












本文转载自微信公众号「KK架构」,作者wangkai。转载本文请联系KK架构公众号。
一、回顾一下之前的内容
上一次阅读到了 SparkContext 初始化,继续往下之前,先温故一下之前的内容。
这里有个假设是:Spark 集群以 Standalone 的方式来启动的,作业也是提交到 Spark standalone 集群。
首先需要启动 Spark 集群,使用 start-all.sh 脚本依次启动 Master (主备) 和多个 Worker。
启动好之后,开始提交作业,使用 spark-submit 命令来提交。
- 首先在提交任务的机器上使用 java 命令启动了一个虚拟机,并且执行了主类 SparkSubmit 的 main 方法作为入口。
- 然后根据提交到不同的集群,来 new 不同的客户端类,如果是 standalone 的话,就 new 了一个 ClientApp;然后把 java DriverWrapper 这个命令封装到 RequestSubmmitDriver 消息中,把这个消息发送给 Master;
- Master 随机找一个满足资源条件的 Worker 来启动 Driver,实际上是在虚拟机里执行 DriverWrapper 的 main 方法;
- 然后 Worker 开始启动 Driver,启动的时候会执行用户提交的 java 包里的 main 方法,然后开始执行 SparkContext 的初始化,依次在 Driver 中创建了 DAGScheduler、TaskScheduler、SchedulerBackend 三个重要的实例。并且启动了 DriverEndpoint 和 ClientEndpoint ,用来和 Worker、Master 通信。
二、Master 处理应用的注册
接着上次 ClientEndpoint 启动之后,会向 Master 发送一个 RegisterApplication 消息,Master 开始处理这个消息。
然后看到 Matster 类处理 RegisterApplication 消息的地方:
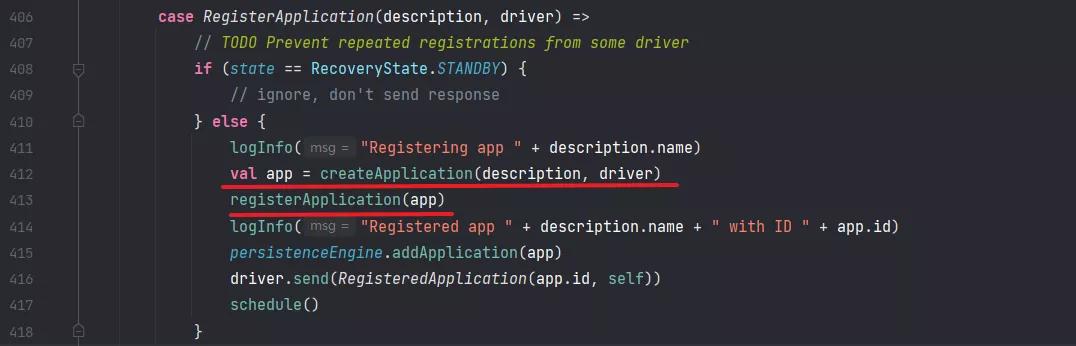
可以看到,用应用程序的描述和 Driver 的引用创建了一个 Application,然后开始注册这个 Application。
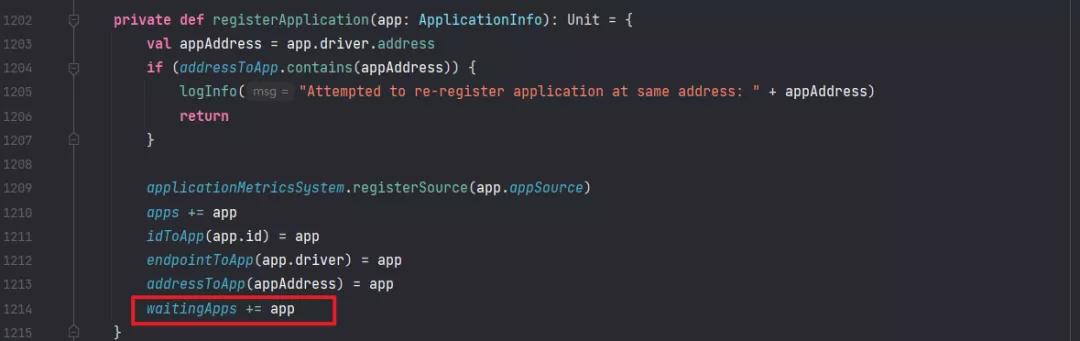
注册 Application 很简单,就是往 Master 的内存中加入各种信息,重点来了,把 ApplicationInfo 加入到了 waitingApps 这个结构里,然后 schedule() 方法会遍历这个列表,为 Application 分配资源,并调度起来。
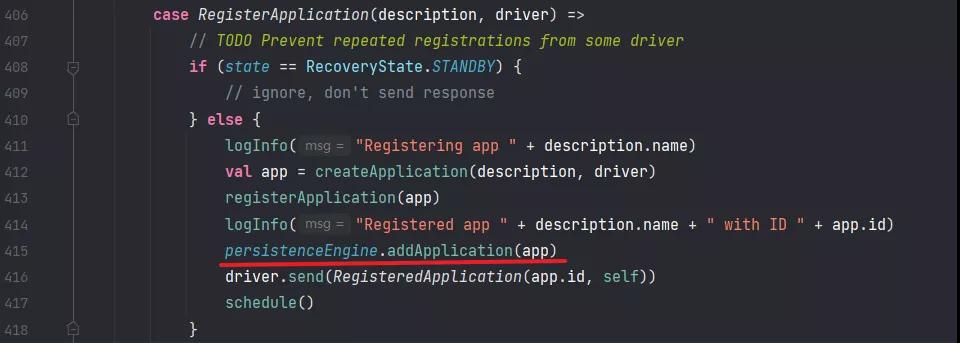
然后往 zk 中写入了 Application 的信息,并且往 Driver 发送了一个 RegisteredApplication 应用已经注册的消息。
接着开始 schedule(),这个方法上次讲过,它会遍历两个列表,一个是遍历 waitingDrivers 来启动 Driver,一个是遍历 waitingApps,来启动 Application。
