













node_exporter 除了本身可以收集系统指标之外,还可以通过 textfile 模块来采集我们自定义的监控指标,这对于系统监控提供了更灵活的使用空间,比如我们通过脚本采集的监控数据就可以通过该模块暴露出去,用于 Prometheus 进行监控报警。默认情况下 node_exporter 会启用 textfile 组建,但是需要使用 --collector.textfile.directory 参数设置一个用于采集的路径,所有生成的监控指标将放在该目录下,并以 .prom 文件名后缀结尾。
所有自定义生成的监控指标需要按照如下所示的方式进行存储,比如我们使用 shell 或者 python 脚本写入的文件:
# HELP example_metric Metric read from /some/path/textfile/example.prom
# TYPE example_metric untyped
example_metric 1
- 1.
- 2.
- 3.
这其实就是一个标准的 metrics 接口内容格式,这里如果没有加上 HELP 信息的话,系统会帮助生成一个简单的描述信息,但是如果有多个文件中出现了相同的指标名称,那么需要保证这些指标的 HELP 和 TYPE 要一致,否则采集会出错。
一般来说输出指标到 .prom 文件的脚本任务会放入到 crontab 中去执行,按照需求设置采集指标的时间,但是如果 node_exporter 采集的时候正好文件在执行写入操作,可能会导致文件出现问题,我们可以将任务先转移到一个临时文件,然后通过临时文件的重命名进行操作,降低风险,如下所示:
*/5 * * * * $TEXTFILE/printMetrics.sh > /path/to/directory/metrics.prom.$$ && mv /path/to/directory/metrics.prom.$$ /path/to/directory/metrics.prom
- 1.
对于 .prom 文件的采集,系统会自动的加入采集文件的修改时间,通过该指标我们可以设置告警用于判断是否文件发生了变化,比如采集指标时间为每 10 分钟一次,那么修改时间应该 <15 分钟,否则就应该报警上次的采集未成功,指标名称为 node_textfile_mtime_seconds,指标收集时间为 unixtime 格式时间。
同时除了加载一些探测信息,使用该方式还可以用于静态信息的收集,比如定义的系统角色信息,或者服务器特殊的配置信息等等,这些也都可以通过 metrics 的方式进行传递。
echo 'role{role="application_server"} 1' > /path/to/directory/role.prom.$$
mv /path/to/directory/role.prom.$$ /path/to/directory/role.prom
- 1.
- 2.
这里我们以官方提供的一个脚本用于采集文件夹目录大小的 shell 脚本为例进行说明,脚本地址为:https://github.com/prometheus-community/node-exporter-textfile-collector-scripts/blob/master/directory-size.sh,内容如下所示:
#!/bin/sh
#
# Expose directory usage metrics, passed as an argument.
#
# Usage: add this to crontab:
#
# */5 * * * * prometheus directory-size.sh /var/lib/prometheus | sponge /var/lib/node_exporter/directory_size.prom
#
# sed pattern taken from https://www.robustperception.io/monitoring-directory-sizes-with-the-textfile-collector/
#
# Author: Antoine Beaupré <anarcat@debian.org>
echo "# HELP node_directory_size_bytes Disk space used by some directories"
echo "# TYPE node_directory_size_bytes gauge"
du --block-size=1 --summarize "$@" \
| sed -ne 's/\\/\\\\/;s/"/\\"/g;s/^\([0-9]\+\)\t\(.*\)$/node_directory_size_bytes{directory="\2"} \1/p'
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
首先需要在 node_exporter 启动程序中指定 textfile 采集器目录,我们这里指定的目录为 /root/p8strain/textfile:
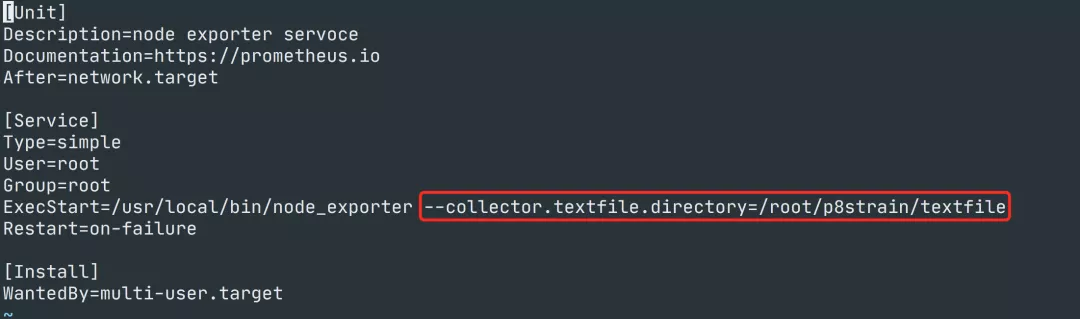
然后重新启动 node_exporter:
☸ ➜ systemctl daemon-reload
☸ ➜ systemctl restart node_exporter
- 1.
- 2.
这样 node_exporter 就会开始去收集我们指定有的 textfile 目录里面的自定义指标数据了。为了使用上面的测试脚本,我们可以将生成的文件放入临时文件,然后重新命令,另外一种方式就是可以使用 sponge 命令来保证以原子方式写入内容
☸ ➜ yum -y install epel-release
☸ ➜ yum -y install moreutils
- 1.
- 2.
将上面的示例脚本保存为 directory-size.sh,放入 /root/p8strain 目录下面,然后在 crontab 中加入如下命令来统计该目录的大小:
☸ ➜ crontab -e
# 加入如下所示定时任务
☸ ➜ crontab -l
*/5 * * * * /root/p8strain/directory-size.sh /root/p8strain | sponge /root/p8strain/textfile/directory_size.prom
- 1.
- 2.
- 3.
- 4.
正常就会在 /root/p8strain/textfile 目录下面生成上面指定的 directory_size.prom 指标文件,内容如下所示:
# HELP node_directory_size_bytes Disk space used by some directories
# TYPE node_directory_size_bytes gauge
node_directory_size_bytes{directory="/root/p8strain"} 459378688
- 1.
- 2.
- 3.
正常该指标就已经被 Prometheus 采集了,我们可以直接去查询该指标获取相关信息:






















