【51CTO.com快译】Web 应用程序仍然是数据科学家向用户展示他们的数据科学项目的有用工具。由于我们可能没有 Web 开发技能,因此我们可以使用 Streamlit 等开源 Python 库在短时间内轻松开发 Web 应用程序。
1. Streamlit 简介
Streamlit 是一个开源 Python 库,用于为数据科学和机器学习项目创建和共享 Web 应用程序。该库可以帮助您使用几行代码在几分钟内创建和部署数据科学解决方案。
Streamlit 可以与数据科学中使用的其他流行的 Python 库无缝集成,例如 NumPy、Pandas、Matplotlib、Scikit-learn 等等。
注意:Streamlit 使用 React 作为前端框架来在屏幕上呈现数据。
2. 安装和设置
Streamlit 在您的机器中需要 python >= 3.7 版本。
要安装 streamlit,您需要在终端中运行以下命令。
pip install streamlit
您还可以使用以下命令检查您机器上安装的版本。
streamlit --version
流线型,版本 1.1.0
成功安装streamlit后,您可以通过在终端中运行以下命令来测试库。
streamlit hello
Streamlit 的 Hello 应用程序将出现在您的网络浏览器的新选项卡中。
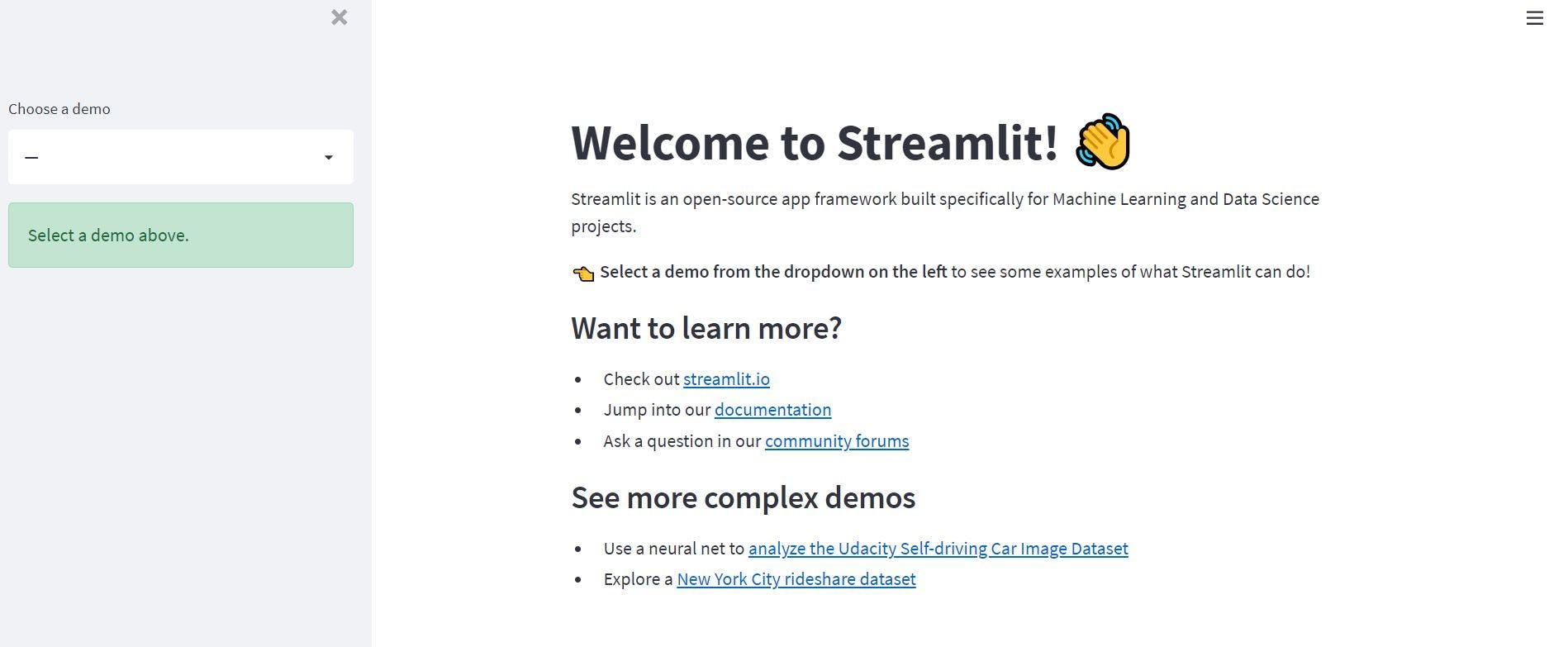
这表明一切运行正常,我们可以继续使用 Streamlit 创建我们的第一个 Web 应用程序。
3. 开发 Web 应用程序
在这一部分,我们将部署经过训练的 NLP 模型来预测电影评论的情绪(正面或负面)。您可以在[此处](https://hackernoon.com/how-to-build-and-deploy-an-nlp-model-with-fastapi-part-1-n5w35cj?ref=hackernoon.com)访问源代码和数据集。
数据科学 Web 应用程序将显示一个文本字段以添加电影评论和一个简单按钮以提交评论并进行预测。
导入重要包
第一步是创建一个名为 app.py 的 python 文件,然后为 streamlit 和训练的 NLP 模型导入所需的 python 包。
# import packages import streamlit as st import os import numpy as np from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer # text preprocessing modules from string import punctuation # text preprocessing modules from nltk.tokenize import word_tokenize import nltk from nltk.corpus import stopwords from nltk.stem import WordNetLemmatizer import re # regular expression import joblib import warnings warnings.filterwarnings("ignore") # seeding np.random.seed(123) # load stop words stop_words = stopwords.words("english")
清理评论的功能
评论可能包含我们在进行预测时不需要的不必要的单词和字符。
我们将通过删除停用词、数字和标点符号来清理评论。然后我们将使用 NLTK 包中的词形还原过程将每个单词转换为其基本形式。