waitingDrivers 列表在客户端请求启动 Driver 的时候就处理过了,本次重点看这个方法:
- startExecutorsOnWorkers()
三、Master 对资源的调度
有以下几个步骤:
- 遍历 waitingApps 的所有 app;
- 如果 app 需要的核数小于一个 Executor 可以提供的核数,就不为 app 分配新的 Executor;
- 过滤出还有可供调度的 cpu 和 memory 的 workers,并按照 cores 的大小降序排序,作为 usableWorkers;
- 计算所有 usableWorkers 上要分配多少 CPU;
- 然后遍历可用的 Workers,分配资源并执行调度,启动 Executor。
源码从 Master 类的 schedule() 方法的最后一行 startExecutorsOnWorkers() 开始:
这个方法主要作用是计算 worker 的 executor 数量和分配的资源并启动 executor。
- /**
- * Schedule and launch executors on workers
- */
- private def startExecutorsOnWorkers(): Unit = {
- // Right now this is a very simple FIFO scheduler. We keep trying to fit in the first app
- // in the queue, then the second app, etc.
- for (app <- waitingApps) {
- val coresPerExecutor = app.desc.coresPerExecutor.getOrElse(1)
- // If the cores left is less than the coresPerExecutor,the cores left will not be allocated
- if (app.coresLeft >= coresPerExecutor) {
- // 1. 剩余内存大于单个 executor 需要的内存
- // 2. 剩余的内核数大于单个 executor 需要的内核数
- // 3. 按照内核数从大到小排序
- // Filter out workers that don't have enough resources to launch an executor
- val usableWorkers = workers.toArray.filter(_.state == WorkerState.ALIVE)
- .filter(canLaunchExecutor(_, app.desc))
- .sortBy(_.coresFree).reverse
- val appMayHang = waitingApps.length == 1 &&
- waitingApps.head.executors.isEmpty && usableWorkers.isEmpty
- if (appMayHang) {
- logWarning(s"App ${app.id} requires more resource than any of Workers could have.")
