本文转自雷锋网,如需转载请至雷锋网官网申请授权。
只需一次前向传播,这个图神经网络,或者说元模型,便可预测一个图像分类模型的所有参数。有了它,无需再苦苦等待梯度下降收敛!
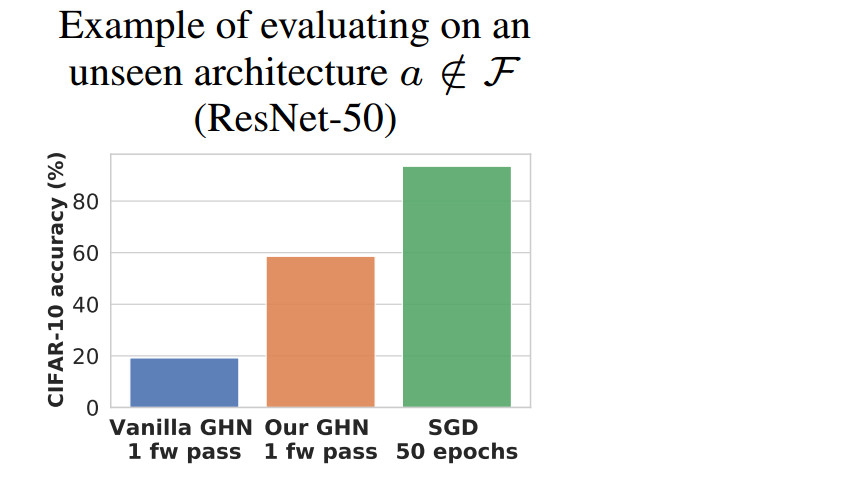
来自圭尔夫大学的论文一作 Boris Knyazev 介绍道,该元模型可以预测 ResNet-50 的所有2400万个参数,并且这个 ResNet-50 将在 CIFAR-10 上达到将近60%的准确率,无需任何训练。特别是,该模型适用于几乎任何神经网络。
基于这个结果,作者向我们发出了灵魂之问:以后还需要 SGD 或 Adam 来训练神经网络吗?
“我们离用单一元模型取代手工设计的优化器又近了一步,该元模型可以在一次前向传播中预测几乎任何神经网络的参数。”
令人惊讶的是,这个元模型在训练时,没有接收过任何类似 ResNet-50 的网络(作为训练数据)。
该元模型的适用性非常广,不仅是ResNet-50,它还可以预测 ResNet-101、ResNet-152、Wide-ResNets、Visual Transformers 的所有参数,“应有尽有”。不止是CIFAR-10,就连在ImageNet这样更大规模的数据集上,它也能带来不错的效果。
同时,效率方面也很不错。该元模型可以在平均不到 1 秒的时间内预测给定网络的所有参数,即使在 CPU 上,它的表现也是如此迅猛!