该**text_cleaning()**函数将处理所有必要的步骤进行预测之前清理我们的审查。
# function to clean the text @st.cache def text_cleaning(text, remove_stop_words=True, lemmatize_words=True): # Clean the text, with the option to remove stop_words and to lemmatize word # Clean the text text = re.sub(r"[^A-Za-z0-9]", " ", text) text = re.sub(r"\'s", " ", text) text = re.sub(r"http\S+", " link ", text) text = re.sub(r"\b\d+(?:\.\d+)?\s+", "", text) # remove numbers # Remove punctuation from text text = "".join([c for c in text if c not in punctuation]) # Optionally, remove stop words if remove_stop_words: texttexttext = text.split() text = [w for w in text if not w in stop_words] text = " ".join(text) # Optionally, shorten words to their stems if lemmatize_words: texttexttext = text.split() lemmatizer = WordNetLemmatizer() lemmatized_words = [lemmatizer.lemmatize(word) for word in text] text = " ".join(lemmatized_words) # Return a list of words return text
预测功能
名为**make_prediction()**的 python 函数将执行以下任务。
1. 收到审查并清理它。
2. 加载经过训练的 NLP 模型。
3. 做个预测。
4. 估计预测的概率。
5. 最后,它将返回预测的类别及其概率。
# functon to make prediction @st.cache def make_prediction(review): # clearn the data clean_review = text_cleaning(review) # load the model and make prediction model = joblib.load("sentiment_model_pipeline.pkl") # make prection result = model.predict([clean_review]) # check probabilities probas = model.predict_proba([clean_review]) probability = "{:.2f}".format(float(probas[:, result])) return result, probability
**注意:**如果训练后的 NLP 模型预测为 1,则表示 Positive,如果预测为 0,则表示 Negative。
**创建应用标题和描述**
您可以使用 streamlit 中的 title() 和 write() 方法创建 Web 应用程序的标题及其描述。