- }
- // 计算每个 Worker 上可用的 cores
- val assignedCores = scheduleExecutorsOnWorkers(app, usableWorkers, spreadOutApps)
- // Now that we've decided how many cores to allocate on each worker, let's allocate them
- for (pos <- 0 until usableWorkers.length if assignedCores(pos) > 0) {
- allocateWorkerResourceToExecutors(
- app, assignedCores(pos), app.desc.coresPerExecutor, usableWorkers(pos))
- }
- }
- }
- }
(1)遍历 waitingApps,如果 app 还需要的 cpu 核数大于每个执行器的核数,才继续分配。
(2)过滤可用的 worker,条件一:该 worker 剩余内存大于单个 executor 需要的内存;条件二:该 worker 剩余 cpu 核数大于单个 executor 需要的核数;然后按照可用 cpu核数从大到小排序。
(3)下面两个方法是关键的方法
scheduleExecutorsOnWorkers(),用来计算每个 Worker 上可用的 cpu 核数;
allocateWorkerResourceToExecutors() 用来真正在 Worker 上分配 Executor。
四、scheduleExecutorsOnWorkers 计算每个 Worker 可用的核数
这个方法很长,首先看方法注释,大致翻译了一下:
当执行器分配的 cpu 核数(spark.executor.cores)被显示设置的时候,如果这个 worker 上有足够的核数和内存的话,那么每个 worker 上可以执行多个执行器;反之,没有设置的时候,每个 worker 上只能启动一个执行器;并且,这个执行器会使用 worker 能提供出来的尽可能多的核数;
appA 和 appB 都有一个执行器运行在 worker1 上。但是 appA 还需要一些 cpu 核,当 appB 执行结束,释放了它在 worker1 上的核数时, 下一次调度的时候,appA 会新启动一个 executor 获得了 worker1 上所有的可用的核心,因此 appA 就在 worker1 上启动了多个执行器。
设置 coresPerExecutor (spark.executor.cores)很重要,考虑下面的例子:集群有4个worker,每个worker有16核;用户请求 3 个执行器(spark.cores.max = 48,spark.executor.cores=16)。如果不设置这个参数,那么每次分配 1 个 cpu核心,每个 worker 轮流分配一个 cpu核,最终 4 个执行器分配 12 个核心给每个 executor,4 个 worker 也同样分配了48个核心,但是最终每个 executor 只有 12核 < 16 核,所以最终没有执行器被启动。
如果看我的翻译还是很费劲,我就再精简下:
- 如果没有设置 spark.executor.cores,那么每个 Worker 只能启动一个 Executor,并且这个 Executor 会占用所有 Worker 能提供的 cpu核数;
- 如果显示设置了,那么每个 Worker 可以启动多个 Executor;
下面是源码,每句都有挨个注释过,中间有一个方法是判断这个 Worker 上还能不能再分配 Executor 了。
重点是中间方法后面那一段,遍历每个 Worker 分配 cpu,如果不是 Spend Out 模式,则在一个 Worker 上一直分配,直到 Worker 资源分配完毕。
- private def scheduleExecutorsOnWorkers(
- app: ApplicationInfo,
- usableWorkers: Array[WorkerInfo],
- spreadOutApps: Boolean): Array[Int] = {
- // 每个 executor 的核数
- val coresPerExecutor = app.desc.coresPerExecutor
- // 每个 executor 的最小核数 为1
- val minCoresPerExecutor = coresPerExecutor.getOrElse(1)
- // 每个Worker分配一个Executor? 这个参数可以控制这个行为
- val oneExecutorPerWorker = coresPerExecutor.isEmpty
- // 每个Executor的内存
- val memoryPerExecutor = app.desc.memoryPerExecutorMB
- val resourceReqsPerExecutor = app.desc.resourceReqsPerExecutor
- // 可用 Worker 的总数
- val numUsable = usableWorkers.length
- // 给每个Worker的cores数
- val assignedCores = new Array[Int](numUsable) // Number of cores to give to each worker
- // 给每个Worker上新的Executor数
- val assignedExecutors = new Array[Int](numUsable) // Number of new executors on each worker
- // app 需要的核心数 和 所有 worker 能提供的核心总数,取最小值
- var coresToAssign = math.min(app.coresLeft, usableWorkers.map(_.coresFree).sum)
- // 判断指定的worker是否可以为这个app启动一个executor