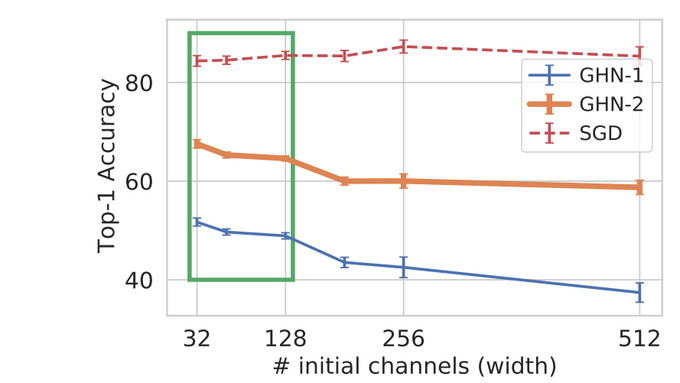
但天底下终究“没有免费的午餐”,因此当该元模型预测其它不同类型的架构时,预测的参数不会很准确(有时可能是随机的)。一般来说,离训练分布越远(见图中的绿框),预测的结果就越差。
但是,即使使用预测参数的网络分类准确率很差,也不要失望。
我们仍然可以将其作为具有良好初始化参数的模型,而不需要像过去那样,使用随机初始化,“我们可以在这种迁移学习中受益,尤其是在少样本学习任务中。”
作者还表示,“作为图神经网络的粉丝”,他们特地选用了GNN作为元模型。该模型是基于 Chris Zhang、Mengye Ren 和 Raquel Urtasun发表的ICLR 2019论文“Graph HyperNetworks for Neural Architecture Search”GHN提出的。

论文地址:https://arxiv.org/abs/1810.05749
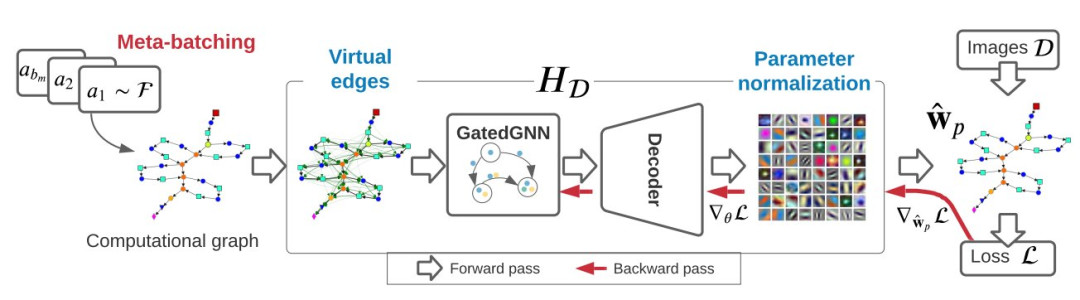
在他们的基础上,作者开发并训练了一个新的模型 GHN-2,它具有更好的泛化能力。
简而言之,在多个架构上更新 GHN 参数,并正确归一化预测参数、改善图中的远程交互以及改善收敛性至关重要。
为了训练 GHN-2,作者引入了一个神经架构数据集——DeepNets-1M。
这个数据集分为训练集、验证集和测试集三个部分。此外,他们还使用更广、更深、更密集和无归一化网络来进行分布外测试。
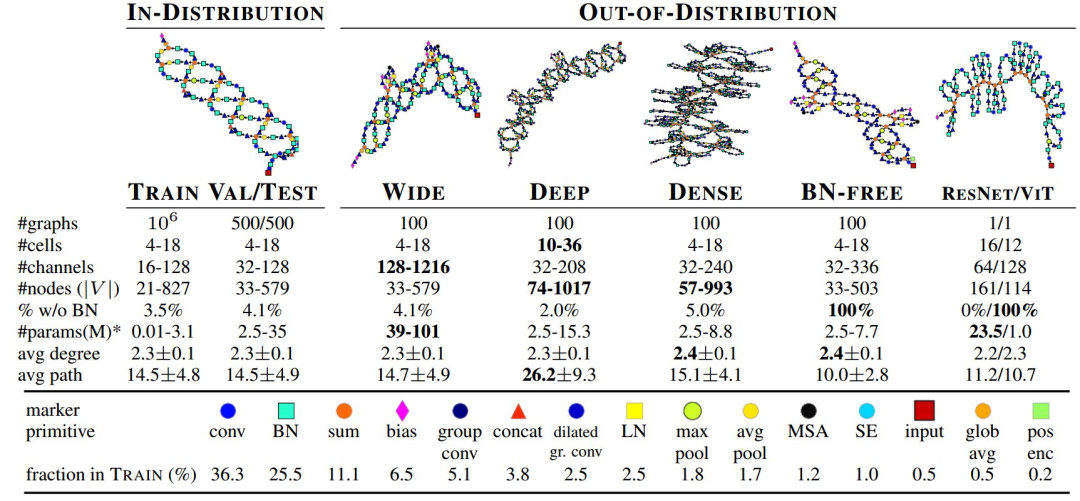
作者补充道,DeepNets-1M 可以作为一个很好的测试平台,用于对不同的图神经网络 (GNN) 进行基准测试。“使用我们的 PyTorch 代码,插入任何 GNN(而不是我们的 Gated GNN )应该都很简单。”
除了解决参数预测任务和用于网络初始化之外, GHN-2 还可用于神经架构搜索,“GHN-2可以搜索最准确、最鲁棒(就高斯噪声而言)、最有效和最容易训练的网络。”
这篇论文已经发表在了NeurIPS 2021上,研究人员分别来自圭尔夫大学、多伦多大学向量人工智能研究所、CIFAR、FAIR和麦吉尔大学。

论文地址:https://arxiv.org/pdf/2110.13100.pdf
项目也已经开源,赶紧去膜拜这个神经网络优化器吧!