# Set the app title st.title("Sentiment Analyisis App") st.write( "A simple machine laerning app to predict the sentiment of a movie's review" )
要显示 Web 应用程序,您需要在终端中运行以下命令。
streamlit run app.py
然后您将看到 Web 应用程序自动在您的 Web 浏览器中弹出,或者您可以使用创建的本地 URL http://localhost:8501。

创建表格以接收电影评论
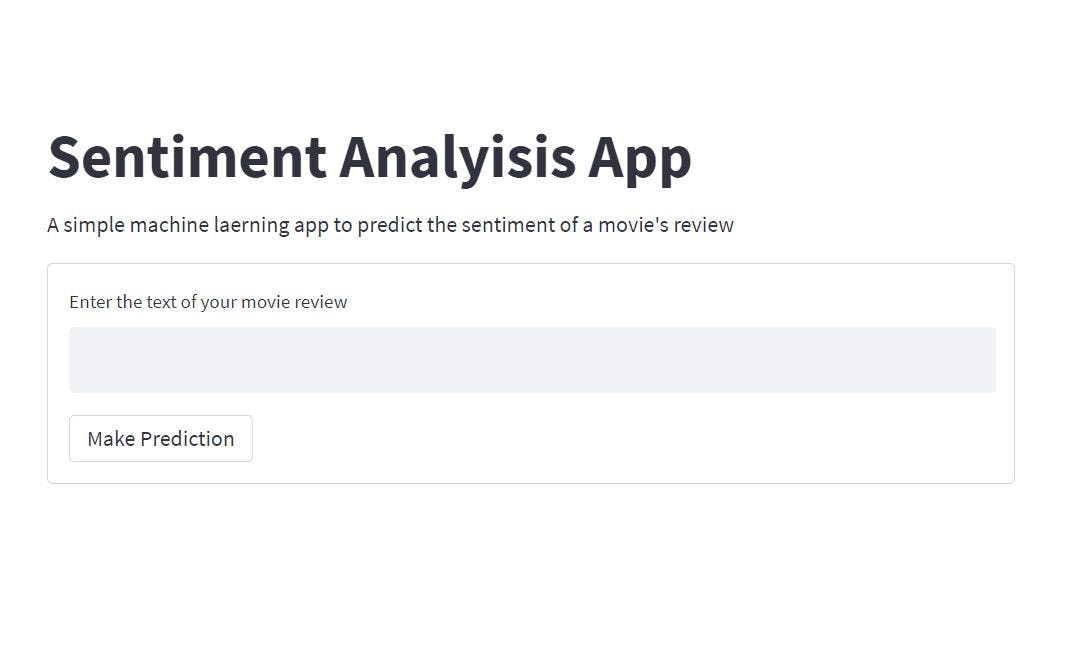
下一步是使用 streamlit 创建一个简单的表单。表单将显示一个文本字段来添加您的评论,在文本字段下方,它将显示一个简单的按钮来提交添加的评论,然后进行预测。
# Declare a form to receive a movie's review form = st.form(key="my_form") review = form.text_input(label="Enter the text of your movie review") submit = form.form_submit_button(label="Make Prediction")
现在,您可以在 Web 应用程序上看到该表单。
进行预测并显示结果
我们的最后一段代码是在用户添加电影评论并单击表单部分上的“进行预测”按钮时进行预测并显示结果。
单击按钮后,Web 应用程序将运行**make_prediction()**函数并在浏览器中的 Web 应用程序上显示结果。
if submit: # make prediction from the input text result, probability = make_prediction(review) # Display results of the NLP task st.header("Results") if int(result) == 1: st.write("This is a positive review with a probabiliy of ", probability) else: st.write("This is a negative review with a probabiliy of ", probability)
4. 测试 Web 应用程序
通过几行代码,我们创建了一个简单的数据科学网络应用程序,它可以接收电影评论并预测它是正面评论还是负面评论。
要测试 Web 应用程序,请通过添加您选择的电影评论来填充文本字段。我添加了以下关于 **扎克·施奈德**2021 年上映**的正义联盟**电影的影评。
> “我从头到尾都很喜欢这部电影。就像雷·费舍尔说的,我希望这部电影不要结束。乞讨的场景令人兴奋,非常喜欢那个场景。不像电影《正义联盟》那样展示每个英雄最擅长自己的事情,让我们热爱每个角色。谢谢,扎克和整个团队。”
然后单击进行预测按钮并查看结果。
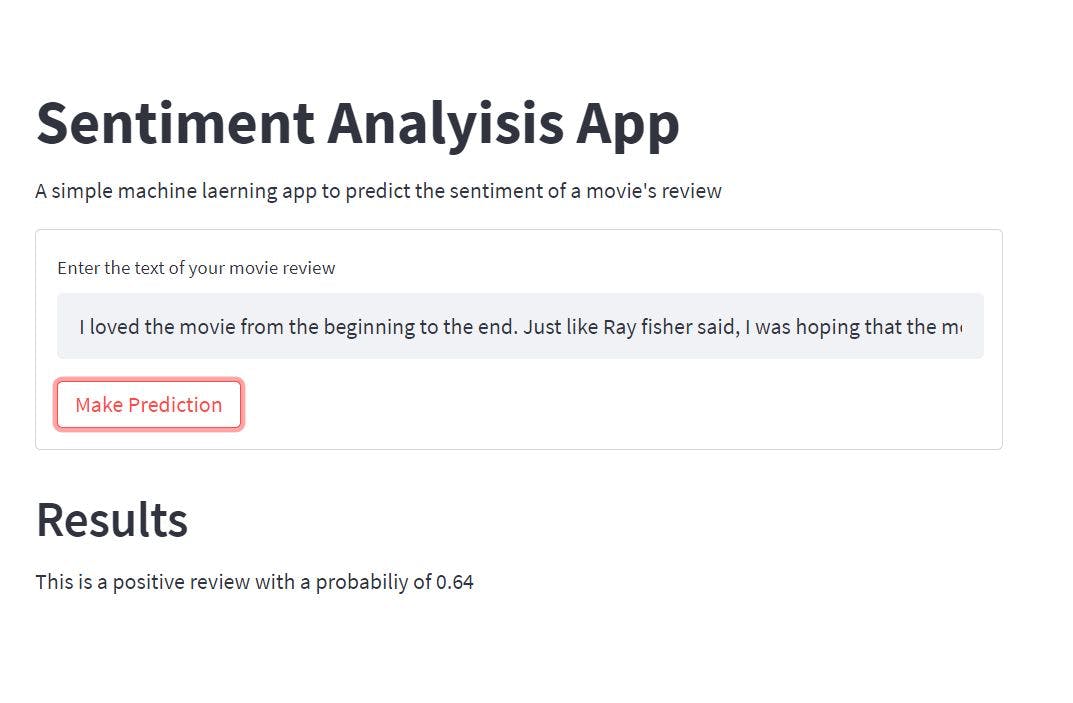
正如您在我们创建的 Web 应用程序中看到的那样,经过训练的 NLP 模型预测添加的评论是**正面的**,概率为**0.64。
我建议您在我们创建的数据科学 Web 应用程序上添加另一条影评并再次测试。
5. 结论
Streamlit 提供了许多功能和组件,您可以使用它们以您想要的方式开发数据科学 Web 应用程序。您在此处学到的是来自 streamlit 的一些常见元素。
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】