- /** Return whether the specified worker can launch an executor for this app. */
- def canLaunchExecutorForApp(pos: Int): Boolean = {
- // 如果能提供的核心数 大于等 executor 需要的最小核心数,则继续分配
- val keepScheduling = coresToAssign >= minCoresPerExecutor
- // 是否有足够的核心:当前 worker 能提供的核数 减去 每个 worker 已分配的核心数 ,大于每个 executor最小的核心数
- val enoughCores = usableWorkers(pos).coresFree - assignedCores(pos) >= minCoresPerExecutor
- // 当前 worker 新分配的 executor 个数
- val assignedExecutorNum = assignedExecutors(pos)
- // 如果每个worker允许多个executor,就能一直在启动新的的executor
- // 如果在这个worker上已经有executor,则给这个executor更多的core
- // If we allow multiple executors per worker, then we can always launch new executors.
- // Otherwise, if there is already an executor on this worker, just give it more cores.
- // 如果一个 worker 上可以启动多个 executor 或者 这个 worker 还没分配 executor
- val launchingNewExecutor = !oneExecutorPerWorker || assignedExecutorNum == 0
- if (launchingNewExecutor) {
- // 总共已经分配的内存
- val assignedMemory = assignedExecutorNum * memoryPerExecutor
- // 是否有足够的内存:当前worker 的剩余内存 减去 已分配的内存 大于每个 executor需要的内存
- val enoughMemory = usableWorkers(pos).memoryFree - assignedMemory >= memoryPerExecutor
- //
- val assignedResources = resourceReqsPerExecutor.map {
- req => req.resourceName -> req.amount * assignedExecutorNum
- }.toMap
- val resourcesFree = usableWorkers(pos).resourcesAmountFree.map {
- case (rName, free) => rName -> (free - assignedResources.getOrElse(rName, 0))
- }
- val enoughResources = ResourceUtils.resourcesMeetRequirements(
- resourcesFree, resourceReqsPerExecutor)
- // 所有已分配的核数+app需要的核数 小于 app的核数限制
- val underLimit = assignedExecutors.sum + app.executors.size < app.executorLimit
- keepScheduling && enoughCores && enoughMemory && enoughResources && underLimit
- } else {
- // We're adding cores to an existing executor, so no need
- // to check memory and executor limits
- keepScheduling && enoughCores
- }
- }
- // 不断的启动executor,直到不再有Worker可以容纳任何Executor,或者达到了这个Application的要求
- // Keep launching executors until no more workers can accommodate any
- // more executors, or if we have reached this application's limits
- // 过滤出可以启动 executor 的 workers
- var freeWorkers = (0 until numUsable).filter(canLaunchExecutorForApp)
- while (freeWorkers.nonEmpty) {
- // 遍历每个 worker
- freeWorkers.foreach { pos =>
- var keepScheduling = true
- while (keepScheduling && canLaunchExecutorForApp(pos)) {
- coresToAssign -= minCoresPerExecutor
- assignedCores(pos) += minCoresPerExecutor
- // 如果我们在每个worker上启动一个executor,每次迭代为每个executor增加一个core
- // 否则,每次迭代都会为新的executor分配cores
- // If we are launching one executor per worker, then every iteration assigns 1 core
- // to the executor. Otherwise, every iteration assigns cores to a new executor.