项目地址:https://github.com/facebookresearch/ppuda
1、模型详解
考虑在大型标注数据集(如ImageNet)上训练深度神经网络的问题, 这个问题可以形式化为对给定的神经网络 a 寻找最优参数w。
损失函数通常通过迭代优化算法(如SGD和Adam)来最小化,这些算法收敛于架构 a 的性能参数w_p。
尽管在提高训练速度和收敛性方面取得了进展,但w_p的获取仍然是大规模机器学习管道中的一个瓶颈。
例如,在 ImageNet 上训练 ResNet-50 可能需要花费相当多的 GPU 时间。
随着网络规模的不断增长,以及重复训练网络的必要性(如超参数或架构搜索)的存在,获得 w_p 的过程在计算上变得不可持续。
而对于一个新的参数预测任务,在优化新架构 a 的参数时,典型的优化器会忽略过去通过优化其他网络获得的经验。
然而,利用过去的经验可能是减少对迭代优化依赖的关键,从而减少高计算需求。
为了朝着这个方向前进,研究人员提出了一项新任务,即使用超网络 HD 的单次前向传播迭代优化。
为了解决这一任务,HD 会利用过去优化其他网络的知识。
例如,我们考虑 CIFAR-10 和 ImageNet 图像分类数据集 D,其中测试集性能是测试图像的分类准确率。
让 HD 知道如何优化其他网络的一个简单方法是,在[架构,参数]对的大型训练集上对其进行训练,然而,这个过程的难度令人望而却步。
因此,研究人员遵循元学习中常见的双层优化范式,即不需要迭代 M 个任务,而是在单个任务(比如图像分类)上迭代 M 个训练架构。
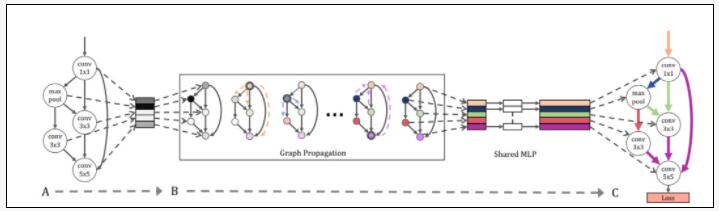
