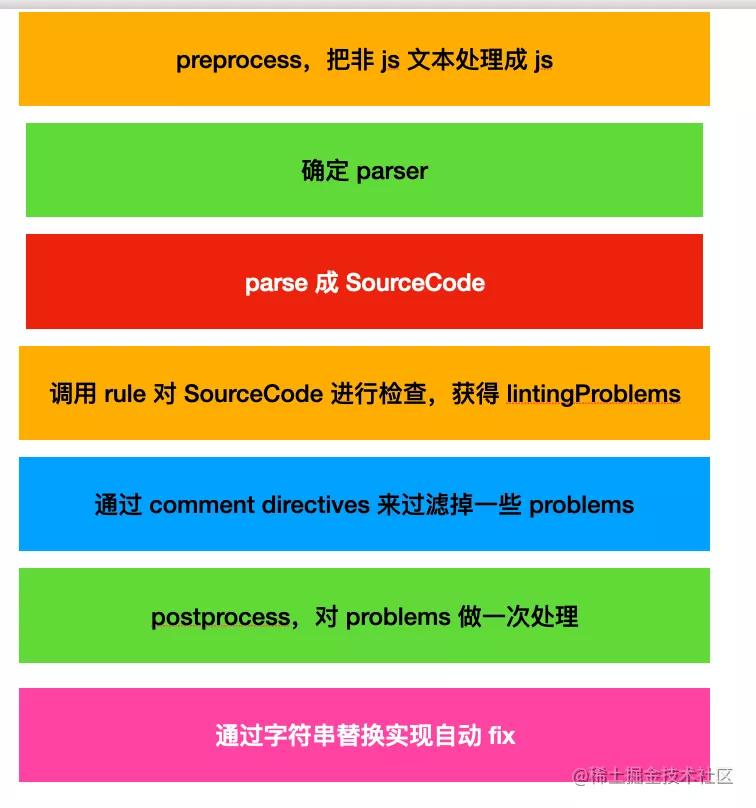
上面讲的这些就是 Eslint 的实现原理:
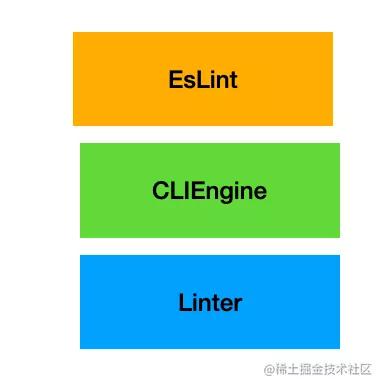
Eslint 和 CLIEngine 类
Linter 是实现核心功能的,上面我们介绍过了,但是在命令行的场景下还需要处理一些命令行参数,也就需要再包装一层 CLIEngine,用来做文件的读写,命令行参数的解析。
它有 executeOnFiles 和 executeOnText 等 api,是基于 Linter 类的上层封装。
但是 CLIEngine 并没有直接暴露出去,而是又包装了一层 EsLint 类,它只是一层比较好用的门面,隐藏了一些无关信息。
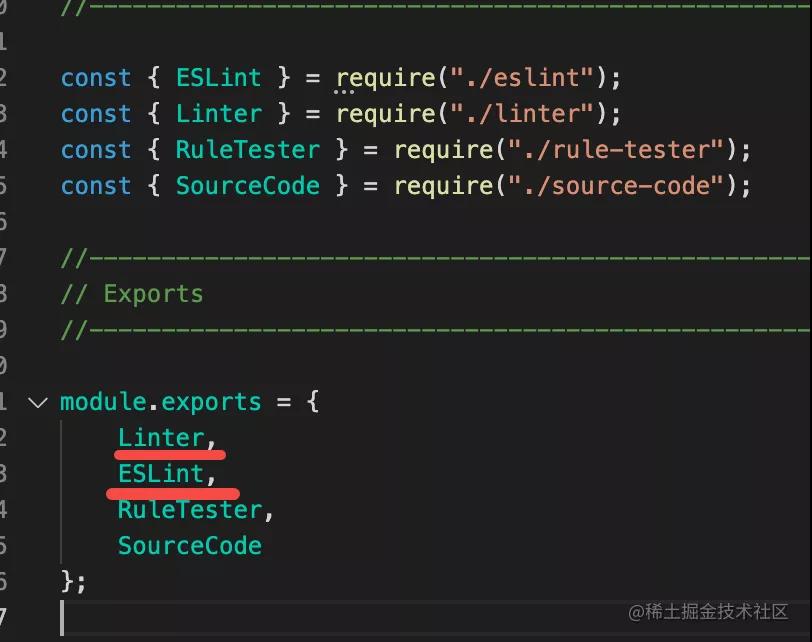
我们看下 eslint 最终暴露出来的这几个 api:
- Linter 是核心的类,直接对文本进行 lint
- ESLint 是处理配置、读写文件等,然后调用 Linter 进行 lint(中间的那层 CLIEngine 并没有暴露出来)
- SourceCode 就是封装 AST 用的
- RuleTester 是用于 rule 测试的一些 api。
总结
我们通过源码理清了 eslint 的实现原理:
ESLint 的核心类是 Linter,它分为这样几步:
- preprocess,把非 js 文本处理成 js
- 确定 parser(默认是 espree)
- 调用 parser,把源码 parse 成 SourceCode(ast)
- 调用 rules,对 SourceCode 进行检查,返回 linting problems
- 扫描出注释中的 directives,对 problems 进行过滤
- postprocess,对 problems 做一次处理
- 基于字符串替换实现自动 fix
除了核心的 Linter 类外,还有用于处理配置和读写文件的 CLIEngine 类,以及最终暴露出去的 Eslint 类。
这就是 Eslint 的实现原理,其实还是挺简单的:
基于 AST 做检查,基于字符串做 fix,之前之后还有 pre 与 post 的process,支持注释来配置过滤掉一些 problems。
把这些理清楚之后,就算是源码层面掌握了 Eslint 了。