- if (oneExecutorPerWorker) {
- assignedExecutors(pos) = 1
- } else {
- assignedExecutors(pos) += 1
- }
- // 如果不使用Spreading out方法,我们会在这个worker上继续调度executor,直到使用它所有的资源
- // 否则,就跳转到下一个worker
- // Spreading out an application means spreading out its executors across as
- // many workers as possible. If we are not spreading out, then we should keep
- // scheduling executors on this worker until we use all of its resources.
- // Otherwise, just move on to the next worker.
- if (spreadOutApps) {
- keepScheduling = false
- }
- }
- }
- freeWorkers = freeWorkers.filter(canLaunchExecutorForApp)
- }
- assignedCores
- }
接着真正开始在 Worker 上启动 Executor:
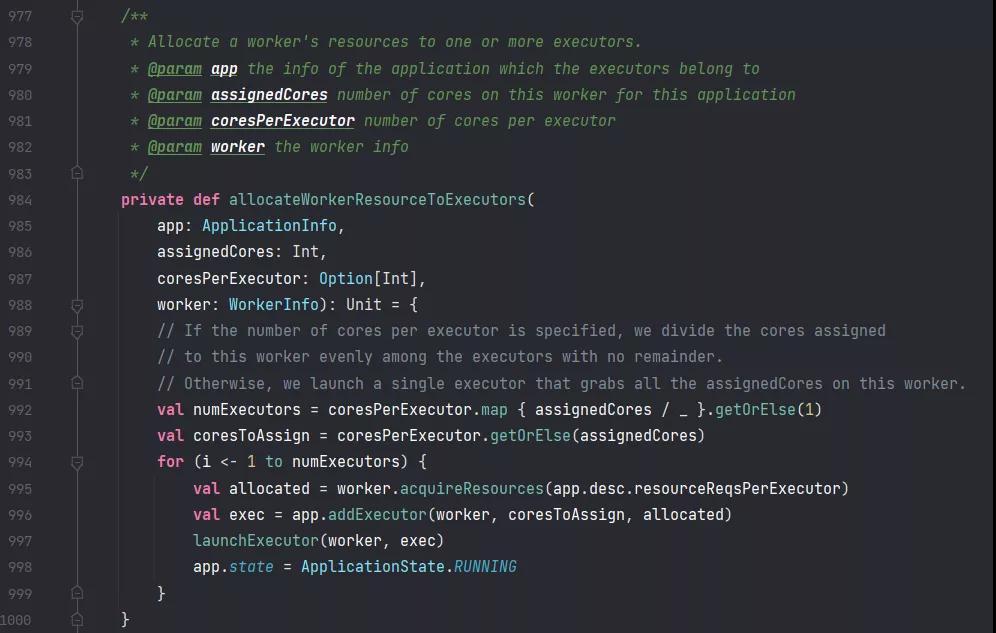
在 launchExecutor 在方法里:
- private def launchExecutor(worker: WorkerInfo, exec: ExecutorDesc): Unit = {
- logInfo("Launching executor " + exec.fullId + " on worker " + worker.id)
- worker.addExecutor(exec)
- worker.endpoint.send(LaunchExecutor(masterUrl, exec.application.id, exec.id,
- exec.application.desc, exec.cores, exec.memory, exec.resources))
- exec.application.driver.send(
- ExecutorAdded(exec.id, worker.id, worker.hostPort, exec.cores, exec.memory))
- }
给 Worker 发送了一个 LaunchExecutor 消息。
然后给执行器对应的 Driver 发送了 ExecutorAdded 消息。
五、总结
本次我们讲了 Master 处理应用的注册,重点是把 app 信息加入到 waitingApps 列表中,然后调用 schedule() 方法,计算每个 Worker 可用的 cpu核数,并且在 Worker 上启动执行器。
