图 0:GHN原始架构概览。A:随机采样一个神经网络架构,生成一个GHN。B:经过图传播后,GHN 中的每个节点都会生成自己的权重参数。C:通过训练GHN,最小化带有生成权重的采样网络的训练损失。根据生成网络的性能进行排序。来源:https://arxiv.org/abs/1810.05749
通过优化,超网络 HD 逐渐获得了如何预测训练架构的性能参数的知识,然后它可以在测试时利用这些知识。
为此,需要设计架构空间 F 和 HD。
对于 F,研究人员基于已有的神经架构设计空间,我们以两种方式对其进行了扩展:对不同架构进行采样的能力和包括多种架构的扩展设计空间,例如 ResNets 和 Visual Transformers。
这样的架构可以以计算图的形式完整描述(图 1)。
因此,为了设计超网络 HD,将依赖于图结构数据机器学习的最新进展。
特别是,研究人员的方案建立在 Graph HyperNetworks (GHNs) 方法的基础上。
通过设计多样化的架构空间 F 和改进 GHN,GHN-2在 CIFAR-10和 ImageNet上预测未见过架构时,图像识别准确率分别提高到77% (top-1)和48% (top-5)。
令人惊讶的是,GHN-2 显示出良好的分布外泛化,比如对于相比训练集中更大和更深的架构,它也能预测出良好的参数。
例如,GHN-2可以在不到1秒的时间内在 GPU 或 CPU 上预测 ResNet-50 的所有 2400 万个参数,在 CIFAR-10 上达到约 60%的准确率,无需任何梯度更新(图 1,(b))。
总的来说,该框架和结果为训练网络开辟了一条新的、更有效的范式。
本论文的贡献如下:
(a)引入了使用单个超网络前向传播预测不同前馈神经网络的性能参数的新任务;
(b)引入了 DEEPNETS-1M数据集,这是一个标准化的基准测试,具有分布内和分布外数据,用于跟踪任务的进展;
(c)定义了几个基线,并提出了 GHN-2 模型,该模型在 CIFAR-10 和 ImageNet( 5.1 节)上表现出奇的好;
