












【51CTO.com快译】数据科学项目专注于通过使用数据解决社会或商业问题。对于该领域的初学者来说,解决数据科学项目可能是一项非常有挑战性的任务。根据要解决的数据问题的类型,你需要具备不同的技能。
在本文中,你将学习一些技术技巧,这些技巧可以帮助你在处理不同的数据科学项目时提高工作效率并实现你的目标。
1. 花时间在数据准备上
数据准备是清理原始数据并将其转换为可用于分析和创建预测模型的有用特征的过程。这一步至关重要,可能很难完成。这将花费你很多时间(数据科学项目的 60%)。
数据是从不同来源以不同格式收集的,这使你的数据科学项目与其他项目非常独特,你可能需要应用不同的技术来准备数据。
记住,如果你的数据没有准备好,不要期望在你的模型中得到最好的结果。
以下是在数据准备中可以执行的活动列表:
- 探索性数据分析:分析和可视化你的数据。
- 数据清理:识别和纠正数据中的错误。例如缺失值
- 特征选择:识别与任务最相关的特征。
- 数据转换:改变特征/变量的规模或分布。
- 特征工程:从可用数据中推导出新变量。
- 拆分数据:准备你的训练和测试集,例如 75% 用于训练和 25% 用于测试
2.交叉验证训练
交叉验证是评估预测模型有效性的统计方法。这是一项非常有用的技术,因为它可以帮助您避免模型中的过拟合问题。建议在数据科学项目的早期阶段建立交叉验证技术。
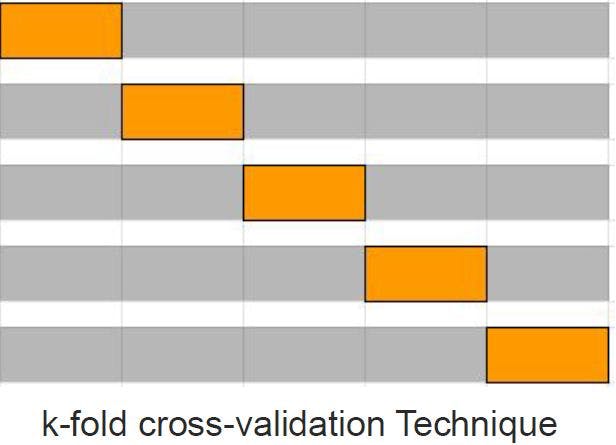
你可以尝试不同的交叉验证技术,如下所述。非常推荐使用 K-fold交叉验证技术。
- 留一 交叉验证
- 留p 交叉验证
- 坚持交叉验证
- 重复随机抽样验证
- k-fold交叉验证
- 分层 k-fold交叉验证
- 时间序列交叉验证
- 嵌套交叉验证
3.训练许多算法并运行许多实验
除了使用不同的算法训练数据之外,没有其他方法可以找到具有更高性能的最佳预测模型。你还需要运行不同的实验(很多实验)来找到能够产生最佳性能的最佳超参数值。
建议尝试多种算法以了解模型性能如何变化,然后选择产生最佳结果的算法。
4. 调整你的超参数
超参数是一个参数,其值用于控制算法的学习过程。超参数优化或调整是为学习算法选择一组最佳超参数的过程,以提供最佳结果/性能。
以下是推荐使用的技术列表:
- 随机搜索
- 网格搜索
- Scikit 优化
- 奥普图纳
- 超视距
- Keras 调谐器
这是一个简单的示例,展示了如何使用随机搜索来调整超参数。
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import RandomizedSearchCV # instatiate logistic regression logistic = LogisticRegression() # define search space distribution = dict(C=uniform(loc=0, scale=4), penalty = ['l1','l2']) # define search clf = RandomizedSearchCV(logistic, distributions, random_state=0) # execute search search = clf.fit(X,y) # print best parameters print(search.best_params_)
{'C':2, '惩罚':'l1}
5、利用云平台
我们的本地机器无法处理大型数据集的训练来创建预测模型。该过程可能非常缓慢,你将无法运行所需数量的实验。云平台可以帮你解决这个问题。
简单来说,云平台是指通过互联网提供不同服务和资源的操作系统。与本地机器相比,它们还具有强大的计算能力,可以帮助你使用大型数据集训练模型并在短时间内运行大量实验。
例如、谷歌云、Azure、AWS等,这些平台中的大多数都带有免费试用版,你可以尝试使用并选择适合你的数据科学项目并可以提供专门服务的试用版。
6. 应用集成方法
有时多个模型比一个更好,以获得良好的性能。你可以通过应用将多个基本模式组合到一个组模型中的集成方法来实现这一点,从而比单独使用每个模型表现得更好。
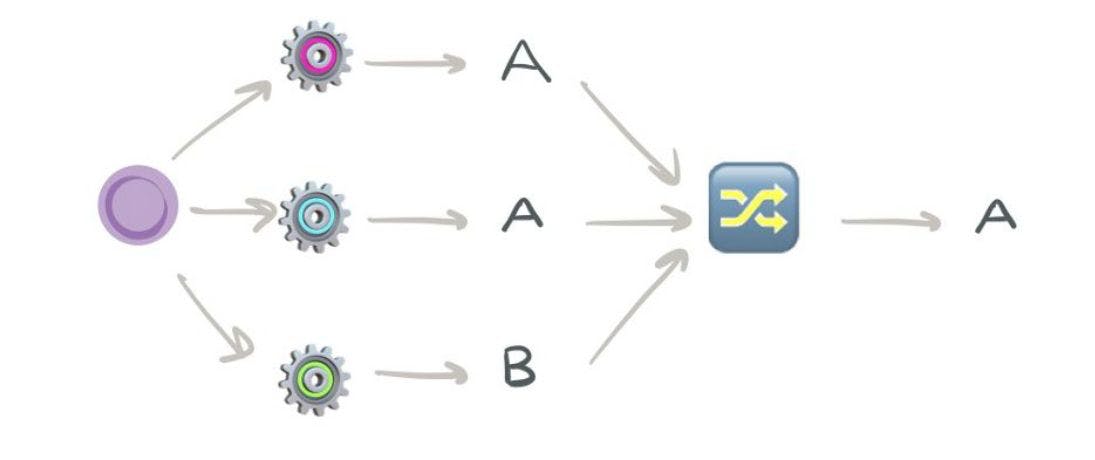
这是一个投票分类器算法的简单示例,该算法结合了多个算法来进行预测。
# instantiate individual models clf_1 = KNeighborsClassifier() clf_2 = LogisticRegression() clf_3 = DecisionTreeClassifier() # Create voting classifier voting_ens = VotingClassifier(estimators=[('knn',clf_1), ('lr',clf_2),('dt',clf_3)], voting='hard') # Fit and predict with the individual model and ensemble model. for clf in (clf_1,clf_2,clf_3, voting_ens): clf.fit(x_train,y_train) y_pred = clf.predict(X_test) print(clf.__class__.__name__, accuracy_score(y_test,y_pred))

结果表明 VotingClassfier 的性能优于单个模型。
希望以上这些技术技巧对你的数据科学项目非常有用。掌握这些技术需要大量的实践和实验,然后才能实现数据科学项目的目标并获得最佳结果。
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】