(d)该元模型学习了神经网络架构的良好表示,并且对于初始化神经网络是有用的。
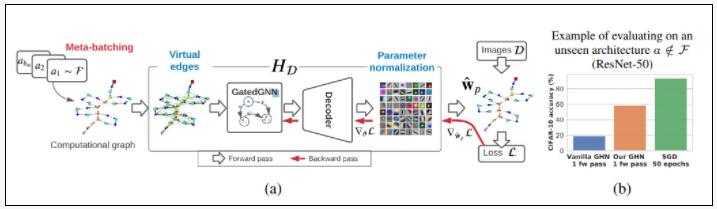
上图图1(a)展示了GHN 模型概述(详见第 4 节),基于给定图像数据集和DEEPNETS-1M架构数据集,通过反向传播来训练GHN模型,以预测图像分类模型的参数。
研究人员对 vanilla GHN 的主要改进包括Meta-batching、Virtual edges、Parameter normalization等。
其中,Meta-batching仅在训练 GHN 时使用,而Virtual edges、Parameter normalization用于训练和测试时。a1 的可视化计算图如表 1 所示。
图1(b)比较了由 GHN 预测ResNet-50 的所有参数的分类准确率与使用 SGD 训练其参数时的分类准确率。尽管自动化预测参数得到的网络准确率仍远远低于人工训练的网络,但可以作为不错的初始化手段。
2、实验:参数预测
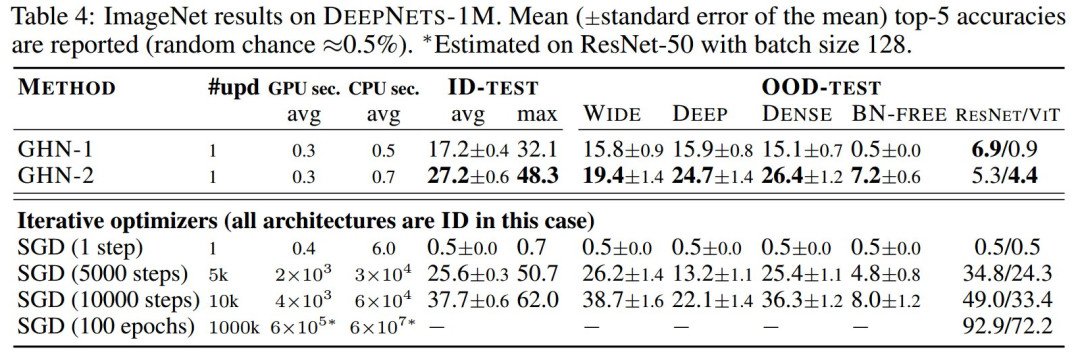
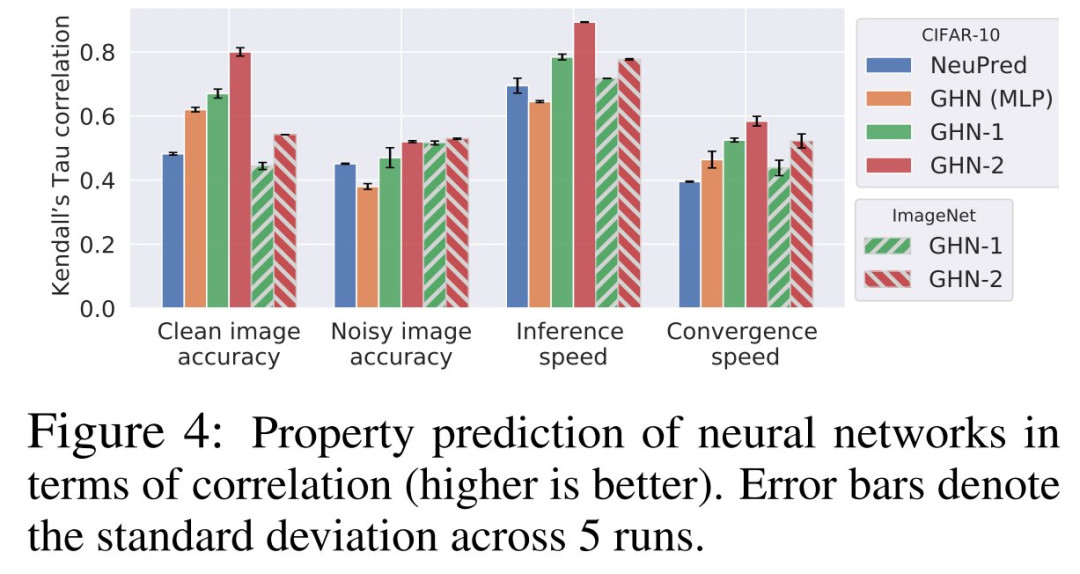
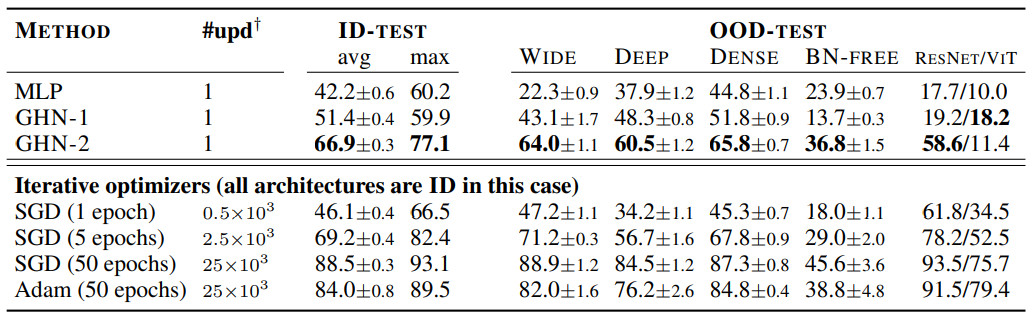
尽管 GHN-2 从未观察过测试架构,但 GHN-2 为它们预测了良好的参数,使测试网络在两个图像数据集上的表现都出奇的好(表 3 和表 4)。
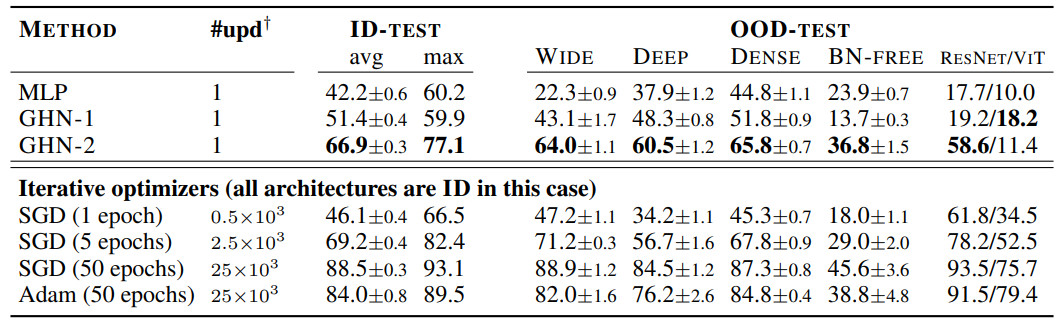
表 3:GHN-2在DEEPNETS-1M 的未见过 ID 和 OOD 架构的预测参数结果(CIFAR-10 )
GHN-2甚至在 ImageNet 上展示了良好的结果,其中对于某些架构,实现了高达 48.3% 的top-5准确率。
虽然这些结果对于直接下游应用来说很不够,但由于三个主要原因,它们非常有意义。
首先,不依赖于通过 SGD 训练架构 F 的昂贵得令人望而却步的过程。
其次,GHN 依靠单次前向传播来预测所有参数。
第三,这些结果是针对未见过的架构获得的,包括 OOD 架构。即使在严重的分布变化(例如 ResNet-506 )和代表性不足的网络(例如 ViT7 )的情况下,GHN-2仍然可以预测比随机参数表现更好的参数。
在 CIFAR-10 上,GHN-2 的泛化能力特别强,在 ResNet-50 上的准确率为 58.6%。
在这两个图像数据集上,GHN-2 在 DEEPNETS-1M 的所有测试子集上都显着优于 GHN-1,在某些情况下绝对增益超过 20%,例如BN-FREE 网络上的 36.8% 与 13.7%(表 3)。
利用计算图的结构是 GHN 的一个关键特性,当用 MLP 替换 GHN-2 的 GatedGNN 时,在 ID(甚至在 OOD)架构上的准确率从 66.9% 下降到 42.2%。
与迭代优化方法相比,GHN-2 预测参数的准确率分别与 CIFAR-10 和 ImageNet 上 SGD 的 ∼2500 次和 ∼5000 次迭代相近。
相比之下,GHN-1 的性能分别与仅 ~500 次和 ~2000次(未在表 4 中展示)迭代相似。
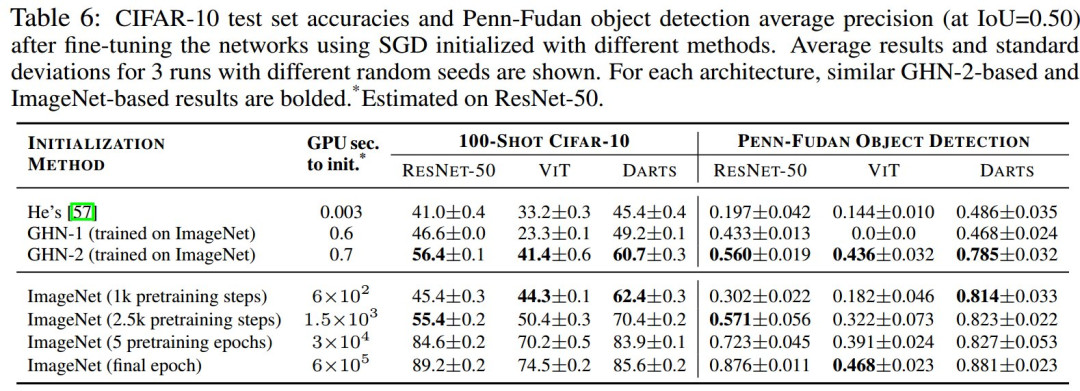
消融实验(表 5)表明第 4 节中提出的所有三个组件都很重要。
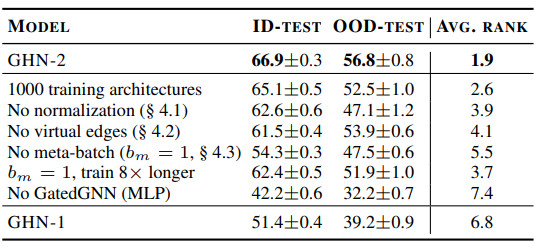
表 5:在 CIFAR-10 上消融 GHN-2,在所有 ID 和 OOD 测试架构中计算模型的平均排名